Apologies, I also used the same name as well and then sent you the same file. This time I renamed my file and will show a screenshot to make sure this kind of problem is avoided.
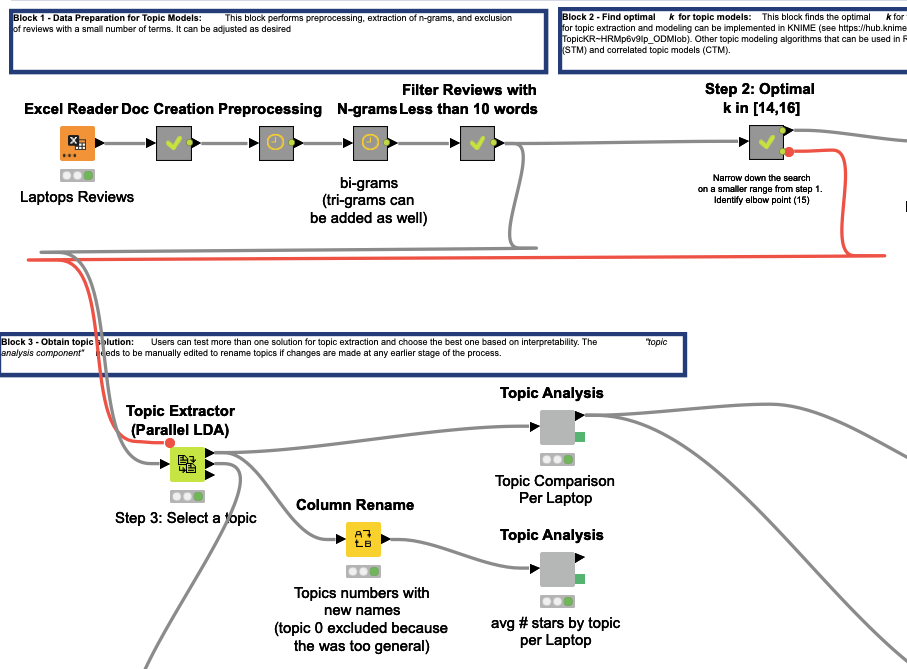
Also, have you tried smaller k just to see if the results lead to better groupings? As in, don’t allow the algorithm to determine the optimal k, but visually inspect the keywords for k = 10, 11, etc. instead of using 15? I remember in your original comments, you said 1 of the topics was too general? Just a thought I had this morning.
Ah! I was checking every node of block 3 side by side to spot differences but couldn’t find any ahaha!
I’ll try to manually set a lower ok as per your suggestion. I originally followed the model and went with what seemed the elbow range to me: very wide in the first step and in the second one I say 2 possible ones, but the one at 15k had a more „steep“ turn so I thought it was the better option.
I’ll definitely try tomorrow by myself and then review everything with the professor who should sign this.
Thanks again, I’ll let you know how it goes!
update: the professor liked the model and, apart from the R part, everything works and it seems to also have a meaning.
The linear regression also makes sense when limiting topics but I was wondering where I could find find more infos about how it’s evalued: It’s like a classic regression model where the greater the coefficient the greater the positive correlation and viceversa? or is it something different?
EDIT: just to be clear, the k i find in step 2 is the Number of topic i have to manually input in the LDA configuration in the 3rd block right? or is it the number of words per topic?
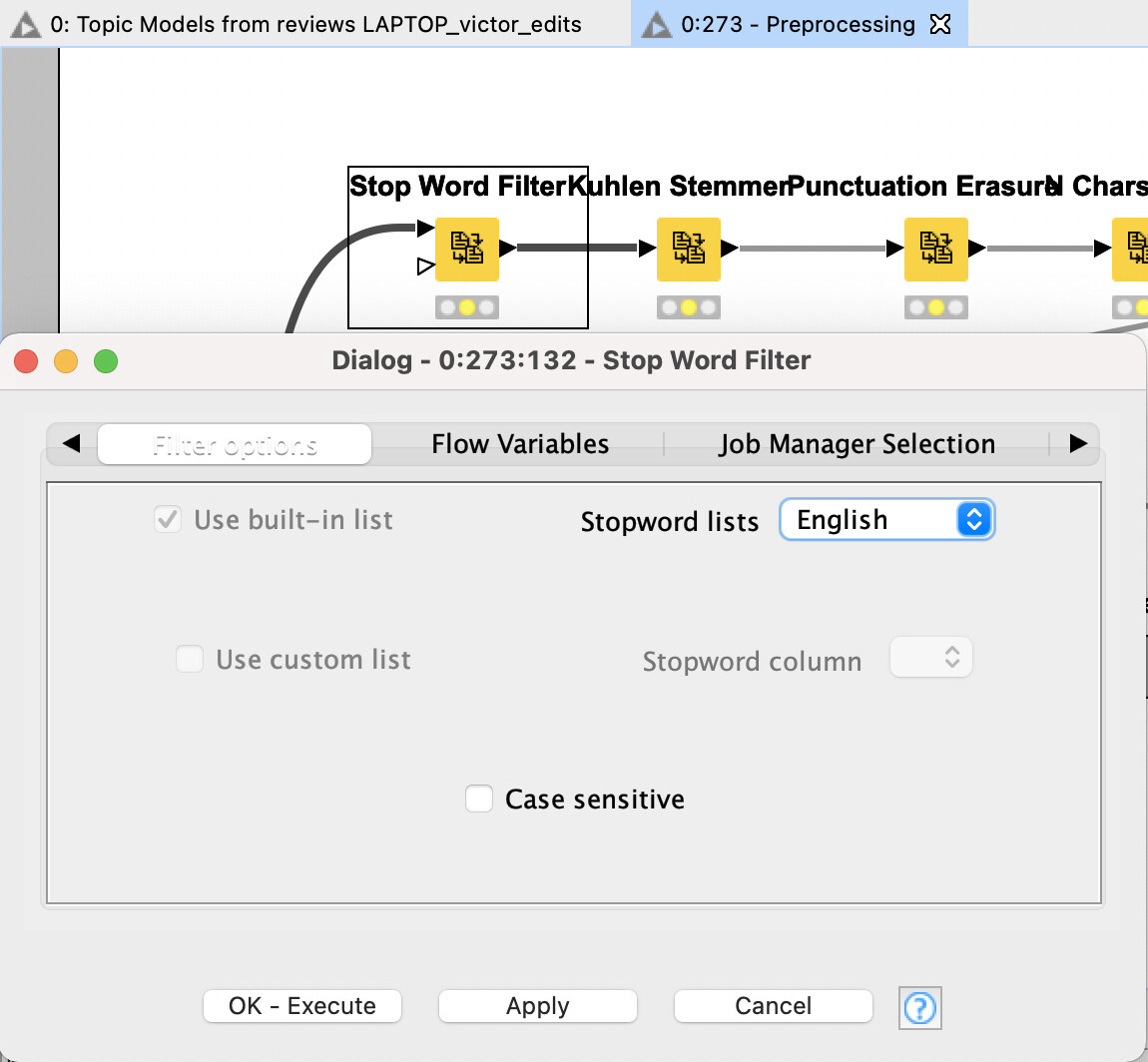
In the workflow I shared I don’t think there are language dependent nodes except the Stop Word Filter within the Preprocessing component. You can change the language there to be Spanish.
But I’m still suspicious about regression though since ratings are not technically numerical. I would say they are classes and recommend logistic regression, random forests, etc. instead. Maybe try linear regression (a regression technique) and logistic regression (a classification technique). Decision Trees and Random Forests can do both regression and classification as well. And then just choose the model that performs best (or is most easily explained by you).
I’ll for sure try your suggested options. I had the impression that my ratings were numerical tho, since I actually see star ratings numbers in that column.
Now I’m trying a different approach and I’ve converted said ratings nto a polarity value of 0 for the negative sentiment (star ratings 1 and 2) ad 1 for the positive (star rating 4 and 5) while discarding all neutral reviews (star rating 3).
Thee idea behind is that for a SME is enough to know if a product was positively or negatively received and which topics were related to said evaluation,
Once 0/1 is your target to predict your goal becomes binary classification and regression techniques cannot be used. (Just in case you want to predict neg or pos).
more than prediction I would like to discover potential patterns.
E.g. if the when there’s the “warranty and return” topic the reviews are mostly negative. Or if “gaming” comes up mainly with good reviews.
But I’m also starting to doubt this part is actually necessary…I’m still experimenting with the other techniques you suggested me.