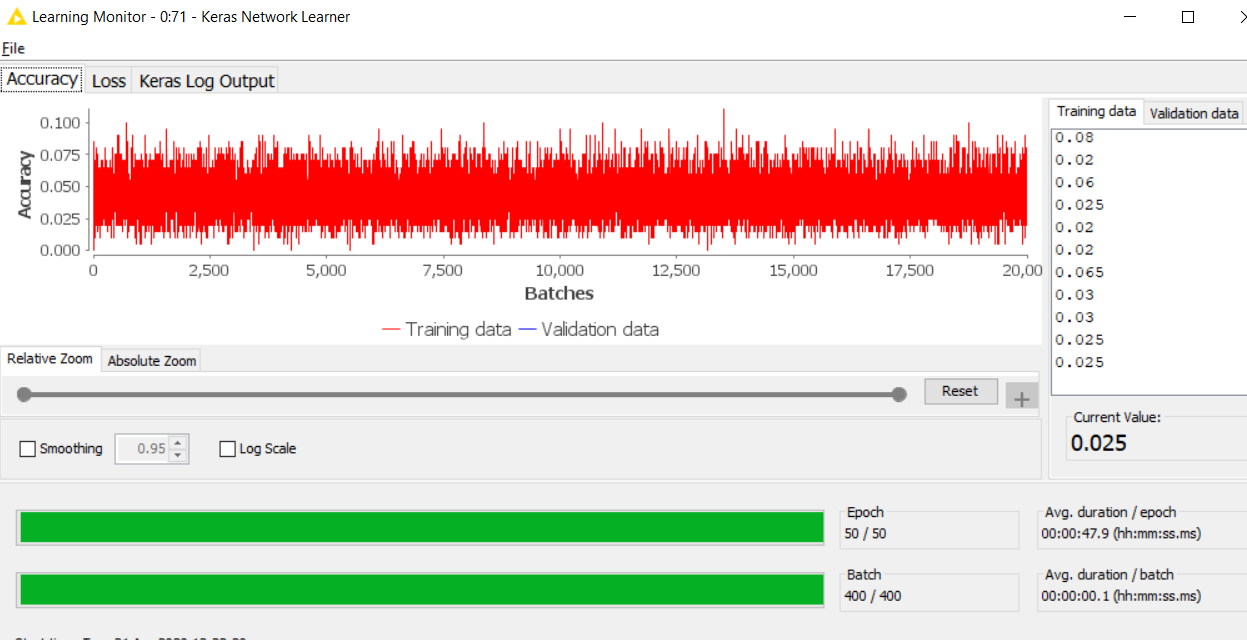
When I check the model via the Keras Network Executor with unseen data I find that it is doing pretty good with predicting the outcome in spite of the Keras Network Learners very low accuracy.
I guess that brings me to the question of how the Accuracy on the Network Learner is defined and if I can set that without affecting the model negatively.
The accuracy values are directly obtained from Keras. In general, accuracy is only useful for classification tasks as it calculates the fraction of how often predictions match labels. Your application looks more like a regression task, is that correct? We should probably allow users to select a metric that is suitable for their task instead of always displaying the accuracy.
Note that, unlike the loss, the accuracy is not considered by the learning process, i.e., the model is not being optimized with respect to that metric. So if the performance of the model is sufficient on the test data, you might as well ignore its accuracy during training.
If you are interested in the details: the way the accuracy is computed depends on the loss function you chose (binary, categorical, etc.). The different accuracy implementations are defined here (source code). The metrics further down in the file (mean squared error, etc.) are the ones that you would typically use for regression.
I am not very sophisticated when it comes to my approach to Machine Learning. I am trying to learn everything at the same time.
Up until you mentioned it, classification only seemed like a simpler version of a regression problem. In the one case the answer is only being interpreted by some additional ‘step’ function.
Would that be a true statement?
I am still working on the underlying mathematic, but it is nice to approach it from two or three ends.
How is accuracy generally measured in regression problems and would I need to build some simple math function to do so?
In practice, this is often true. The key observations here are that regression outputs continuous values whereas classification outputs discrete values. And that you can always discretize continuous values.
Whether some sample is a member of some class is often specified as a continuous probability, particularly in neural networks where usually a final softmax layer outputs a probability distribution over all possible classes. These probabilities can than be discretized by picking the most probable class as the sample’s class. Another classical example that is closely related to softmax would be logistic regression, which is used for classification tasks (despite its name).
But the above is not generally true in theory – and, at least conceptually, I would treat classification and regression as different tasks. For instance, think of this very simple rule-based system that classifies whether it is warm outside today or not:
Is it more than or equal to 20°C? → Yes
Is it less than 20°C? → No
As you can see, there are no continuous values involved in the system’s output. The possible outcomes do not even have a numerical representation (let alone, interpretation). You could of course introduce regression here (and maybe even achieve more precise results this way, like “it is not really warm but also not really cold”), but conceptually it is not required.
I hope this proves somewhat useful to you. My answers are in no way exhaustive or as precise as one can get, but your question opened up quite a broad field .
You would typically use estimators like mean squared error or mean absolute error that assess the quality of an estimate based upon its numerical difference to the actual value. This is, by the way, a further key difference between regression and classification: in regression, there is a meaningful distance measure between values, in classification this is generally not true (e.g., when classifying pictures of animals, is dog more similar to cat than mouse?).
If you want to use one of these estimators during training of the Keras model, you would currently need to resort to Python scripting via the DL Python Network Learner node and compile your model accordingly. Doing it after training is easier. Here you can make use of the Numeric Scorer which you feed the values output by the network executor node, along with the actual values.