Apologies for the semi-repeat post however I have read through many posts (many on old versions) and applied what I have found to little effect.
Scenario:
4 main data sources - 2 excel files, 2 tables on sql server
Large workflow - Just over 1,000 nodes
End dataset - 350k rows, 56 columns
Total Time to process - >4 hours
Longest node to run - 87 minutes (Joiner: Left outer join)
Hardware:
Windows 10 VM on Azure
Intel® Xeon® Platinum 8272CL
32GB RAM
Have experimented with the Knime.ini configuration and is currently set to use 18GB and 1m cellsinmemory
KNIME has been updated to the latest release
The data is all transactional sales data from 4 different systems which need to be transformed before being combined with additional joins from other smaller ‘dictionaries’ such as FX rates etc.
The longest node to run is a left outer join with the left table being the sales data (350k rows), and the right table being all the UK postcode prefixes (3k rows, 3 columns). This is done in order to validate which prefixes in the sales data are valid (most of the data comes from 2 of the systems without built in validation, also need to add cities to all of the data).
Additional long running nodes are all joins, again with the 350k left and anywhere from 300 to 18k on the right. These include joins from a pre-downloaded dataset from Companies House (only records that we are matching to) and SIC lookups from the codes from Companies House.
My thoughts:
Do I really not have enough computing power to handle these joins quickly? I never seem to fully max out on RAM usage.
I could re-work my workflow to apply the joins to the subsets of data before they are concatenated, but is this that much more efficient if they are potentially running at the same time anyway?
Is there a method more efficient than using Joiner for this?
then you could try and force the join node to do everything in memory and see if this is getting any faster
then if a workflow becomes very large it tends to use more RAM. It might help to split it into several workflows and maybe call them from a parent workflow (no guarantee there - and of course the effort to rework the whole thing) - you could try with you two largest join files to see
use the garbage collector to free memory
you mentioned Azure: is this some virtual server? I sometimes had the impression that virtual or shared drives over networks make for poor KNIME performance. Local SSD fare much better. If this is the case caching again might be an option
you would have to see if caching is better to be done on disk or in memory. Memory might be faster - but there is always a price to pay
make sure you do not join large numbers of missing (or dummy IDs or something) against each other. That would also take more time
complex strings could also be a problem
I have thought about but never tried to build a reference file with numbers to my string IDs. Then join the numbers to each file and then join by numbers (that might be more costly than just living with the longer time) but combined with other approaches it might be a measure of last resort
And well if everything else fails. You could try and employ a larger system or a database. Or you could try and see if the SQL server could handle some joins.
You asked for speed but one more experiment could be to use Hive and the local big data environment. In theory Hive should be able to at least finish the job. But that would be more of an issue if your job would not finish at all.
OK since we are at it here a historical collection of entries about performance and KNIME
I’ve started to split my data before joins to remove the missing values from going through the join, and then concatenating back afterwards, this seems to help a lot (would be nice if the join had it’s own built in logic to do this, I guess I assumed it would skip those rows, although I guess it works much like an Excel lookup)
Once I’ve completed that process, I will look at seeing if I can simplify some of the steps and break the workflow up into subworkflows and adding in some of your other recommendations.
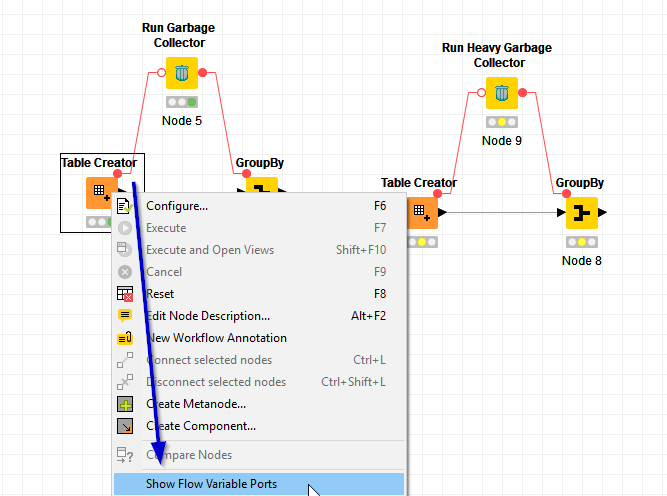
Regarding the garbage collector, how am I meant to utilise that?
Glad you like the information. If you consider using a call workflow scenario that comes with some quirks. I have tried to set up such a scenario. You might have look:
In general you will have to do some trial and error to get a feeling what is best for your task and plan ahead with the reduction of workload for the system in mind. From my experience the combination of Cache and join in memory (wahtever combination fits best) could help a lot.
You could just use the flow variable. There alse seems to be a ‘heavy garbage collector’ - also some configuration is possible. Maybe you read about that in the description.