Hi,
I’d like to get from the first to the last picture, but struggle on the last step.

I’m able to create a variable list of cols required and sort them as appropriate (2nd picture).
And create a variable number of cols in same order and append them to the table (green box).

However, I struggle on the last step (highlighted in yellow).
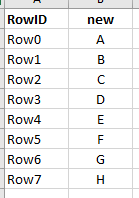
Each of the cols A - H shall indicate if the name of the respective col (e.g. “A”) is contained in the list of elements in the col Affected in the respective row. Once done, I would delete column Affected and keep cols A - H instead. Should be easy, but I just can’t figure out how to self-reference the respective name of the column (e.g. “A”) for the contains search. Any help is greatly appreciated.
Thx, RoBex7
Hello @RoBex7,
for last step you can use Pivoting node but you need dummy column in order to work. Take a look here:
Br,
Ivan
Hello ipazin,
Thx for your swift reply. Greatly appreciated.
Unfortunately, I don’t (yet) understand the idea. I tried to rebuild the workflow (attached), but can’t get it to work. Can you please have a look?
The Patient / Gene example is one dimensional. Every row contains one patient and one gene. My dataset seems to be different. Every row in column Affected contains 1 - n elements.
Br RoBex7
Check if row contains column name.knwf (26.7 KB)
Hello @RoBex7,
there are two approaches you can take. One from above linked topic (I thought you already have needed format for Pivoting node as you mentioned it in first post) and second using Column Expressions node and contains() function together with function which allows accessing column names - columnNames(). Workflow is attached so take a look.
Check if row contains column name_ipazin.knwf (20.8 KB)
I would go with pivoting approach as it doesn’t require coding/scripting and it’s easier to automate. You only need to make sure you always have all possible affected values in your data set. You can do that by adding dummy row with all possible values (A, B, C, D…)
Br,
Ivan
Hello ipazin,
Fantastic. Pivoting is indeed much more flexible and elegant, but I also learned how to reference column names. Slightly different than expected, but it works.
My fault was that I tried to pick the name of columns e.g. “D” as variable or string “D” and couldn’t find it. Instead, one has to refer to the position [index] of the Output Column as listed in the config of the ColumnExpression node as you kindly demonstrated.
On purpose, I screwed up the ordering in the below config of Column Expressions node.
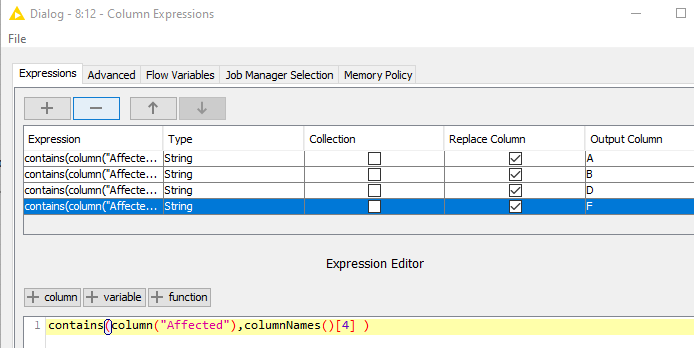
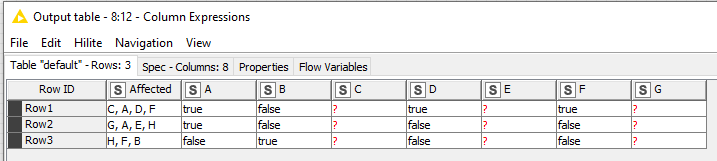
OutputColumn D and F are disordered. To get the correct results for column D and F, one needs to refer to columnNames ()[3] and …[4] respectively, although these columns are no. 4 and no. 6 in the Output table.
Steep learning curve. Thx again.
Br RoBex7
Hello @RoBex7,
glad I helped. However following statement is not correct.
Order of columns in columnNames() function doesn’t have anything to do with expression order and/or output columns. So to get the correct results for column D and F, one needs to refer to columnNames ()[4] and …[6] respectively. You can see this in column F result as they are actually result from D value. If it was value F then you would have true, false, true as there is F in third row.
Br,
Ivan
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.