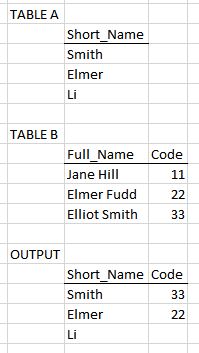
I am trying to replicate the functionality of Vlookup in Excel using wildcards, but am unable to figure it out. Here is an example of what I need to do:
Table A has part of the names of people I want to look up (Short_Name). Table B has the column Full_Names that I want to search through, find cells that contain the Short_Name sub-string, and return the corresponding code. Table C shows the result.
Were I looking for perfect matches between [Short_Name] and [Full_Name] strings, I could just use a Joiner Node or Cell Replacer Node. The problem I am running into is that neither of these allow for searching for a sub-string in Table B (as far as I can tell).
The only solution I have seen thus far involved using the Cross Join Node, such as is suggested in this post.
This will work fine for smaller data sets, but with larger ones this could result in billions of rows. Not sure how well my old pc is going to deal with that. Maybe it will not be a problem, but it seems like a rather inelegant solution.
Thank you for the respose and link. I am having a pretty hard time following that post, but I don’t think it is showing what I am trying to do. I am not looking to eliminate duplicates.
I am also not looking for a more robust comparison tool. Simply searching for a sub-string is good enough for my purposes.
Hmmm, you can try using Cell Splitter on a Full_Name string and then simulating perfect matches between Short_Name and one of columns given by Cell Splitter.
Also considering Cross Joiner is streamable you can try streaming option KNIME provides.
I still wonder how you deal with multiple Jane names or Smith surnames?
Thank you very much for that link to the explanation for streaming. I am still somewhat new to Knime, and did not understand what the implications of streaming were. It looks like it could do a lot to relieve my concerns about the memory resources needed for a large cross join.
Regarding your suggestion of breaking up the Full_Name… Yes, that would work in that particular example. However, that was a simplified and specific example. The actual data I end up needing to do this with is much sloppier. I ultimately need the flexibility of using wildcard expressions.
The replies here have basically answered my question: there are a few ways to simulate vlookup using wildcard expressions, and they all will involve a Cross Join Node, followed by nodes that CAN use more nuanced and precise wildcard expressions to filter out all the rows that do not yield a match.
As far as multiple hits (like more than one “Smith”): yeah, good point. It will definitely happen that I get multiple matches. I’ll cross that bridge when I get there. Maybe do a second pass with a secondary matching criteria.