Is there any way to report (even a closer one is ok) the occurrence of similar sentences in different doc?
My WorkflowProof is: Parser(PDF files)->Bow->Filters->GroupBy->SenExtr->ColFIlter(to exclude the #Terms column)-> as result I have a table with 2 columns: Document; Preprocessed Sent; from this point on I am trying to match sentences by comparing words from multiple doc, but until now I could not find a way.
Any help or suggestion would be very appreciated, thanks in advance,
counting occurrences of equal sentences would be easy by simply using the "Sentence Extractor" node and the "GroupBy" node. Counting occurrences of similar sentences is not so easy anymore. First you have to define in which way sentences are compared to measure their similarity (number of words, number of equal words, considering the order of the words or not, ...) and second you have to define a similarity threshold, above which sentences are considered similar enough to be counted. The way i see it, is that this task is very similar to a clustering task where you want to find sets of similar sentences and than simply count the items assigned to the sets.
You could extract the sentences and convert them into documents (for each sentence one document) and then cluster the documents. For document clustering have a look at http://tech.knime.org/document-clustering-example.
"First you have to define in which way sentences are compared to measure their similarity (number of words, number of equal words, considering the order of the words or not, ...)"
I beg pardon to be so poor of details: I need to measure dissimilarity among sentences counting the # of equal words not considering the order, for multiple pdf doc(a set of approximately 100) where are trated similar topics, and finally see how much they differ each other
"and second you have to define a similarity threshold, above which sentences are considered similar enough to be counted"
How that similarity treshold should be set up?perhaps a pointwise mutual information could be a way?
"The way i see it, is that this task is very similar to a clustering task where you want to find sets of similar sentences and than simply count the items assigned to the sets."
If I understood well, from what I could have seen from the workflow you kindly suggested, I should use a distancematr in order to measure the dissimilarity among the set of similar preprocessed sentences?
thanks for your patience and your help I really appreciate both,
to compare sentences instead of complete documents you could extract the sentences and transform them into documents themselves (Sentence extractor, Strings to documents). You would end up with a table of documents, where each consists only of one sentence. These sentences (docs) can now be processed the regular way.
A good way to compute the distances is provided by the Distance Matrix plugin (Dist. Matrix Calculate node). Transform the documents into bit-document-vectors and use the cosine distance on them. The cosine distance on bitvectors is a normalized set overlap distance. The larger the intersection of the two sets to compare, the smaller the distance.
To speed up further processing filter out all columns but the distance column and the document column. The data table now contains the documents and their pairwise distances. Now you are set to apply clustering on this data, e.g. the K-Medoids node which is working on the distance column. As usual when using k-means / medoids, you need to specify a k which can be a bit tricky, since it affects the result and quality of your clustering. To find a good k one approach is to loop over the k and measure the results e.g. by the inner cluster variance, or the number of assigned documents per cluster.
I am glad to help you, if you have more questions please don't hesitate to ask.
Sorry for my delay but I was busy with my last academic exam...Anyway thanks for your help, very useful as usual.
I read up about the cosine distance usage in hierarchical clustering and that is exactly what I would achieve, that is docs evaluation based on similarity, I think the how-to you proposed is the way, so I tried to follow your advice step-by-step (lighter version of the workflow is attached,I can send you the original by email if needed):
Now with the questions:
Kilian wrote:
"You would end up with a table of documents, where each consists only of one sentence"
After the pre-processing task I have one document per sentence, is there any way to track down and visualize the original document they belong to?Before preprocessing I used columnFilter on the original doc to make the StringsToDocument working well so I lost that information along the process. That would be helpful for final analysis and considerations of sentences similarity among the documents.
Kilian wrote:
"To find a good k one approach is to loop over the k and measure the results e.g. by the inner cluster variance, or the number of assigned documents per cluster."
With Loop over the k do you mean to iterate changing the initial k and comparing results or using loop built-in nodes? And for number of assigned documents per cluster you mean to find which documents are assigned to each of the generated clusters?(e.g. document x belongs to cluster 1, document y belongs to cluster 2, ... etc)
Thanks for all, I am not a programmer and some things are not so obvious for me to understand (just purchased Beginner's Luck to have additional help),
i see the point that it is kind of uncomfortable that the original documents have to be filtered by the column filter to make the Strings To Documents work and thus the connection to the original documents get lost. A possible workaround would be:
Use a Java Snippet node right after the Sentence Extractor and write the RowId to an additional string column (e.g. named "RowId"). In the Dialog of the Strings to Documents node you can specify a column, which values are set as the documents categories or sources. Select the "RowId" column, created before, to be used as Category column. Then proceed with the preprocessing. At the point you want to connect the sentence documents with the original documents use the Document Data Extractor node on the data table containing the sentence documents, to extract the Category from the sentence documents. The node will create an additional column. Then use the Joiner node and join the original documents of the output table of the Java Snippet node to the output table containing the sentence documents via the "RowId" and "Category" column.
About the k medoids:
To find a suitable k for your data you can use the KNIME Loop nodes to iterate over a series of ks and compare the clustering results. Say you want to loop from 1 to 100 use the Counting Loop Start node and specify 100 iterations. Connect the node to the data table containing the documents and distances with the k medoids connected to it. Connect the flow variable output port of the Loop Start node (right click on the node -> "show flow variable ports") with the flow variable input port of the k medoids node. Specify in the k medoids dialog for the for variable "k" (see tab flow variables in dialog) that flow variable "current iteration" is used. I guess the current iteration will start with value 0, if so you need to add a Java Snippet node between the Loop Start and K medoids node which is adding 1 to the value of variable current iteration. After that use the Loop End node, which collects the resulsts of the clustering (maybe Loop End (2 ports) is useful). After execution the output table of the Loop End node conatins the results in terms of cluser assignments of all iterations. Now you can choose which result you like best. One idea would be to compute some kind of target function (e.g. inner cluster variance) based on the clustering results and see which k produces the optimal output.
For the colors, I managed to do it with a little variation on your perfect workaround, replacing the Joiner with categorytoclass node and then colormanager.
For what concerns the k-medoid would it be the same if I use a Java edit variable node (connected via Flow variable ports to the Loopcounter and to the k-med node, with the output column set as "value of currentiteration +1") instead of Java snippet(see the attached mini-flow below, is that correct and in line with what you seggested )?
Kilian wrote:
"Now you can choose which result you like best. One idea would be to compute some kind of target function (e.g. inner cluster variance) based on the clustering results and see which k produces the optimal output."
Could it be possible instead of computing the inner cluster variance function(I do not how to calculate it in knime, I guess with math formula node?) choosing the best Loop result graphically? (I attached k-medoid.jpg, a simple example with k=4 and Iterations=3, the highlighted in red is the collection of k-centers with the smallest within-cluster variation).I tried with scatter plot, but maybe I am missing something..
yes you can of course use the Java edit variable node which makes definitely more sense, since you are editing a variable. I confused the Java snippet with the Java edit variable.
Choosing the right k can also be done via visualization of the results. When you are able to visualize your data in a meaningful way (in this case it might be not very high dimensional, i guess) this can even be better or easier. What i don't understand exactly is that in all plots the same k (k=4) is used by the k-medoid. So you did not iterate over the k, and incremented it in each iteration? The value (+1) of the "current iteration" flow variable can be used as k value by the k-medoids node. In this way you can try different values for k and choose the best result.
The computation of the inner cluster variance can be done with the GroupBy node. Therefore you need to check the option in the k-medoids dialog "Output relative distances to medoids". The output table will then contain the distances of each row to the medoids in separated columns, together with the cluster assignment. Group over the "Cluster" column (cluster assigment) of the first output table of k-medoids and compute e.g. the mean of these distances (or variance, etc.).
I am new to KNIME and had been enjoying working with it.. I am trying to figure out how to convert Sentences that are being spit out from the Sentence Extractor to Document so inturn I can use for classification as my building a classification model that picks up specific types or forms of sentences from a document..you have mentiooned about it in the first reply to this post.. can you direct me how to do that..?
this is a bit of a detour but it is possible. First extract the sentences of documents using the Sentence Extractor. This node will extract sentences as strings. Next, you need to convert the strings back to documents in order to use the text processing nodes. To do this use the Strings to documents node. Is e.g. an index (string column) as title and the sentence string as text. Then you have documents again.
Sorry for the disturb.
I would like to ask some help.
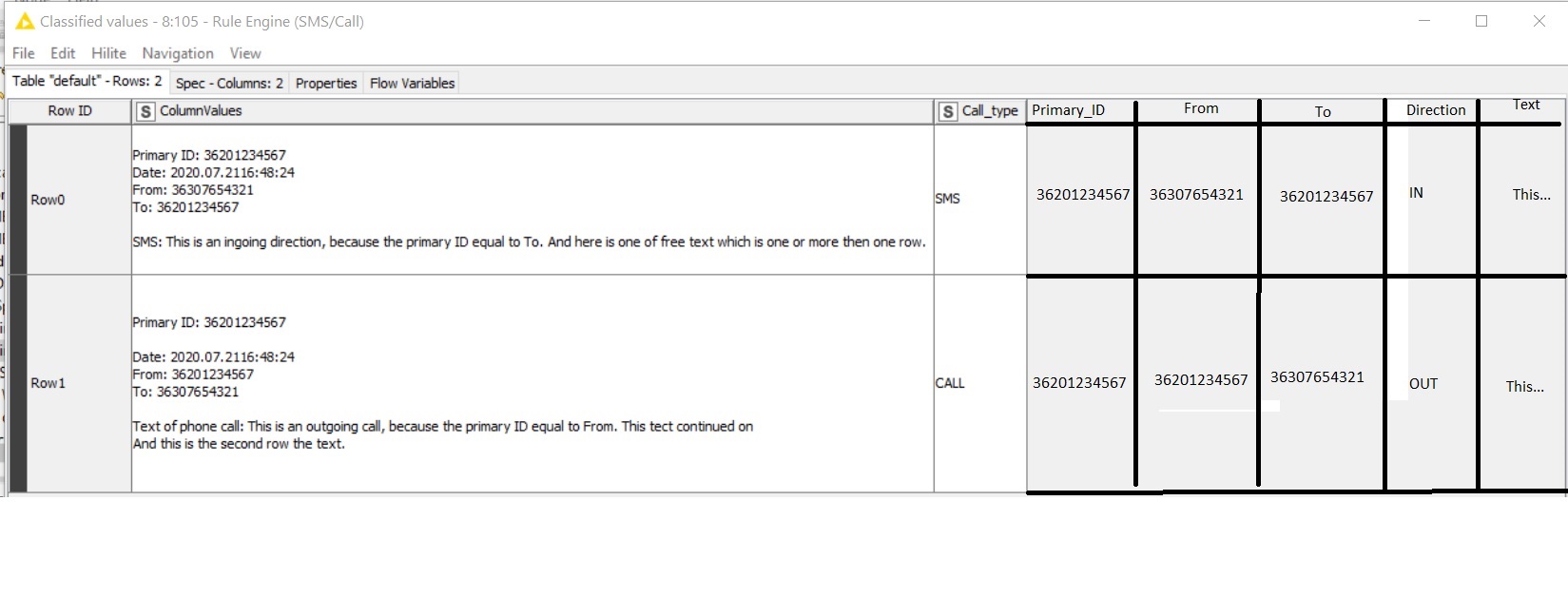
I have some multi-line texts. Every block contains ID, date, text type, free form text, etc.
Because the text is not structured, I do not know how many lines the block contains. I can use One Row to Many, Math Formula, Column Experrion nodes, but is isn’t goog for me.
I would like extract some main information.
Like:
Every first row in ID (I would like to take it in new column).
Make new call directon column (If ID number equal to From then → outgoing, if ID=To, then incoming the direction)
I would like to make two column each of From/To. It contain just the phone number.
If possible, i woulkd like take separated column the text. Text bein from “:”
Unfortunatley I cant find any solution to extract from multi lines rows some main information.
If you give me some help or some usful solution, it was great.