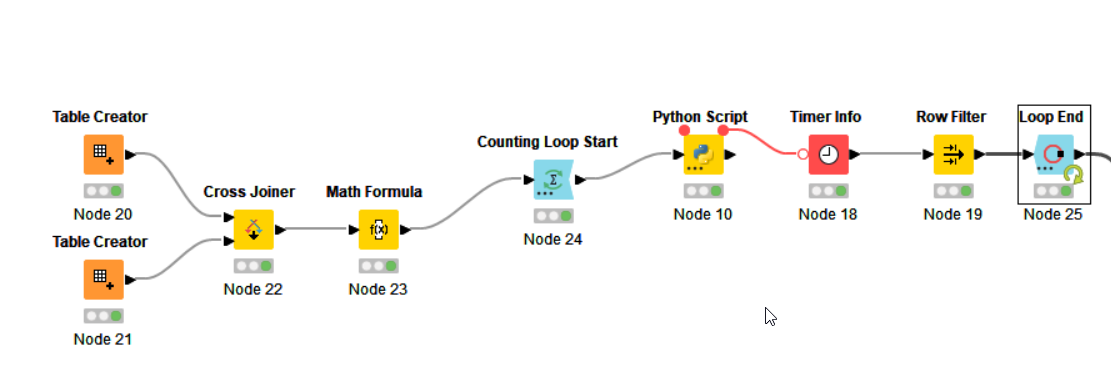
I’m using python nodes quite a lot in my Workflows and sometimes even in loop constructions. I’m wondering why the execution of a python node takes so long even when only a few number crunching is done. For me it seems that the initialisation of the python environment behind it takes the most of the execution time.
For example:
# KNIME settings
import knime.scripting.io as knio
df = knio.input_tables[0].to_pandas()
# END of KNIME settings
# The usual suspects
import pandas as pd
import numpy as np
# core script
df = df.groupby('a').sum('c')
df['d'] = np.sqrt(df['c']) + 23
# Postptrocessing
df1 = df.copy()
# KNIME Postprocessing Settings
knio.output_tables[0] = knio.Table.from_pandas(df1)
# KNIME Postprocessing Settings
Takes about 4 seconds when it’s filled with a table of 35 rows and 3 columns (string + 2 number columns).
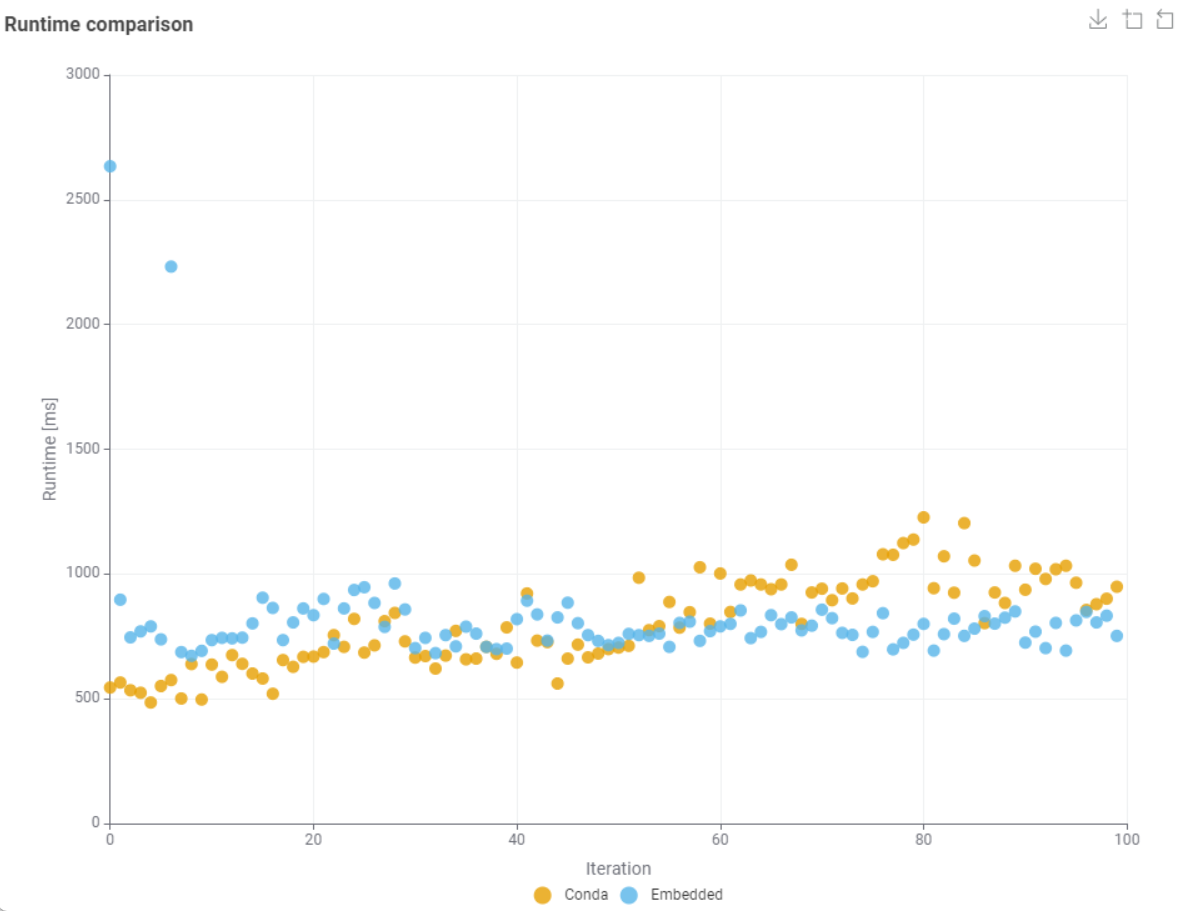
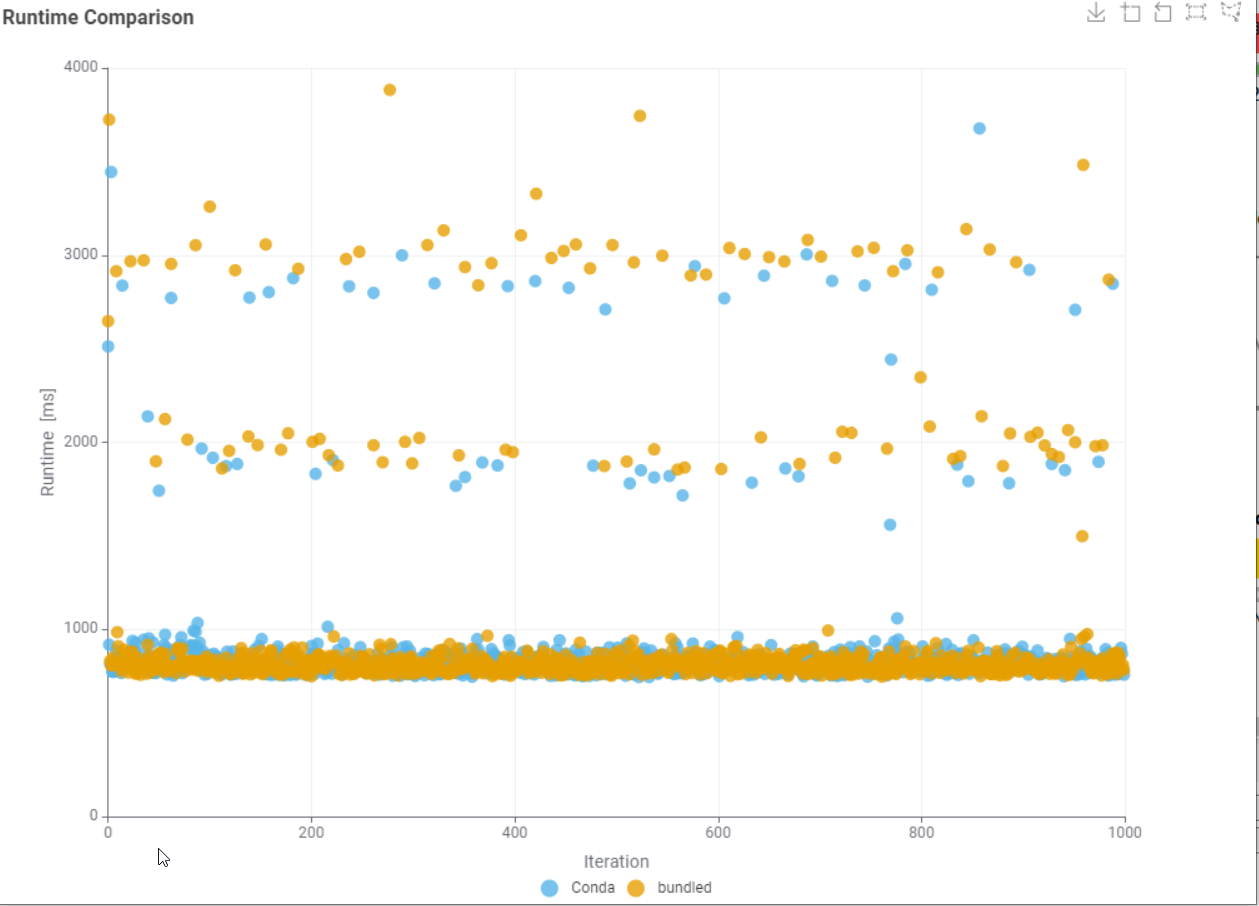
Did some testing this morning according to different python settings in KNIME:
I ran the python script shown above 100 times and measured the timing. Once with the option “conda”, once with the option “bundled” in the KNIME settings.
@ActionAndi conda will use a Python environment that runs in a separate installation and will contain the packages that are there. The bundled Python version is integrated into KNIME and the data exchange is via Arrow Tables.
From statistics there’s no difference if I use the external Conda environment or the bundled one.
But what is the root cause for this long runners? Reload of the Python Environment?