I’m really new to Knime and to data analytics in general so sorry if my question is not very clear.
I have a data set of users as rows and the features they have access to as multiples binary columns (1 if the user have access to the feature, 0 if he hasn’t).
I have about 3000 rows and a little more than 120 binary columns. I would like to measure similarity between each users based on the features they have or don’t have in common. Then I will regroup them by similarity to create clusters.
I saw the various clustering node available on knime, like Hierarchical clustering but I’m having trouble computing some sort of similarity matrix prior to that to feed it as an input to the cluster node.
Do you know a node that could help me to compute the similarity between each users based on the binary values in 120 columns ?
You could use the numeric distance node and select Manhattan distance. As you data is an orthogonal matrix with 120 dimensions with binary values (0 and 1) the Manhattan distance will give you the sum of the differences between the binary values. So if all binary columns match the distance will be zero, if 20 are different then the distance will be 20. You may need to convert the binary columns to integers/floats first if they are stored as actual binary values (use can use a Rule Engine node to do this).
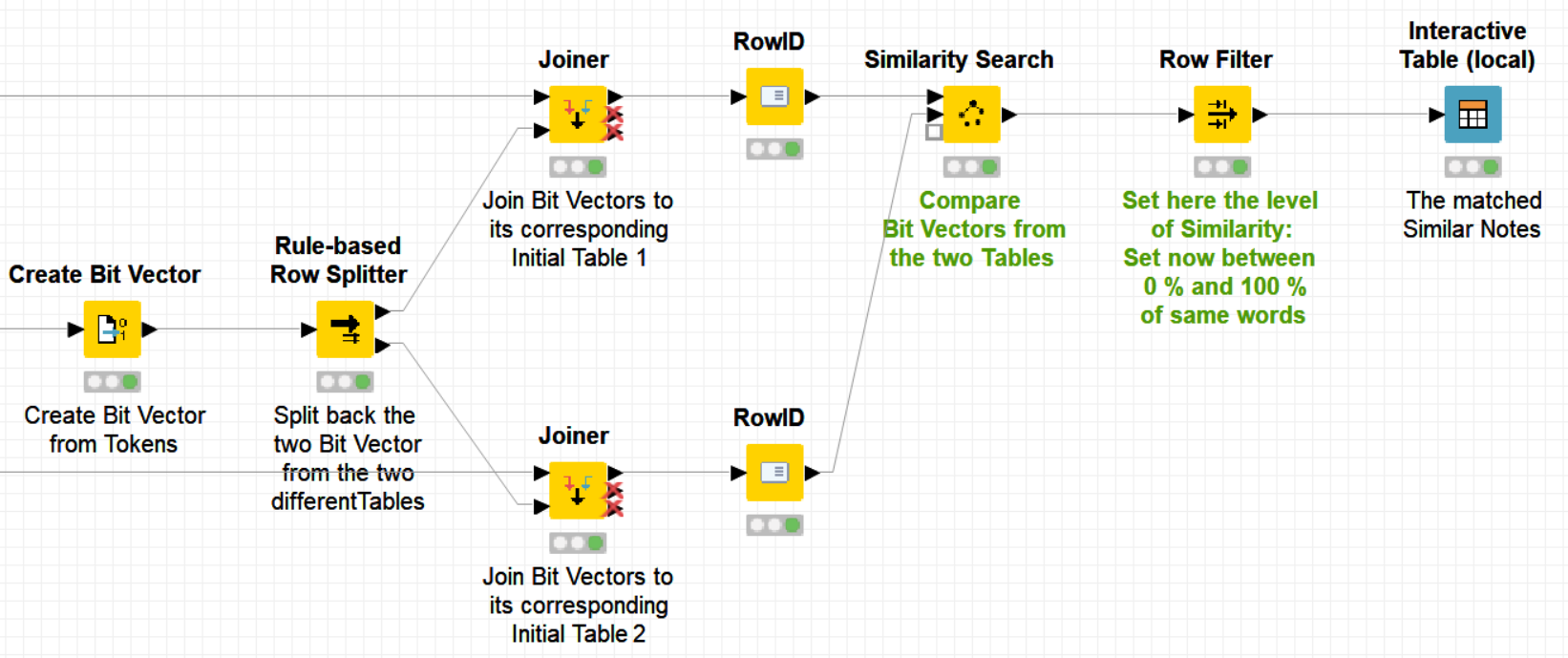
Complementary to @DiaAzul’s suggestions, another option is to convert your binary columns into a bitvector format and then use the specific KNIME bitvector nodes and functions to calculate distances.
The following workflow is an example of how to take advantage of the KNIME bitvector type to achieve this:
Thanks to both of you. I went the numeric distance way and managed to clusterize my data based on the distance obtained. I will try the bitvector way later to exercice.
I wanted to graphically represents the clusters obtained (via a scatter plot for example) so I applied a PCA compute node to try to reduce my hundreds of features to 2 dimensions but however I found out that I would need at least 7 components to explain 95% of the variance(2 Principals components only equals to roughly 40% of the variance) so I’m afraid it will not accurately represents the clusters.
So I guess there’s not so much I can do about that, but thank you for the help you provided me !
For visualisation you could try the t-SNE node which maps probability distribution of the data rather than eigenvectors. It’s non-linear so the distance between points is meaningless but it does show how data is grouped.