Hello,
I have an unballanced data of 7 classes. I read that people recommend SMOTE to balance it without the need to delete samples from oversampled classes. And, indeed, the accuracy of the model that I am generating with random forest or SVM increased significantly.
But I feel that this improvement is fake and is kind of cheating. Actually, there 2 options in the SMOTE node ( oversample the whole dataset or oversample the minority).
Without SMOTE, the acc = 0.34, with oversampling minority, I got acc=0.64 and with oversampling the whole dataset, I got 0.75 accuracy.
When I qnqlysed the confusion matrix for each case I noticed that the model is good to predict the oversampled classes. So, I expect that this ease of prediction is coming from the way of creating the dummy samples (I guess by interpolation). These dummy samples are similar to each other and can fall in the training or test set, the machine learning algorithm will find the prediction very easy.
The dangerous part is in the moment of testing an external dataset with this fake robust model that I will probably fails.
Has anybody similar or different experience with SMOTE or success with other tools to balance the dataset without the obligation of discarding samples because my dataset is already small.
Thanks,
Hello zizoo,
the issue in this case is probably the metric.
Accuracy often times suggests a higher generalization performance in case of unbalanced data therefore I would recommend to monitor precision and recall of the minority class as these metrics usually give you a better idea what your model is actually doing.
Concerning the SMOTE node I’d recommend to only oversample the minority class if your dataset is unbalanced because it otherwise won’t remedy the unbalance in your data.
Please note also to apply SMOTE only to your training data, your validation (or testing) data should correspond to the actual data distribution in order to obtain a valid estimation of the models generalization ability.
Cheers,
nemad
Hi Nemad,
I prepared a simple workflow with SMOTE. Do you think this is the correct way to use it with minorities oversampling?
Thanks,
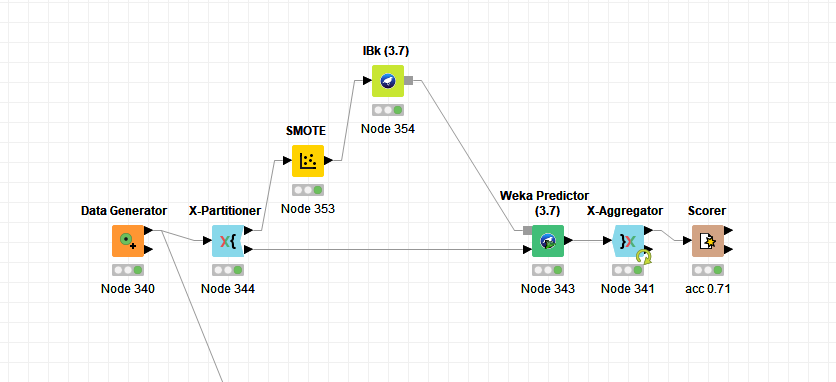
Hi Zied,
I am not comfortable to tell you that it is correct but I can tell you that that’s how I would do it ;).
In the end what is correct will depend on your results and in most cases correct is what works best.
Cheers,
nemad