Hi there
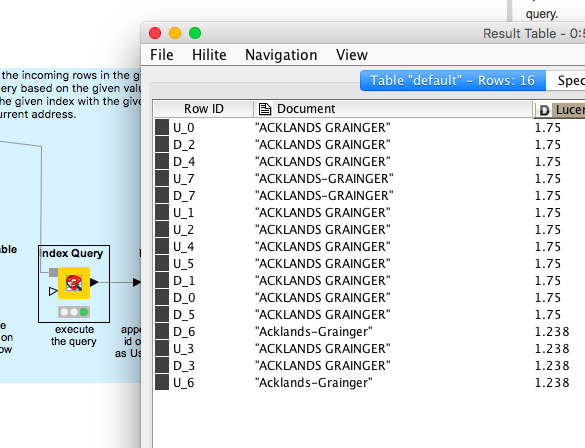
I am stuck on getting an existing example to work for a different situation. I have one column of dirty data where the same company is repeated various times with slightly different words, punctuation etc. I am looking to create a mapping table of some sort which removes the duplicates caused by misspellings or punctuation, essentially cleaning up the list for analysis. Stuck on getting the Duplicates metanode and Java indexing.
I am not an expert but from my take on the workflow at a certain point the query should read something like this:
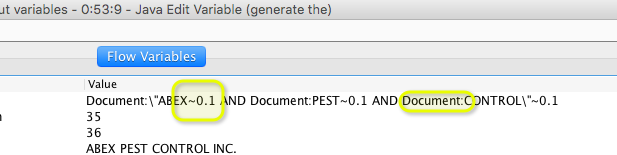
Document_fullText:“ACKLANDS\“~0.1 AND Document_fullText:\“GRAINGER”~0.1
when I just run the workflow the company name parts lack a closing quotation mark and the reference is “Document” rather than “Document_fullText”. The system gives an error message that indicates there is no “Document” but the document consists of several items of which the full text is one.
“Invalid field: Document. Might be a typo in the query string.”
Right now I am on an older PC and thus I can’t fully reproduce the issue.
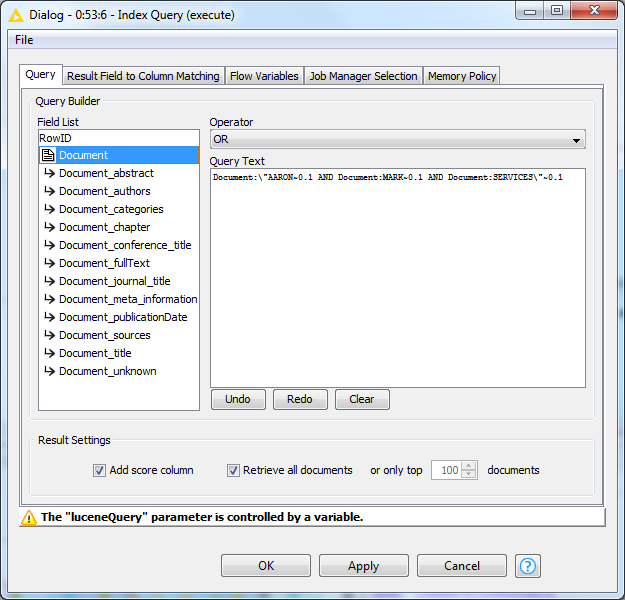
IMHO, the problem is that Index Query node expects column named “Document” of the String type but there is only a column with the same name of the Document type.
We can check it while trying to manually build a query (not using query string passed by “luceneQuery” flow variable). Double clicking on “Document” item, does not move it to the “Query Text” area compared to other available items.
@mlauber71 and @Martin_K are right. The problem is you need to use Document_fullText instead of Document. Your query will run smoothly then.
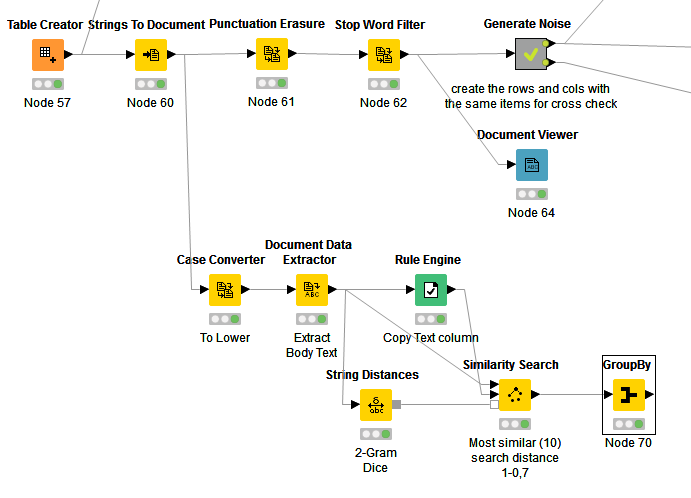
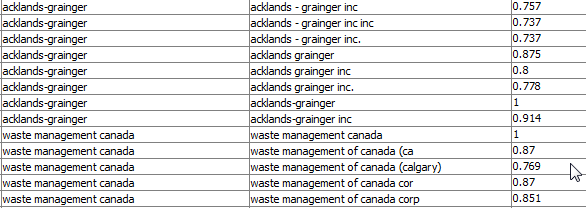
But if you want to do find dublicates you would rather use a Similarity Search approach that @izaychik63 was suggesting. This would actually shrink your workflow down a lot.
Usually you would start with the preprocessing steps you already integrated in your workflow (the punctuation erasure and stop word filtering), but i thought this way it is more descriptive. Fuzzy_withsimsearch.knwf (150.5 KB)
Thanks everyone! You are all correct - the query is expecting Document_Title (in my case) to get the Index query to work.
However, my approach is likely not the optimal way of solving the problem, as it is essentially doing a massive (10,000x10,000) cross search of companies, which is not optimal. So @MH’s solution seemed to get me to the right result using a much simpler approach.
I need to investigate the de-duplication link that @izaychik63 suggested to see if it could work in a different case.