I am doing research in psychology and trying to use KNIME to analyze my text data. But as I am new to KNIME and its functions, I am stuck and feeling frustrated and would very much appreciate your help.
I now have a list of 1000+ items/sentences from different questionnaires. I am trying to identify items/sentences that are similar to each other within the corpus. I have attempted making use of similarity search but I guess I have not set the workflow right – it does not run.
So far, I have successfully prepocessed the documents. What nodes can I use after this to be able to identity duplicate documents within the corpus? Can you guide me on this?
And if you know of better analytical strategies, I am open to them as well.
Yes, I have. I have already tried it. But it did not give the results I wanted. Plus, in LDA, or Topic Extractor I would have to identify the number of topics I want to extract, which we are not sure of theoretically.
So currently, we are looking at different alternatives.
Hi @Sophiahn
The number of topics is always be theoretically, and can only be determined by domain knowledge. So my approach would be to run multiple LDA an see what number of topics fits best. Eventually you can determine the number of topics using clustering (the elbow method). Or do it the other way around: create with your domain knowledge a list with topics and the synonyms. Find the synonyms in your documents and add the topic. This will also takes some trial and error.
gr. Hans
Always good to see a fellow psychologist around, welcome to the KNIME community!
Let’s see if I can help you here. First: what KNIME version are you using? If you download the most recent version (KNIME 4.0) you can use the Duplicate Row Filter node to detect and remove duplicate documents in your corpus!
Second: I have some questions about your use case. You say you did not manage to use similarity search – why not? Does the workflow outputs any error? Could you share a bit of an example of your workflow with us (do not put your real data)? And why exactly do you say that with topic extractor strategy you do not get the results you want? From what I understood of your problem, I agree with the solutions proposed by @HansS.
I have tried Duplicate Row Filter node but it was not able to detect duplicates since the duplicates we are looking for do not have exact wording. So we thought of using ‘similarity search’ which, from my understanding, computes for distance in numerical values and matches sentences that have small distance (in other words, small numerical values). Is this right?
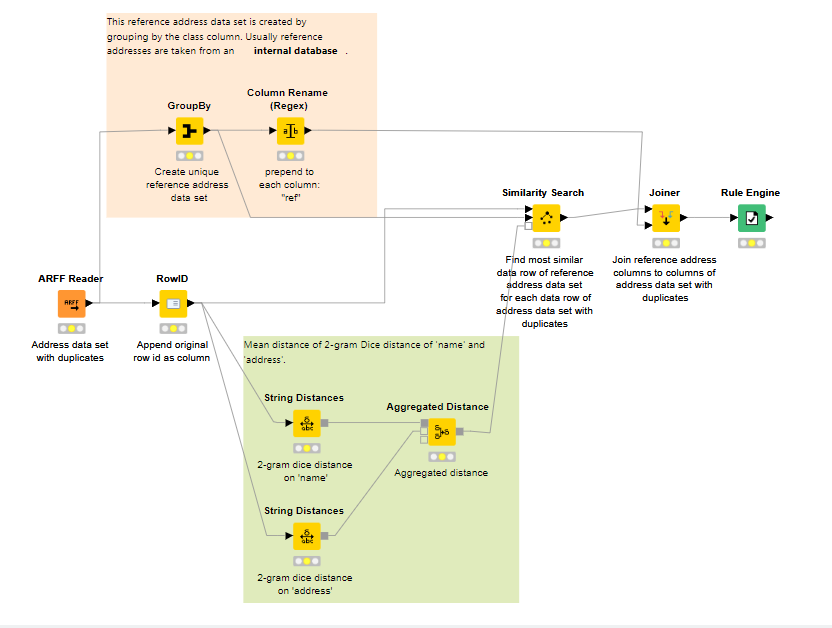
We were not really able to proceed with similarity search because we did not know to create a work flow… The examples provided on the KNIME website usually do similarity search between two separate files rather than within a single file.
We are trying to pattern our work flow based on this example above. But we do not know how to customize it to our data. Could you let me know what nodes we can use after preprocessing?
As for the suggestion by @HansS on LDA or Topic Extractor, we have done it and are keeping its results as a reference. We just want to see which of the two (LDA vs. Similarity search) gives us better results.
My guess is that a bit of cleaning would be useful to minimise the detection of noise and thus improve the performance of similarity search. So here is what I would do:
convert the text column to a document column using String to Documents;
clean the document column with the following text processing nodes: stop words, remove any accents (if applicable) and punctuation, convert to lower case. Beware with stop words though, i.e if sentiment is important (e.g. negation), you should tag such terms before using POS Tagger and set them to unmodifiable to avoid deletion;
convert back to text using Document Data Extractor;
now use similarity node: levenshtein distance (also called EDIT distance) is sensitive to the order of words and appears appropriate for this task.
The philosophical part: you want to find similar sentences. What exactly defines similarity in your project will determine the kind cleaning or preprocessing that you should apply: e.g.
similar sentence meaning would suggest that you may want to look at synonyms or latent topics. In this case, preprocessing could probably include stemming words as well;
same words occurring across sentences or duplicate analysis should boil down to what I have suggested here above - beware of removing negated stop words carelessly though, for negated sentences would become similar. In addition, if orthography is an issue, you can use the Dictionary Replacer to correct misspelled common words.
Finally, another way of doing similarity search is by extracting a dictionary of the most relevant terms in the corpus based on TFxIDF, then transform your data into a document vector using only that dictionary and then search for similarity across docs based on a binary distance. This is a bit more laborious than it reads here though due to the processing involved. The following resource could help you as a starting point: https://nlp.stanford.edu/IR-book/information-retrieval-book.html