Then some subsequent aggregation and joining to compare to your original list of terms, but exactly how this is done will depend on the format of your data. If you have a small example dataset I could try to build a toy workflow for you to check out.
Thanks for the data. Attached here you’ll find a workflow solving this using two different solutions, the one suggested by @ScottF (thanks Scott ) and another one based on classic KNIME nodes with eventually comparison of results. The frequencies are calculated per document. If you need the frequencies globally then the same workflow could do it but you need change the grouping of the groupby node (then do it only based on column “description (filtered)_SplitResultList” and not on “Doc_Index”) or to aggregate the documents first in a single row (what suits best to you).
This is fantastic. I love how I can study a Knime flow step by step and it makes perfect sense.
Now that I see how it’s done, I see a flaw in my question, which is that all my dictionary terms were one word. In reality, I’ll need to search for multi-word terms, e.g. “Boris Johnson”.
Since the join node is where the dictionary comes into play, I’ve studied the docs for that, as well as Cell Replacer, but I’m not seeing a way forward.
If I were programming this in a different language, my instinct would be to iterate through each dictionary item with a “contains” test on the description column. If it makes it any easier, I don’t want to count how many times the dictionary term is mentioned in each article – I only need to count how many articles mention the term.
 ) and another one based on classic KNIME nodes with eventually comparison of results. The frequencies are calculated per document. If you need the frequencies globally then the same workflow could do it but you need change the grouping of the groupby node (then do it only based on column “description (filtered)_SplitResultList” and not on “Doc_Index”) or to aggregate the documents first in a single row (what suits best to you).
) and another one based on classic KNIME nodes with eventually comparison of results. The frequencies are calculated per document. If you need the frequencies globally then the same workflow could do it but you need change the grouping of the groupby node (then do it only based on column “description (filtered)_SplitResultList” and not on “Doc_Index”) or to aggregate the documents first in a single row (what suits best to you).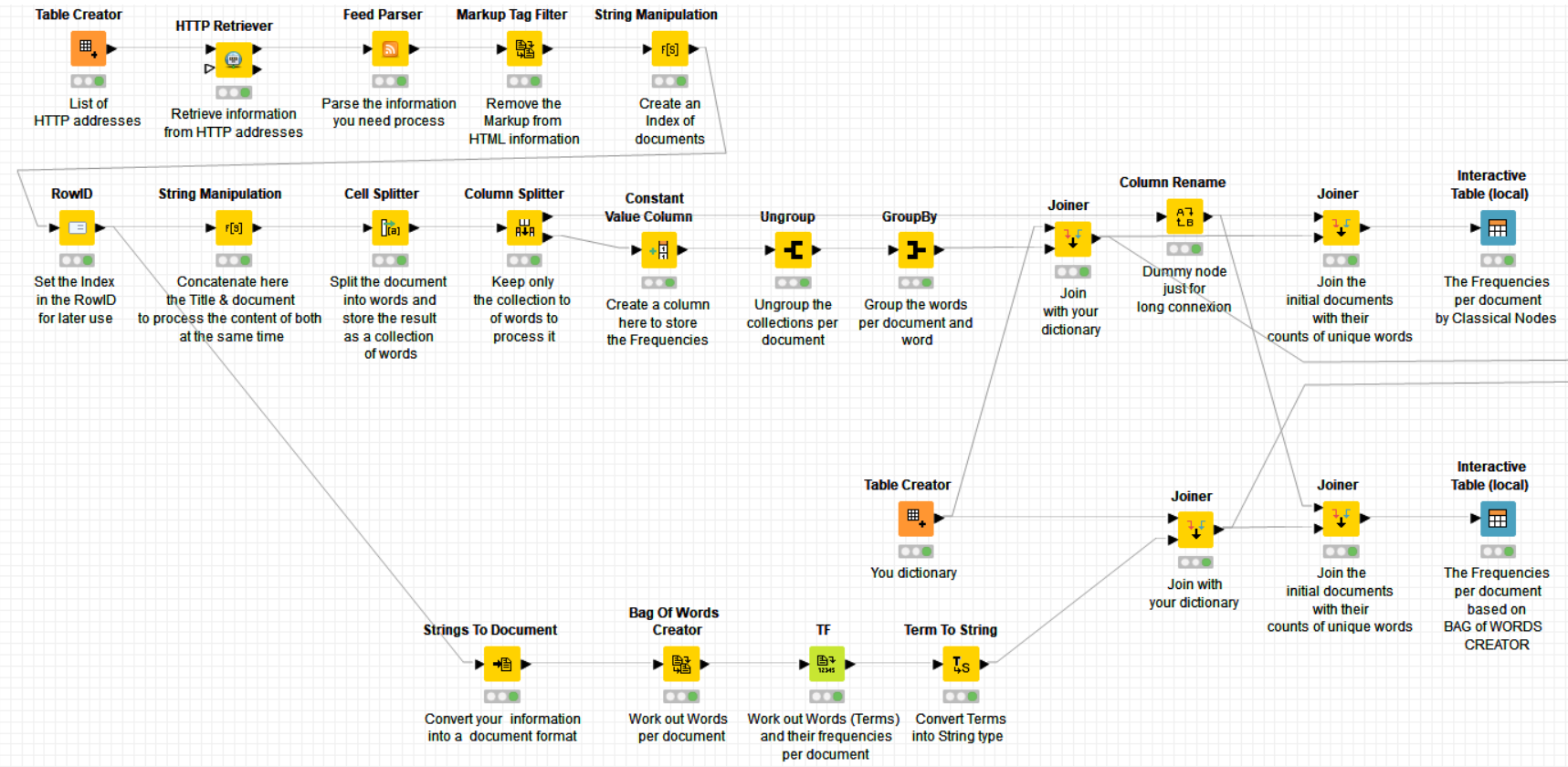

 !
!