Hi @michael19602016 -
That’s an interesting problem! Our existing nodes that detect languages (Tika Language Detector and Amazon Comprehend (Dominant Language)) do so for either strings or documents, but for the entirety of the field that is input. So one approach might be:
- first convert your strings to documents (using language independent whitespace tokenization)
- extract sentences from those documents
- detect the language of each sentence
- branch based on the language
- continue analysis downstream
A dummy workflow might look something like this:
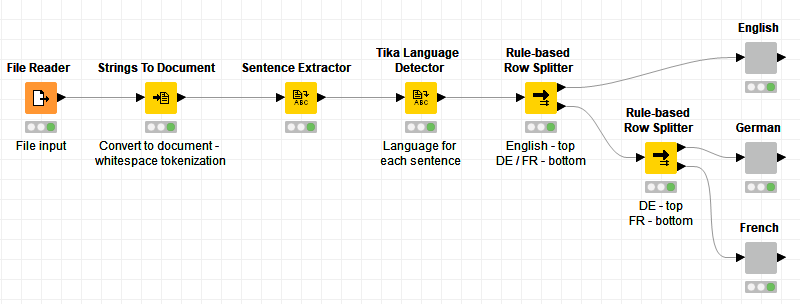
Does that help get you started?