I have created a workflow that was updating records in to an on prem MS Sql database, but once I migrated the same data base into a basic Azure SQL instance. I have noticed a huge performance issue in DB Merge node. After doing some analysis I have noticed that passing nvarchar as a sql parameter for update query would force a full table scan if the column data type is varchar and the passed parameter is nvarchar.
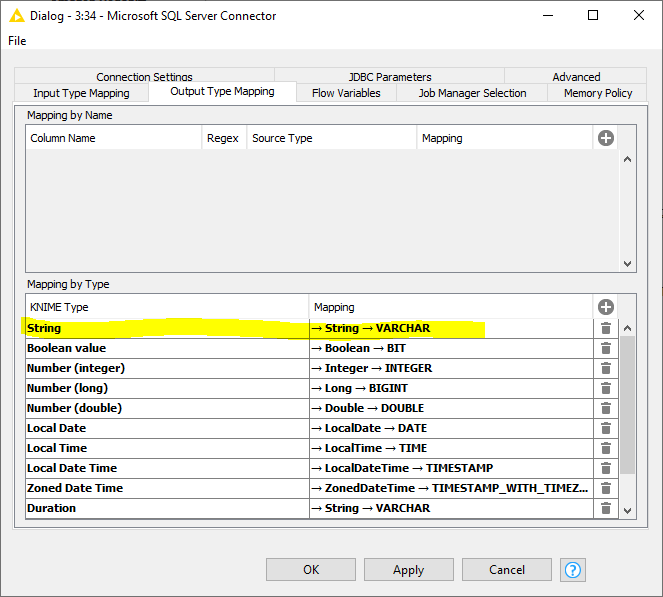
I have tried to change data type map in Knime Server Connector node and DB Merge node from string to Varchar but DB node generated query would always Declare a string parameter as nvarchar(4000) regardless if dataype of column is varchar or nvarchar. An example update statement generated is like this: “(@P0 int,@P1 datetime,@P2 int,@P3 nvarchar(4000),@P4 int,@P5 int)UPDATE …”
I have 450 rows to update so executing the update statement in SQL DB with columns data type as varchar takes 1 second per row but when I manually remove ‘n’ from @P3nvarchar(4000) to @P3 varchar(4000) the same query runs in 16ms
As a work around for now I have to change the database column data type to nvarchar as there is no way that I can change DB Merge to defined parameters data type
It will be great to have parameters created to match the data type map of defined columns or enable the user to select data type for parameters
so when you write to the on premise DB you do not have any performance problems but only when writing to the Azure SQL instance? Did you create all indices especially the one for the lookup column in the Azure SQL table?
I guess you mean the Microsoft SQL Server Connector node with the Knime Server Connector node. What mapping did you use for String columns or this particular column? The default mapping for String columns in the Microsoft SQL Server Connector node is VARCHAR
Maybe this is also a driver related issue. Can you please updated the JDBC driver to the latest version. For more details on how to register a driver see this documentation.
So the issue exists both on prem and cloud database. I didn’t face slowness on prem DB as the DB is powerful enough not to notice a full table scan. But that is not the case once you tailor your DB on cloud.
Yes, I have used the Microsoft SQL Server Connector node and kept the mapping from String => Varchar. Also I used the DB Connector node with MS SQL driver and had the same behavior.
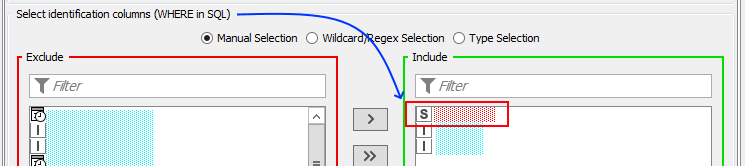
The issue is how DB Merge node handles String Columns in Select identification columns (WHERE in SQL) section. For any string listed there a Parameter would be created as such @P? nvarchar(4000)
Hello menayah,
I double checked again. If you leave the Output Type Mapping as it is (String->VARCHAR) KNIME uses the PreparedStatement.setString() method whereas when you change the mapping to String->NVARCHAR it uses the PreparedStatement.setNString() method for both the set and the where columns.
When looking at the code I suggest to start with the org.knime.database.DatabasePlugin class.
Bye
Tobias