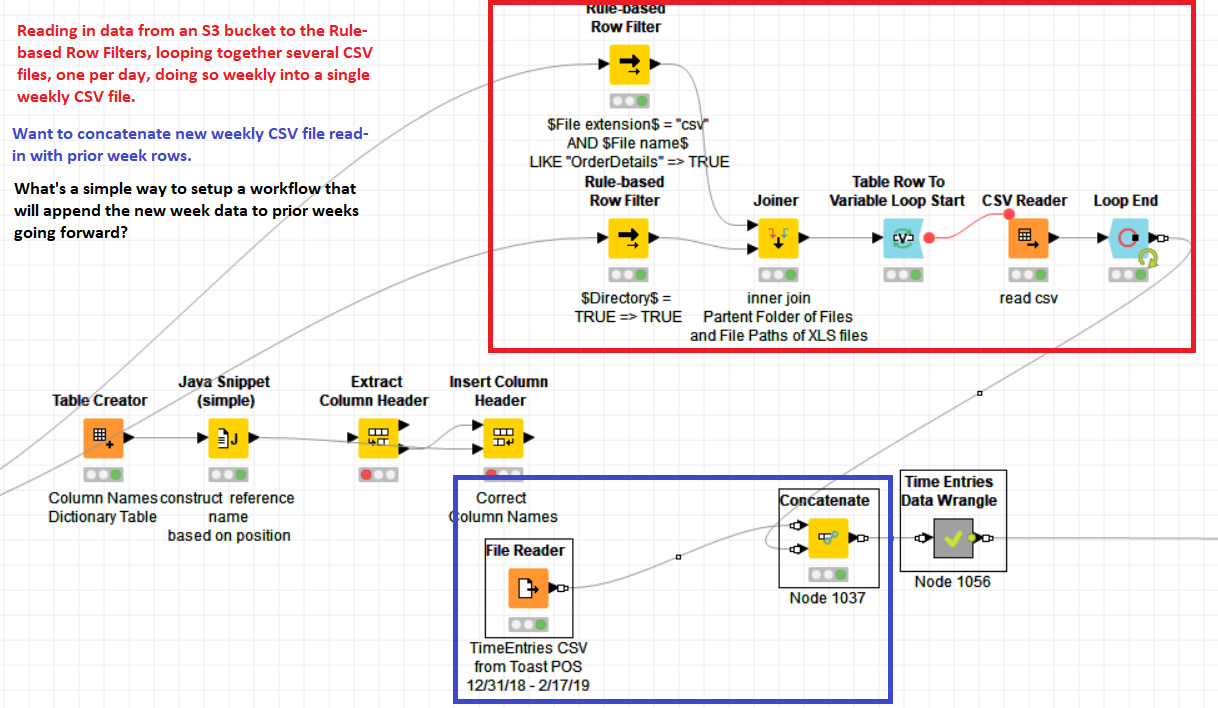
I’d like to read in seven days of CSVs from an S3 bucket and append the raw data read-in to prior weeks. I’ve seen 3-4 prior conversations on this topic but none of them have a good example workflow to learn from and apply to this problem.
Additional Issue…what do you when a variable Loop End requires the ‘allow variable column types’ due to a column being a string in one file and double in another? This variable column type is preventing the option for using a CSV Writer to save/append the new data to an exisiting CSV.
Hoping a screenshot will further explain the context of this problem:
I would recommend to store data not in CSV but SqLite DB. Then you do not need to read Toast POS to concatenate with new orders. DB Merge will do it for you.
You could import all the data as string from CSV and later if you use the data convert the appropriate columns to numbers if necessary. In general CSV is widely used but has its downsides.
@izaychik63 I like you suggestion to use SqLite DB but can’t get into something unfamiliar right now. Looks like it’s worth exploring though, do you have a good suggested starting link resource you can share?
@mlauber71 to the rescue again…I followed your prior post on the readr suggestion you made to someone else and utilized their recommendation to ignore column headers so all is imported as string to start with.