In Databricks notebook we can use %scala in Python notebook and the value can be authentication can be configured but we don’t want to use the notebook in between. I am planning to use PySpark node instead of notebook.
My concern is how to set the above scala code inside the PySpark node.
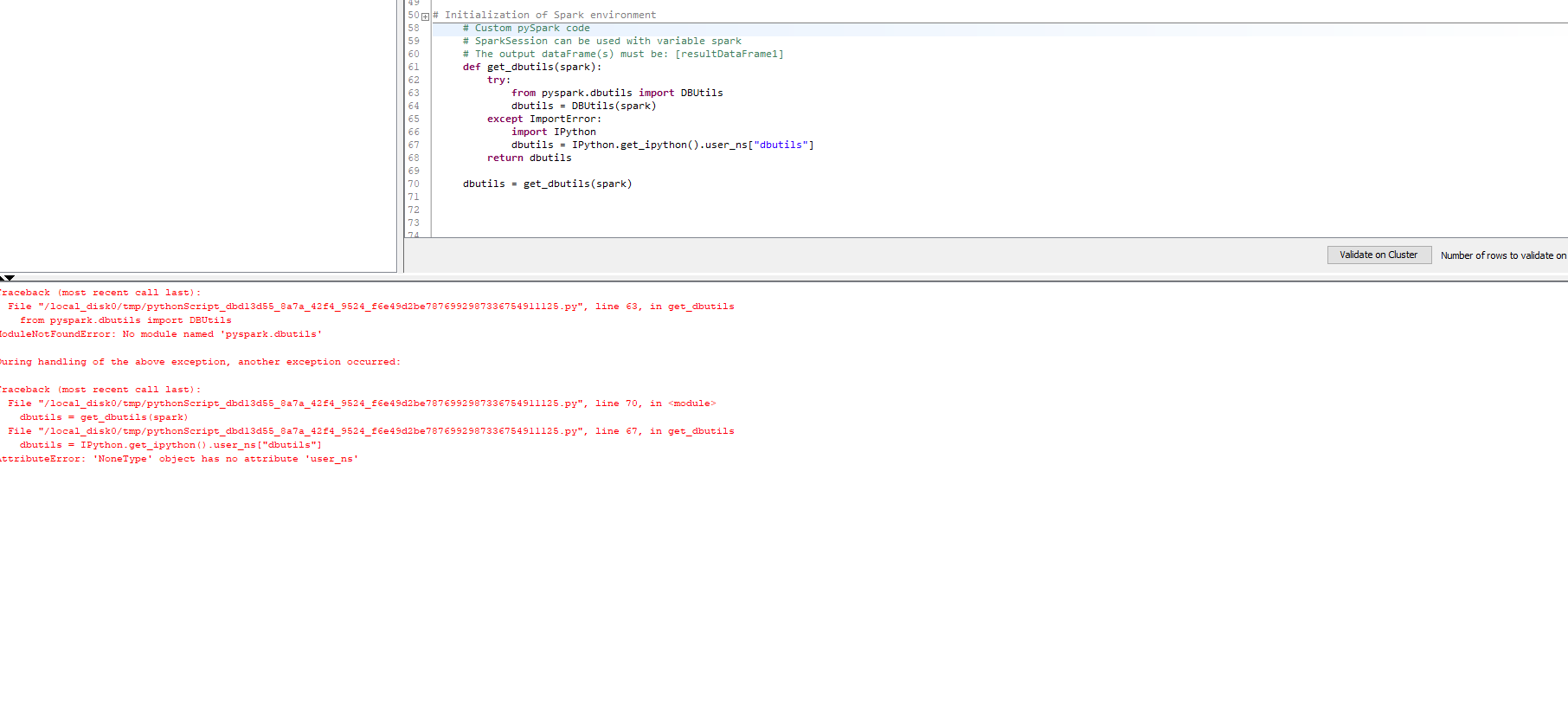
The dbutils module is not a standard part of pyspark. Instead, it is made available through the databricks-connect module which supplies its own version of pyspark augmented with its own special, Databricks-relevant capabilities. It is non-obvious when users are instructed to type code like from pyspark.dbutils import DBUtils (also advocated in the Databricks Connect documentation), but the assumption that DBUtils comes from pyspark is incorrect – it comes from the databricks-connect module co-opting the pyspark name (and much of its code).
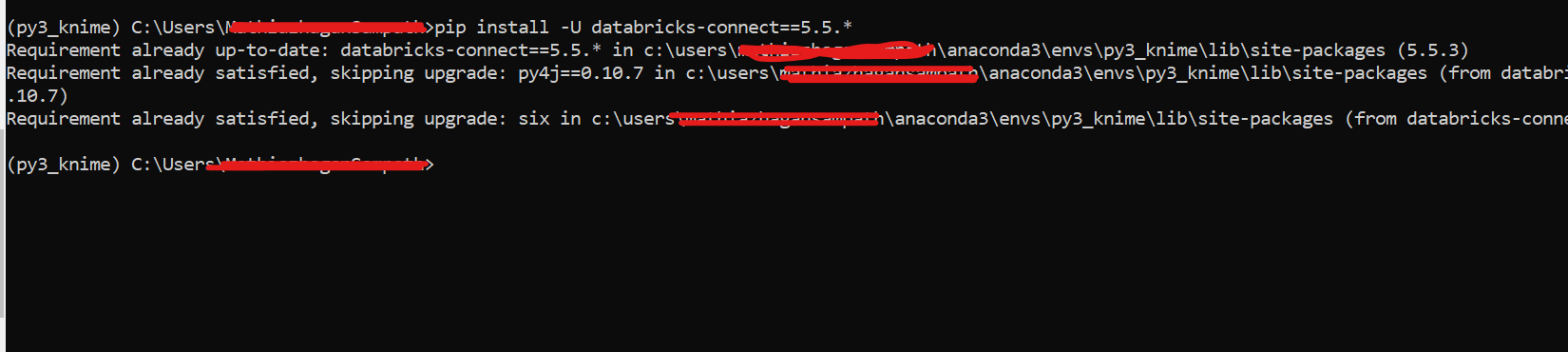
Do you have the databricks-connect module installed?
I suggest: verify that you are using the same conda environment (you appear to be pip-installing into a local conda env named “py3_knime” on a Windows system) in your Spark cluster (which appears to be Linux) where your Python code will actually run.
In a local conda env, I installed databricks-connect==7.1.1 against Python 3.8 and in the local Python shell I could successfully do the following: from pyspark.dbutils import DBUtils
In a different local conda env, I installed databricks-connect=5.5.3 (like you have installed on your Windows system) against Python 3.6 (because 5.5.3 appears to not fully support 3.8) and again I was successful with the same import of DBUtils.
As to where your Spark cluster actually is or what installation of Python it is using, I have no insights other than the clue that it appears to be on a Unix system based upon the filepaths captured in one of your screenshots. On a DataBricks Spark cluster, I believe installation of databricks-connect is part of the DataBricks installation instructions – I mention this because connecting to a Spark cluster but not a DataBricks Spark cluster could lead to some confusion.