Hello,
I’m creating a prototype to create an auto reference guide.
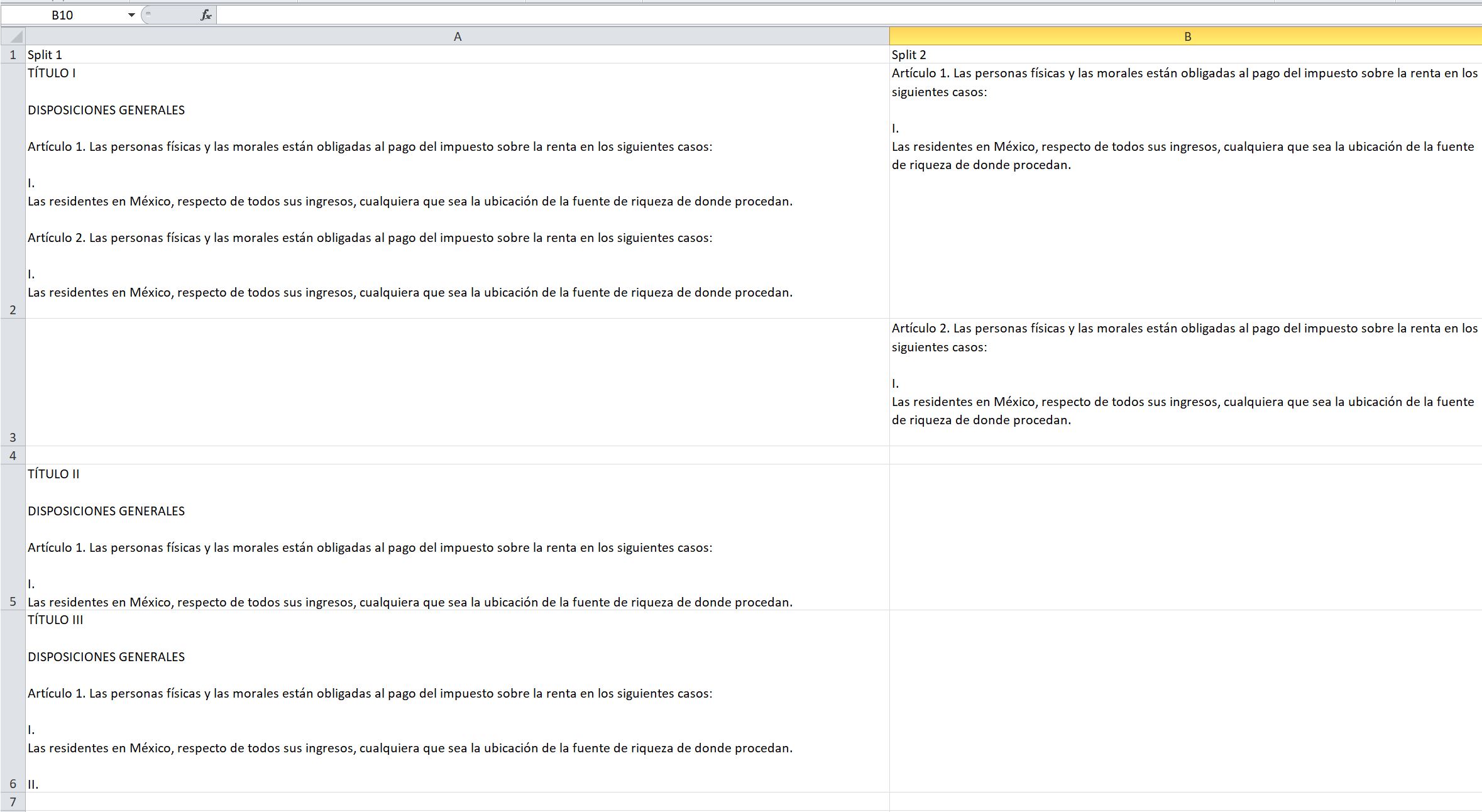
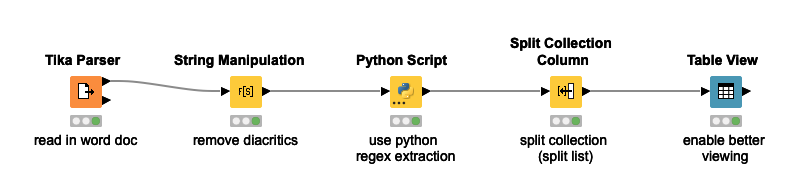
I’m trying to create several rows from a set of (pdf,word,text) documents, I used Tika Parser to load the files.
I found some guides in the forum, but I haven’t be able to achieve the objective. (I tried Palladian, Regex extractor, but it takes long time to respond, I don’t know if it has an option to set maximum number of lines to test and not to try to solve the regex at once.)
The idea is to create multiple rows selected via regex, creating a daisy chain splits to reach the detailed record and be able to update a database.
Then with a backtrack parsing, be able to display the reference. (Not part of the Knime process)
Taxonomy
- Law
- Book
- Chapter
- Article
- Fraction
- Paragraph
*Same philosophy to process WhatsApp multiline messages *
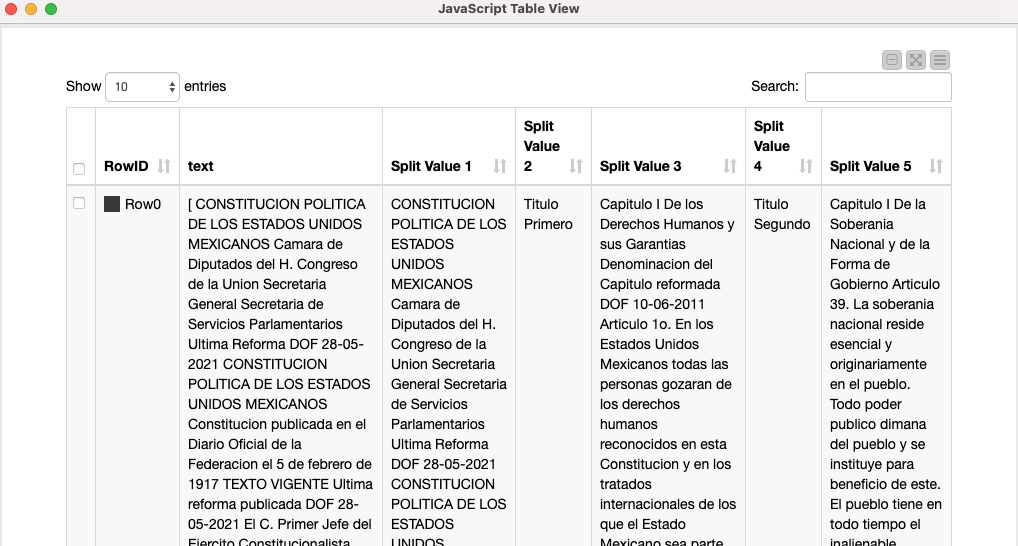
I don’t know if there is an equivalent to the node “Sentence Extractor”, which looks for a PERIOD, to create the row.
I’ve been trying several options, to apply for instance.
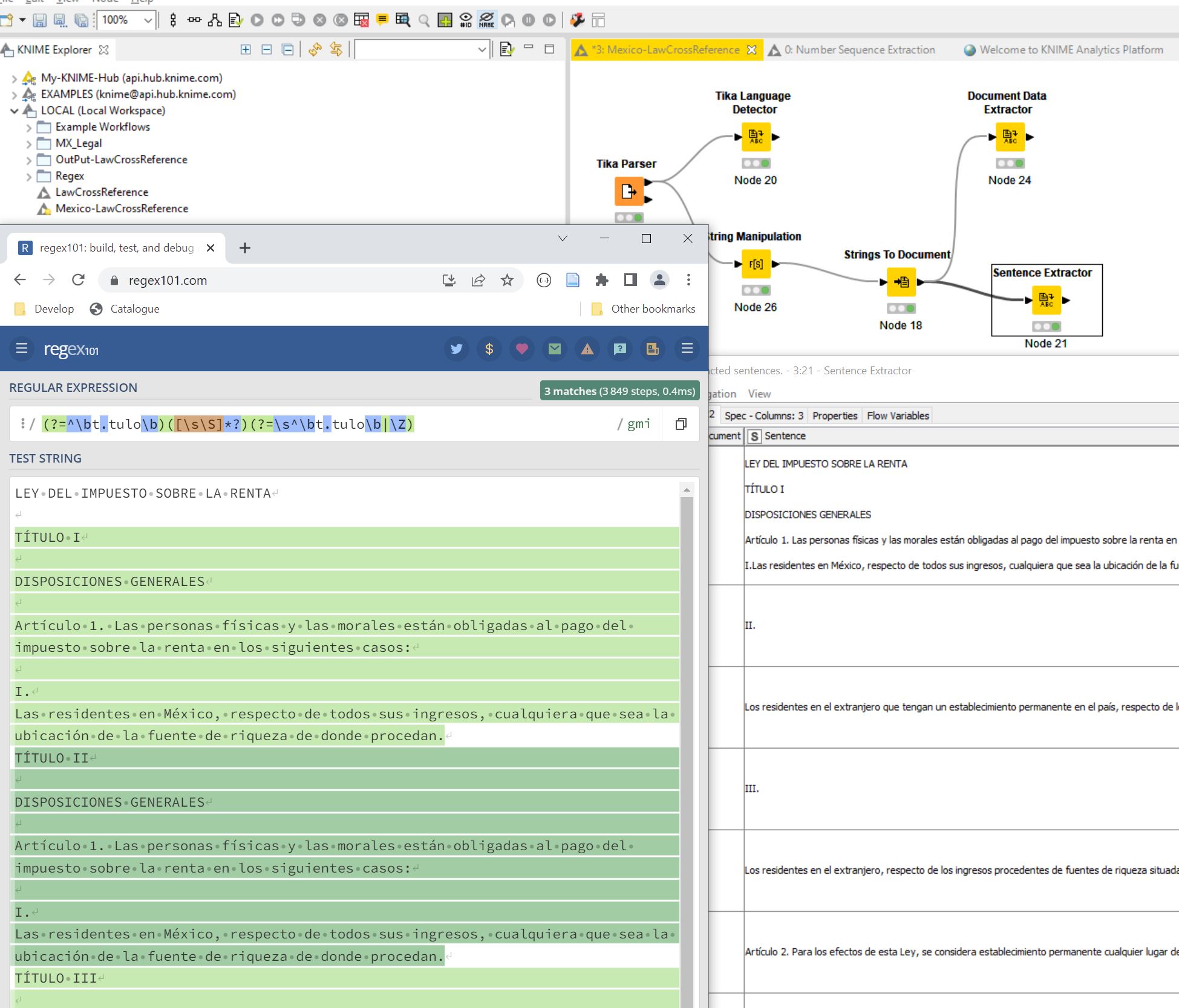
(?=^\bt.tulo\b)([\s\S]*?)(?=\s^\bt.tulo\b|\Z)
Then apply in the next step a split for the chapter and so on.
(?=^\bcap.tulo\b)([\s\S]*?)(?=\s^\bcap.tulo\b|\Z)
A simple way to match and create groups and row. The Node “Regex Split” fails, due it doesn’t work with a multiline selection. (It is my guess).
I know that it is possible to process the files in another environment, (readln … or third party extractors )
Other option is try to hack the node “Sentence Extractor”, and use a regex instead of the search for a PERIOD CR\LF. (It is my guess what the node does to split and create the row)
Any Ideas? Maybe there is a node that I haven’t try.
Illustrative images.
Prototype
Laws

Legal ref
Article, Fraction, Chapter, Law

Other Law Taxonomy Guide - Introduction to Basic Legal Citation