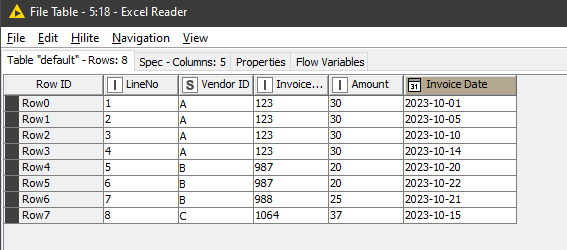
I would like to create a workflow with a fuzzy logic for date&time. Here, I have an excel with invoice data from vendors. Invoices should be considered as duplicates if the date difference (range) is ± 7 days. The date is then considered as similar. The invoices should then be classified as 1.
At the moment, I don’t know how to check in the whole file for such “similarities”. The check has to be performed from invoice to invoice. I hope someone can help!
If you had 4 invoices from vendor A, dated:
(1)1 Oct 23
(2)5 Oct 23
(3)10 Oct 23
(4)14 Oct 23
would they all be considered the same invoice, since according to the +/- 7 day rules:
(1) is same as (2),
(2) is the same as (1) and (3)
(3) is the same as (2) and (4)?
Here, I also have the Invoice Amount, Invoice Number and Vendor ID. The idea is to consider transactions as duplicates, if the:
Invoice Amount, Invoice Number and Vendor ID are “exact” and
the invoice date is similar (considered as similar, if difference between the dates is: ± 7days).
If those criterias are true, then the transaction should be considered as a “duplicate”.
I would like to check for each transaction in a column of my list for such duplicates. This means, that I don’t use any other list. The similarity search should be done for all transactions/vendors in this list.
Ok, @DA2023 so we’d take into account Vendor ID, Invoice Amount, Number when matching but I’m still not sure what happens if you had the following situation:
LineNo
Vendor ID
Invoice Number
Amount
Date
1
A
0123
30.00
01-Oct-23
2
A
0123
30.00
05-Oct-23
3
A
0123
30.00
10-Oct-23
4
A
0123
30.00
14-Oct-23
5
B
0987
30.00
20-Oct-23
6
B
0987
30.00
22-Oct-23
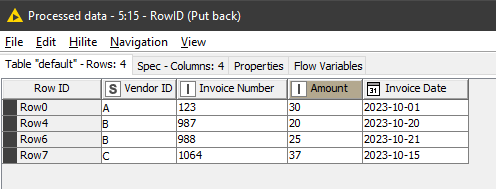
What would be the expected outcome,
e.g It could be this:
LineNo
Vendor ID
Invoice Number
Amount
Date
1
A
0123
30.00
01-Oct-23
5
B
0987
30.00
20-Oct-23
But if not, then what would be the rule for determining which of Vendor A’s rows to keep, since each appears to be a duplicate of the one before it?
EDIT: if I am able to assume that the above example is the correct output, then I think this workflow achieves it:
This calculates a max and min date that is considered to be a “duplicate” for each row. It then joins every row to every other row that has the same vendor, invoice number and amount, so that the rows can be compared.
The rule based row splitter then decides whether the row and it’s joined companion are considered to be “duplicates” based on the +/- 7 day rule, in which case they go to the lower port. All others go to the upper port.
A joiner node is then used to match the “duplicate” rows with the rows on the upper port, keeping only those rows that DON’T match using a “Left Unmatched” join condition, so effectively the joiner becomes a filter.
After this, it removes duplication created through the original join, and then tidies up.
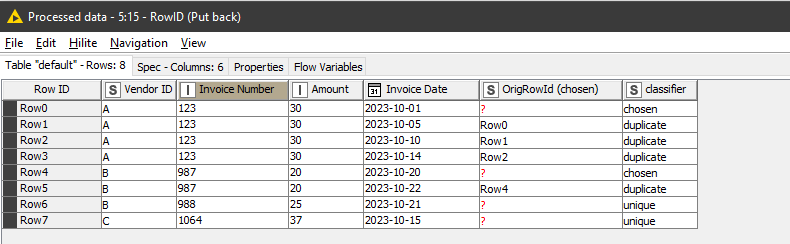
It would be great, if the output could be similar to the “duplicate row filter”, with the duplicate classifier (chosen and duplucate) and duplicate identifier (e.g. row 12), so that the duplicates can be extracted and displayed seperately (e.g. for internal audit purposes).
Hi @DA2023 , that can be achieved by a small modification, to the joins. Instead of keeping/discarding rows in the joiners, they simply direct the row to a branch that adds the required classifiers, and then concatenates them back into the output.
As you can see, this simply reports the rowid of a row chosen in favour of a duplicate, but it could be that ultimately another row was chosen in favour of that one too (as per my question about rules when there are multiple “duplicates” across a date range of more than 7 days, where Rows 1,2 and 3 are duplicates of Rows 0,1 and 2 respectively)
After that, you can deal with filtering using the classifiers.
If you want it to select a different “chosen” in the event of duplication, you’ll need to adjust the rules in the rules in the Rule Based Row Splitter.