This workflow reads in a series of misspelled retailer names, along with the desired version of the names. Using the Similarity Search node, the closest correctly spelled name is matched based on Levenshtein distance.
Nice workflow!
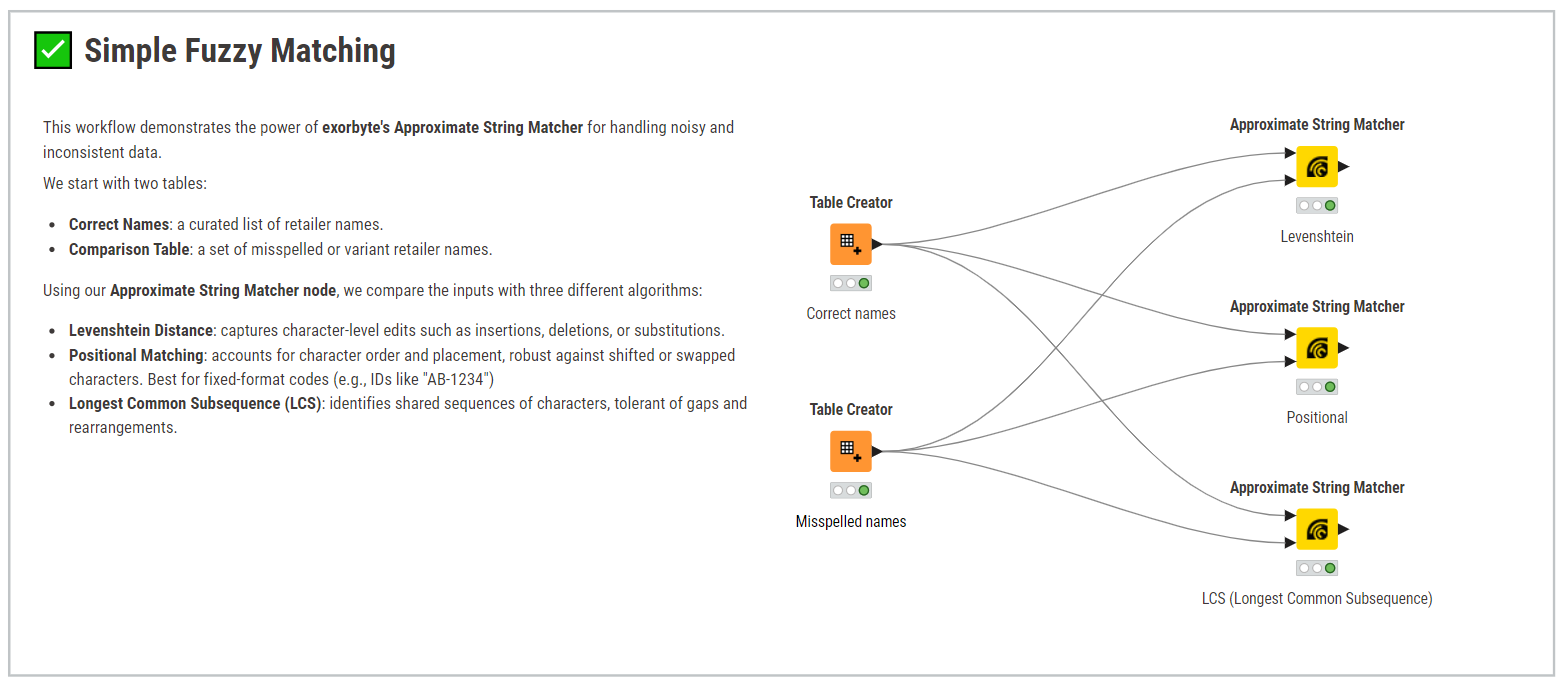
If you’re interested in exploring other approaches, we’ve built a similar example using the exorbyte Approximate String Matcher node, which supports different algorithms like Levenshtein, Positional, and LCS. You can check it out here: