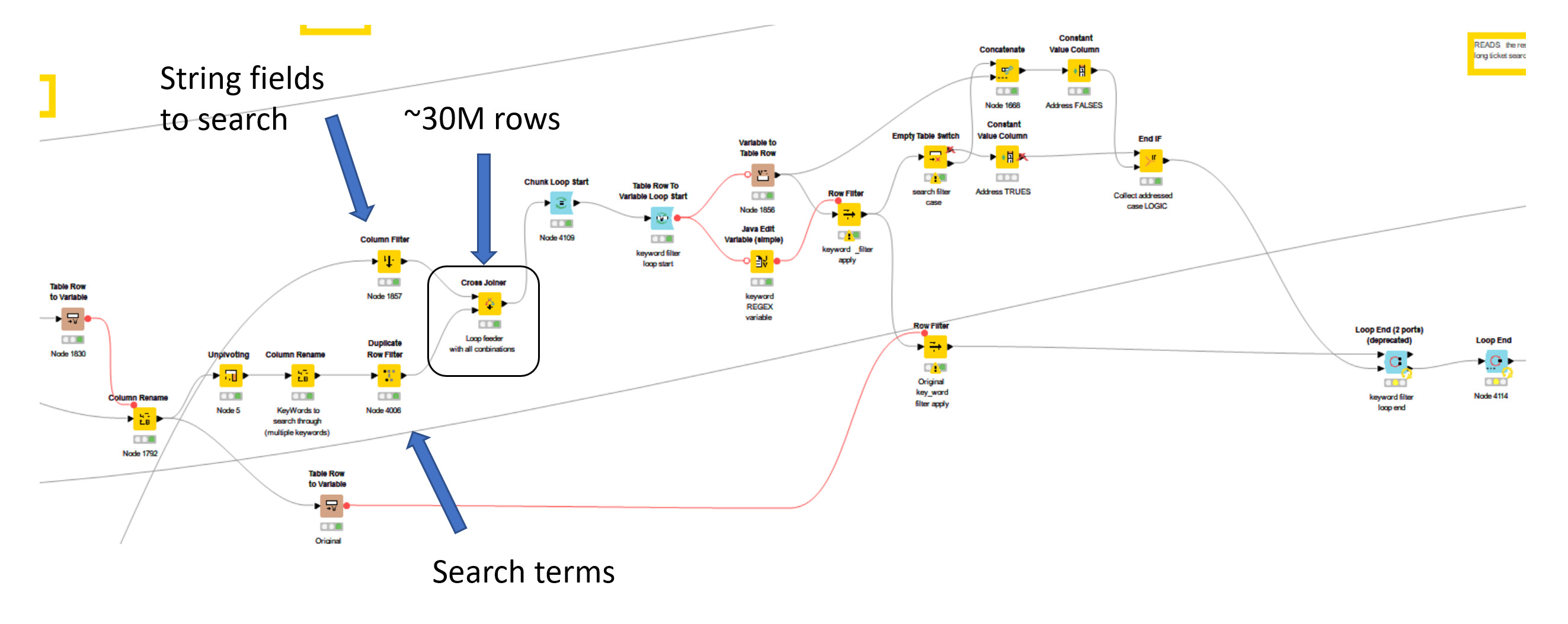
Does anyone have any ideas on how to speed this up?
One approach I looked at was just after the end if near the end of the workflow. If there is a successful search, the logic returns a “True” value. In that instance I can remove (a) the search word, and (b) the search string from the cross-join, or the chunk loop, but I was unable to get that logic to work.
I’ve switched combinations between running “in memory” and “writing to disc” for the bulky nodes, but I don’t seem to be making any progress.
as I have understood, you need to find if a string contains at least one of a collection of words.
This problem sounds similar to one faced in the Just Knime it! challenges:
Hi @Unlockedata , which part of your workflow is slow? I’m assuming it is achieving the cross join to generate 30m rows in a reasonable time (not necessarily quickly, but ok) .
So the really slow part is going to be the loop.Loops are ALWAYS slow. And nested loops are slower! When I say slow, I mean orders of magnitude slower than the equivalent non-loop solutions where one exists.
I avoid loops unless my data set is small, and using a loop reduces complexity, or my data set is large and I see no alternative. So my question is whether your loops can be avoided, and I don’t know the answer to that without seeing exactly what they are doing.
What is the purpose of the loop in your case?
If you have already performed the cross-join between your set of fields to search, and your search terms, then I would presume that the 30m rows contain all combinations of “fields to search” and “search terms”. If that is the case, and you are then trying to see if the search term is contained in each field, a Rule Engine node should be able to perform this for you without requiring the loop.
Obviously if the purpose of the loop is more than just the comparison, then maybe you need it but even if the loop is required for some other processing, I’d still suggest a Rule Engine followed by a Row Filter prior to the loop would dramatically improve the overall execution time.
As a slightly different approach, you may be interested in the following demo workflow, which demonstrates uses of some components that might be able to assist you here. Take a look at this:
Most of these components wrap an H2 database to enable the kind of search comparison that you are probably doing, and you may find you can use these to perform your comparison, which is effectively a “fuzzy join”.
The one component in that demo that uses an alternative approach is the “Regex Lookup Filter Joiner” component which does implement a chunk loop against one of the input tables but puts the cross joiner inside the loop (instead of prior to it) in attempt to reduce the overall memory usage. Whether this performs better or worse than the equivalent “Join Regexp Like” component probably depends on the data and the available memory.
The set of my joiner components can be found here: