I would like to set up a workflow for classifiying patent documents as relevant/not relevant regarding certain technologies or processes. Basis for the classification should be the set of claims. In many documents (especially european patents), the claims appear in more than one language, mostly English, German and French, at the same time in one document. My question is: Is it possible to separate for example the german, english and french text blocks from each other so that hey could be furtherly processed by a separate workflow branch or s separate workflow ?
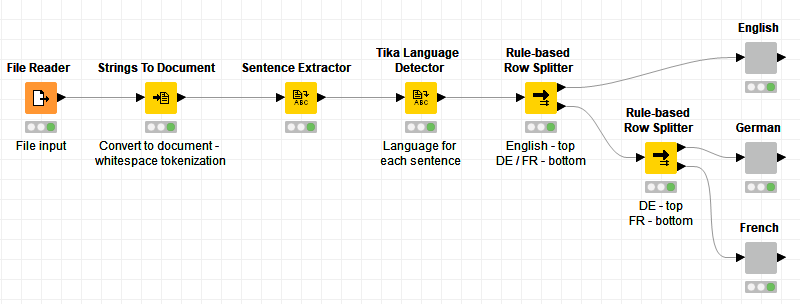
That’s an interesting problem! Our existing nodes that detect languages (Tika Language Detector and Amazon Comprehend (Dominant Language)) do so for either strings or documents, but for the entirety of the field that is input. So one approach might be:
first convert your strings to documents (using language independent whitespace tokenization)
thanks a lot for your answer and advice. I tried according to your model workflow using an input which contains English, French and German language. For test purpose, I used only one document, a set of patent claims in all three languages. Converting to Document with whitespace tokenization works. The sentence extractor provides an output table with sentences in all three languages. Unfortunately, the Tika language detector doesn’t seem to work properly in my case since “fr” is allocated to all sentences. Do you have an Idea, what could be the reason (for example, the sentences still contain numbers and at the same time some technical (chemical) expressions) ? As far as I can see, the rule based row splitter also works properly.
I have one remaining question: After „stripping off“ unneeded languages, is it possible to put together the sentences again giving a document ? Or isn‘t that necessary for further processing towards machine learning ( the identity and content of the document should be retained).
I suppose it depends on what your ultimate goal is on the machine learning side. All of the metadata associated with the original document is still retained, and you can create explicit fields for that meta data using the Document Data Extractor node.
The Sentence Extractor produces strings, so you could always join them back together (minus the sentences of other languages) to create a new, cleaned document.
But the question remains: what is your ultimate goal with the cleaned data? Is it classification, or topic extraction, or…?
my ultimate goal is to classify the documents. I manually identified a number (several hundred) of patent documents to be relevant regarding to a certain technology I’m interested in. Those documents,I would like to use to train a model.
Using the trained model, I would like to classify unkknown documents. I would prefer a predictor which provides as output the relevancy in terms of a value between 0 and 1 (for example logistic lerner / predictor ?) for each document.
Since I’ new to data science and knime, I search for the beginning for a model which is not too complicated to parameterize… Could you give me a hint which model to try ?
it seem, I’ m not able to combine my extracted sentences back to documents. I tried the strings to document node. Ist that correct or is ther any other way ?
Sorry for the delayed response here. As for which algorithm to use, you might try a simple Decision Tree or Random Forest - both are fairly straightforward to parameterize. We have examples on the Hub that cover both text classification tasks and parameter optimization for these nodes.
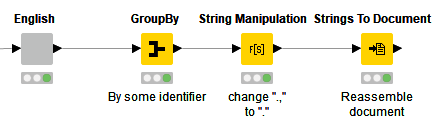
For combining extracted sentences to documents, you can use the GroupBy node, grouping on some identifier unique to each document, with the Concatenate aggregation. This will generate a long string consisting of sentences in your document separated by commas. You can then do a quick adjustment on the punctuation using a Replace function in the String Manipulation node (or don’t, if you just plan to strip it out later). Then use the Strings to Document node to reassemble the document consisting of only the language you want to process:
thanks for your hint. I used the group by node as you described and it worked. Meanwhile, I also was going through the book “From Words to Wisdom” and I was able to test classifying using a decision and a random forest learner/predictor. With the default settings of the models, approx. 91 % of the documents are classified correctly. Now, my goal is not to achieve high accuracy, but rather to reduce the number of false negative classifications, therefore accepting a higher number of false positive classifications. For example, if I have to review 10.000 documents manually, It would be very helpful to reduce that number to 2.000 by a classification model even if 1.000 of them would be classified false positive. My question is : Is there any way or model which allows to lower the “treshold value” of positive classification ? Ideally, the classified documents would contain a certain amount of false positive, but no false negative classifications…
Also, if you have a binary classification problem, the Binary Classification Inspector node in KNIME Labs will allow you to set the threshold using a slider while reviewing the confusion matrix and ROC curve. It’s really nice.