I am new to KNIME and need some help.
I have two groups of molecules and want to find their similarity, select the one that are most similar/dissimilar and obtain the murcko scaffold of the most dissimilar ones.
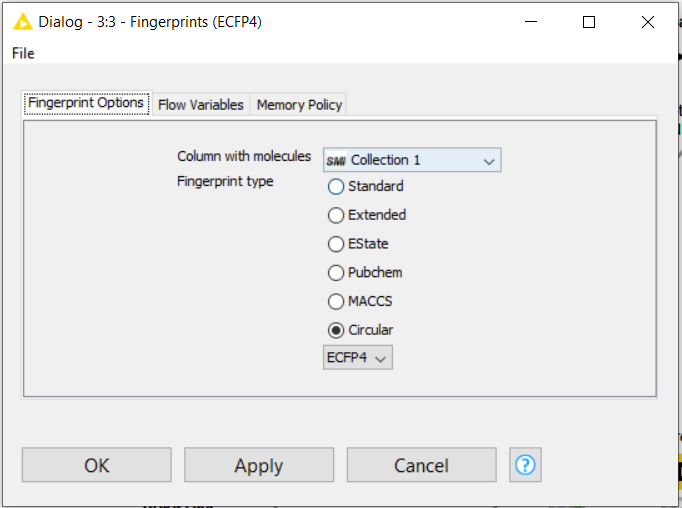
I converted my molecules in CDK, used the Fingerprint node to obtain their ECFP4 fingerprint (for both set of molecules) and then used the Fingerprint similarity node to compare my molecules. I set the node to obtain a matrix of values. How can I bin values >0.8 and obtain the murcko scaffold of the compounds?
Complementary to @elsamuel solution based on CDK nodes, which is perfectly valid, I would like to add an alternative solution.
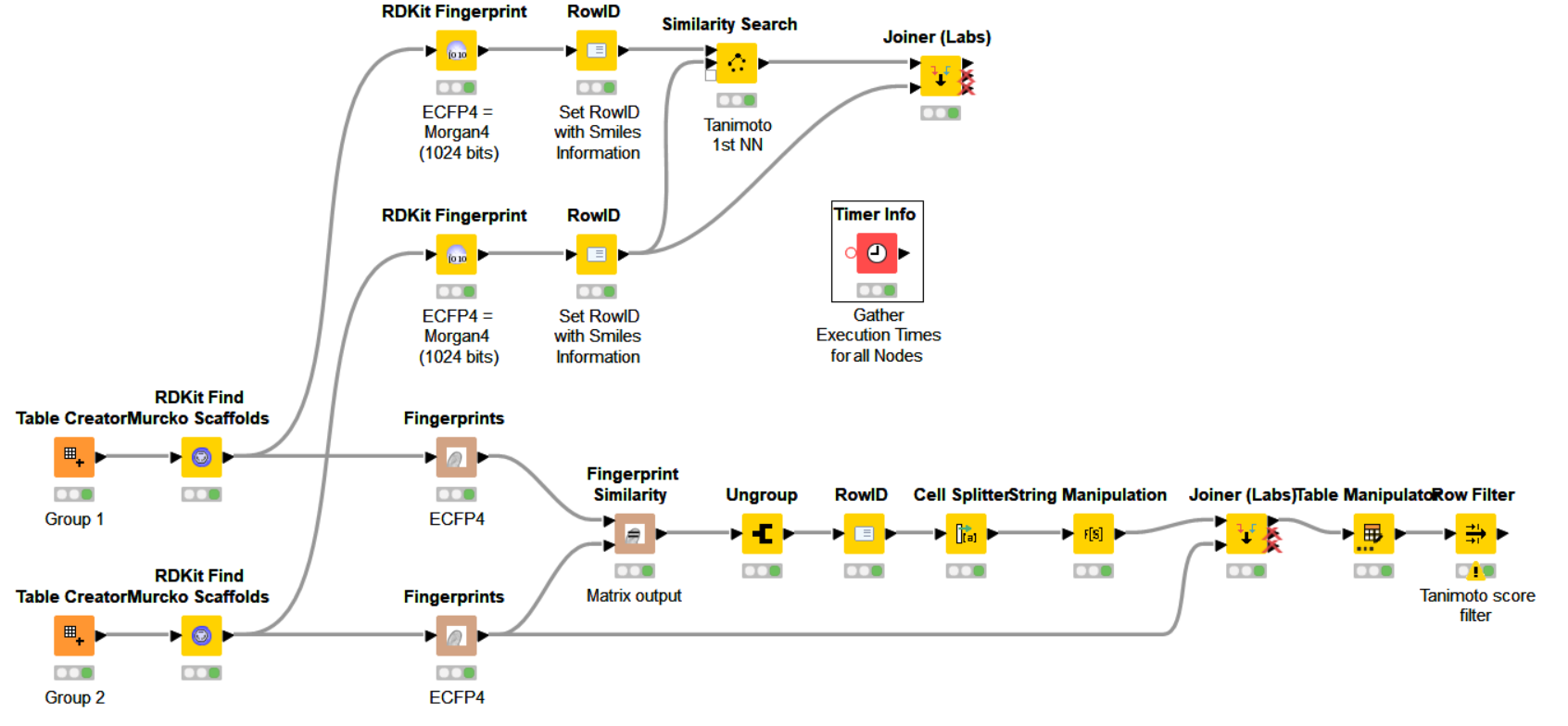
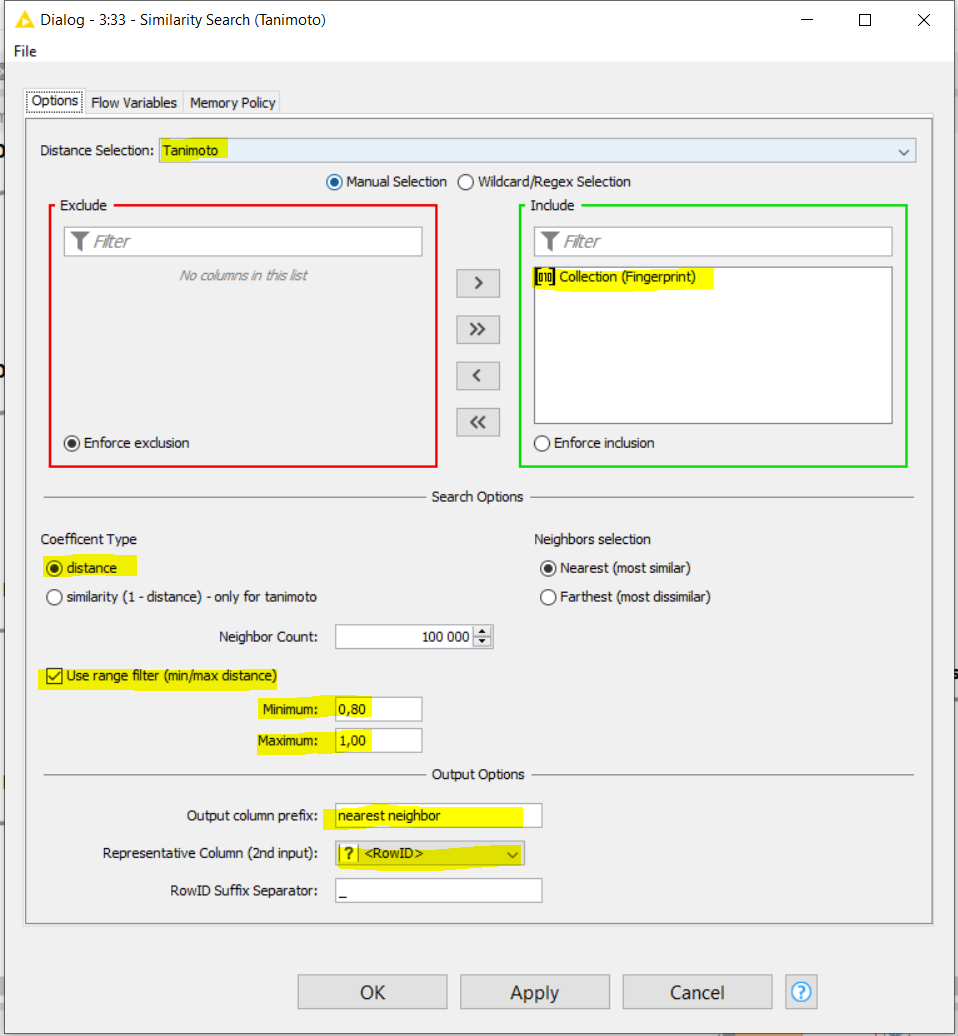
This added solution is based on the RDKit node to calculate the fingerprints and the -Similarity Search- node implemented by KNIME to calculate similarities. Both are more or less equivalent.
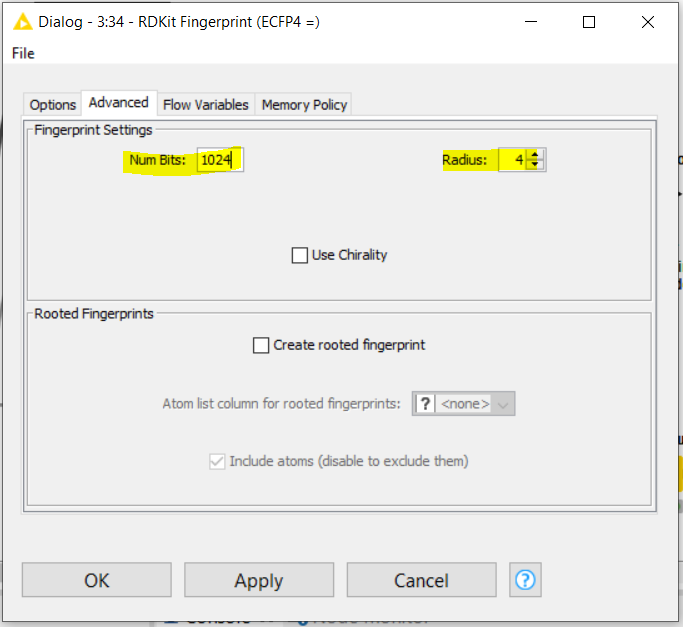
Having said this, I found by experience this second one based on RDKit & the KNIME similarity node to be faster (for fingerprint generation & similarity calculation) that the initial one. Besides this, the -RDKit Fingerprint- node gives more options and freedom to generate the fingerprints. For instance, the -Fingerprints- node by CDK does not allow to define the number of bits to set to store the fingerprints, which may eventually generate hashing collisions is you have to generate fingerprints for a big number of molecules:
I’m adding a -Timer Info- node to control and check the time every node takes to execute, so that you can compare between the two solutions, or others in the future. In this example, you will not see much difference but time execution difference may get important if you have big sets to compare.