Hi @supersharp,
@mlauber71 and @Martin_K are right. The problem is you need to use Document_fullText instead of Document. Your query will run smoothly then.
But if you want to do find dublicates you would rather use a Similarity Search approach that @izaychik63 was suggesting. This would actually shrink your workflow down a lot.
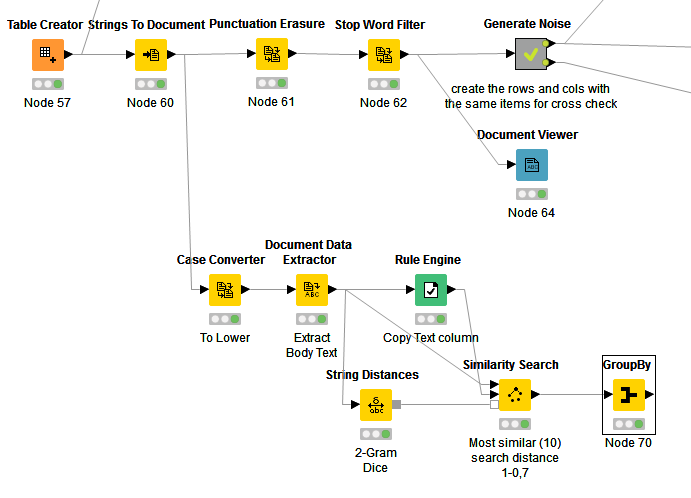
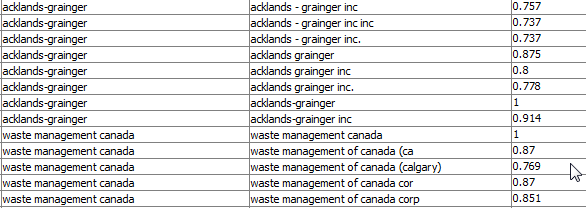
Usually you would start with the preprocessing steps you already integrated in your workflow (the punctuation erasure and stop word filtering), but i thought this way it is more descriptive.
Fuzzy_withsimsearch.knwf (150.5 KB)