I’m using the “Similarity Search” node to match entries from a reference table to my sample table. I would like to return all matches with reference entries within a (distance) range. I’m aware of the “Use range filter” option, but this returns only as many matches as specified in “Neighbor Count”. A workaround would be to set the “Neighbor Count” to an extremely high value while using the range filter. But first of all, that doesn’t seem very efficient and second of all might the result still be incorrect, if there were more matches then specified in the “Neighbor Count”.
Does anyone have a idea how to solve this? Or am I just missing something in the node options?
I believe the solution you are providing in your question is the right one and the most appropriate. The only thing that is lacking to be fully operational is to set the “Neighbour Count” value with a variable. The value of the variable should be the number of rows in your 2nd input Table (the target one) which is the maximum upper bound that could be reached within your distance interval (in the worst of the cases I would say). I believe this is the way to go, and you were almost there. Please get back in touch if you need further guidance for this question and we will be happy to help.
Could you please develop what you mean by “relative error metric” ? Depending on the field one works, this could have different meanings or interpretations.
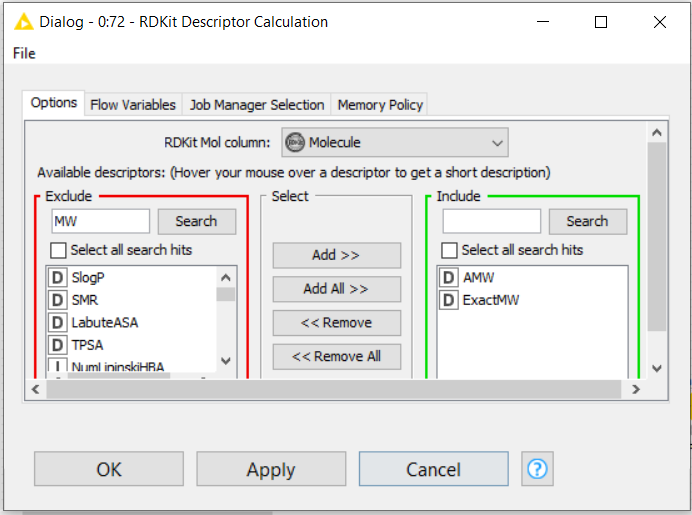
The “theoretical_mass” “ExactMW” and “average mass” (AMW) (taking into account nature isotopic atom distribution) can be computed using the -RDKit Descriptor Calculation- node. You could compute your formula using the -Math- node from there.
Thanks for the hint, but I don’t think, that I could use this for my use case.
I’m doing untargeted analyses of natural organic matter. So I have a list of a few thousands peaks from my measurements and want to match them to a huge database with molecular formulas and their corresponding exact masses. I already implemented that whole function, but I just wondered, if I could apply the ppm error directly in the similarity search.
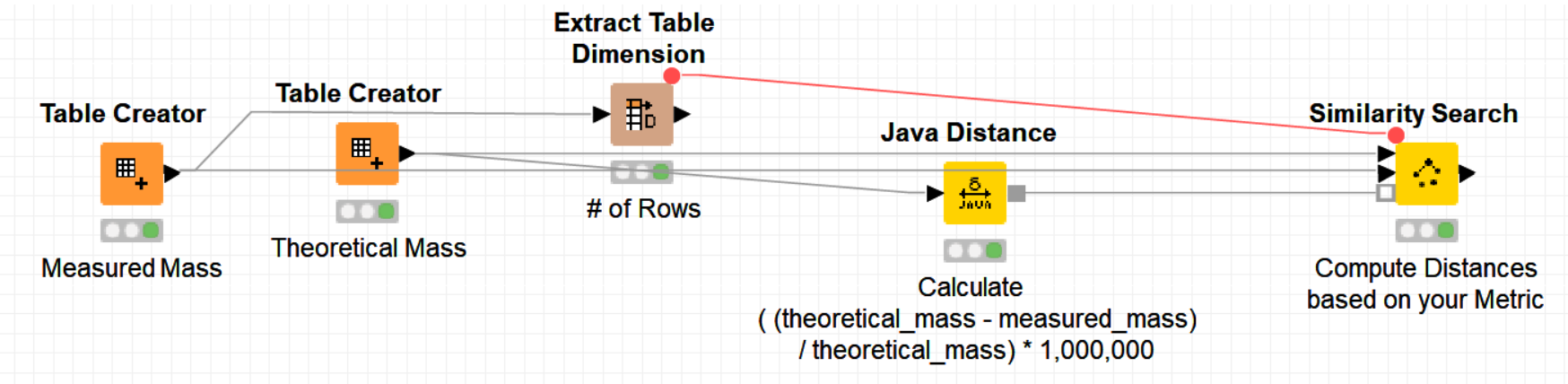
I took a deeper look into the distance nodes and finally understood, how to use the “Java Distance” node correctly. I already implemented my personal distance metrics (ppm error as described above)!
The similarity search itself needs more time now, but overall the workflow needs nearly the same amount of time (because the joins afterwards are getting cheaper).
Thank you very much for your comprehensive help! It really led me to the wanted solution.