Hello everyone!
I’m new to this forum and to KNIME in general.
I’ve been browsing workflows on the KNIME website and various topics here in search of something that was closer to what I have in mind but to no avail.
I’m working on a school project about how Sentiment Analysis could be applied to the small enterprises field and my idea was to run a model that would analyze amazon reviews on an Entity and Aspect level (as per Bing Liu definition in his “Sentiment Analysis and opinion mining” book) to classify what features of various products were liked by customers and what not.
I come from a business background so I’m not versed in Machine Learning and I hoped the No-Code environment of KNIME could facilitate this, but I’ve yet to find a workflow that could adapt to my goal or even some tutorials on how to build one.
I hope somebody could point me on the right direction.
Best regards,
Andrea
There a number of sentiment analysis workflows that may inspire you or be exactly what you are looking on the KNIME hub.
If none of those example workflows does what you like, could you restate your question and provide a concrete example of what you expect as input and what you expect as output (with a descriptive list of input variables/columns/features (these words are virtually interchangeable in machine learning). Thank you!
I’ll try to brwose the HUB thanks.
The dataset I’m using is comprised of 3 columns:
-polarity: the values here can be either 1 (for reviews that had either 1 or 2 stars) or 2 (a score of either 4 or 5 stars), revies with a value of 3 were eliminated.
-title: a text which is the actual title left for the review
-body: the actual text body of the review left
My idea was to train an alghoritm that could recognive the “sub-topics” in the body column (e.g. the review might be about some headphones and in the text the reviewer could point out negative/positive aspects of single components of them "bad construction, good sound quality etc. etc.).
So I would need something to cut the body into different sentences and then recognize the subject and the related “subjectivy/opinion words”.
I see, this sounds a lot like topic modeling. Here is a workflow from our Text Processing Course (L4): Topic Detection LDA: Summarizing Romeo & Juliet or cataloging News – KNIME Hub
There is also a very beautiful workflow on the KNIME Hub for that topic with respect to marketing made by a professor in that field: Topic Models from Reviews – KNIME Hub
Let me know if that helps.
A lot! Tomorrow I’ll try to make it work with my dataset, but this seems exactly what I was looking for.
If I understood correctly, after recognizing different topics in the sentences, it assigns a “polarity” value based on the overall score of the review right?
Thanks again for the help!
Unfortunately, topic modeling does not assign polarity. Binary classification predicts (not assigns) polarity if it is the target variable (i.e., what you are predicting). I think you will find the problem you presented requires a deep understanding of the following topics in machine learning:
-
Binary Classification:
Your input is text/title and your output is polarity. If you wish to predict polarity, you must learn this topic. -
Natural Language Processing:
To perform Binary Classification using text or Topic Modeling you should know about Natural Language Processing to get the data in a format that a machine learning model or a Topic Modeler can use. This is very large subfield within Machine Learning and we offer a dedicated course just for this - that is how vast and complex the techniques are for this subfield. -
Topic Modeling:
Figure out the subtopics. Topic Modeling is a sub-sub-topic (forgive the pun, it was not intentional) within NLP (natural language processing).
I think when you say “classify what features of various products were liked by customers”, you are talking about several layers of machine learning (including all the topics I stated above).
You would use topic modeling to get the data in a way that finds out what your topics are. Then you would use the polarity score given to you to see which topics are mostly positive and which are mostly negative. For this, you do not need Binary Classification.
On the other hand if you just want to predict polarity, you don’t need topic modeling at all.
In all cases you will need a firm grasp of NLP though.
I see. Sounds a lot more than what I’m required to do (effort wise) for my school.
I’m expected to write about an EASY application of Sentiment Analysis to a small medium enterprise.
And the easy part is fundamental cause I should also demonstrate that this could be done by anyone (even me) with little experience thanks to the NOCode support of KNIME.
Maybe I should recalibrate my goal and find something else?
Could I maybe try to go back to polarity prediction?
But then wouldn’t that be irrelevant for a Small Medium Enterprise? What is the use to predict polarity when you can simply filter reviews by their star rating?
Thanks again for all the help!
What about focusing on Twitter sentiment instead. So what do people say about a company or it’s product.
The Twitter API can be used for free and there are a lot of examples out there as this is done pretty often
br
That was the initial idea, but I discarded it since my target was the SME and they don’t have much “social presence”. Even if one could say that SME could monitor similar products from bigger companies and see what works and what not…so this could be a good option.
I also haven’t discarded yet the topic modeling option: what if I split the dataset between positive reviews and bad ones (by star rating) and the I apply topic modeling separately to find what are the topics in both datasets?
Wouldn’t that be insightful?
The problem here is that I already registered the title as “sentiment analysis for the SME” so I’m not sure if only using topic modeling would be too much of a stretch.
Again thanks a lot for the inputs! Tomorrow I have to discuss options with the professor who has assigned me this and I’ll see what he thinks about all of this.
I personally would change the choice to pure topic modeling because I think it would be insightful to look at bad reviews and specifically identify what the customers don’t like about a product without having to read millions of reviews manually.
It’s exactly what we agreed on with the professor.
Now I’m trying to make the tripAdvisor workflow you linked me work with the databases I’ve found.
I’ll let you know how it goes, thanks!
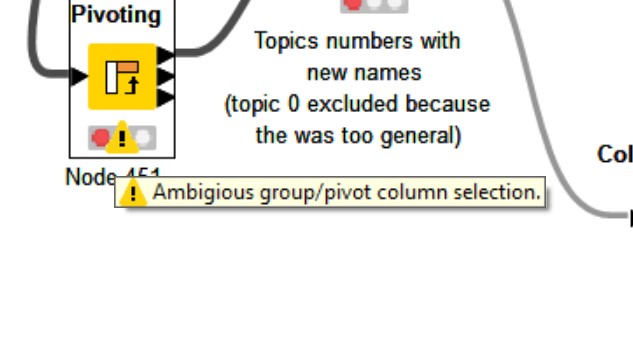
I’m having a little problem with the pivoting node in the 3rd block of the workflow. I imagine the goal there would be to pivot the average star rating to the assigned topic that the LDA assigned to each review, but when I try to do that the node it doesn’t work.
I tried different selections like it’s shown in pictures below:
Could you post the workflow as well? If you have sensitive data, you can use the table creator node as input with fake (but similar) data. Thank you!
Sure!
updated.json (364.7 KB)
It doesn’t let me upload directly the dataset so here it is:
and the workflow for good measure:
I have solved the Pivoting issue but I still can’t make the whole model work.
So far I seem to get coherent topics from the LDA at least.
Did I export the model in the wrong way?
Hi @Andrea123 , sorry for the delayed response. I meant if you would post the KNIME workflow (How to import and export KNIME Workflows - YouTube).
This is a .knwf file (see image) and you can upload it directly to here without using third party systems. As well, the node causing you issues it the pivot node, correct? Once I see the KNIME workflow, we can address the issue. Thank you!

There’s no hurry! Thanks for the reply: I guessed I exported it wrongly when I tried to run the model on my laptop!
Anyway here is the .knmf file:
Topic Models from reviews LAPTOP.knwf (1.7 MB)
The Pivot problem is already solved (I just had to tinker a bit with the node configuration).
It’s from that point onwards that the model stops working. In particular the 4th block where I should evaluate results isn’t functioning.
Thanks again for the support!
Topic Models from reviews LAPTOP.knwf (1.7 MB)
So the model seemed to work for the native knime node and as for R, do you need to use that? I don’t use R, so you would have to ask for help in a separate thread related specifically to whatever issue you encounter there. As for the Linear Regression node, is that appropriate for your problem?
For the topic modeling, the second node was not working so I fixed that, but the visual you were trying to create had too many computer displayed at once, so the visual wasn’t useful. You’ll have to be picky about what you visualize since you have so many laptops.
I also made a change adding a flow variable so that you don’t have to manually select k in your third block.
Finally, I think the random seed generated different topics for me, because the labels you assigned seemed a little mismatched so you may want to double check that.
Have a look at how Machine Learning models are usually checked and done:
Thanks for the corrections!
I’ll check the link you posted and discuss, tomorrow, with my relator wheter I should use Linear Regression and R.
The labelling seemed coherent on my model, albeit for some of those I also wasn’t sure…I’ll definitely check again.
As always, thanks for all your help!
Just a question tho: you said that you changed a flow variable in the 3rd block (I assume in the LDA extractor right?), but how come I see no flow variables or no differences whatsoever when I imported it?
Where should I check exactly?
I imported the file through the import workflow command and had to change the name cause I already had one with the same name on. They look identical to me.
(It’s probably just me being dumb and not knowing what/where I should search ahah)