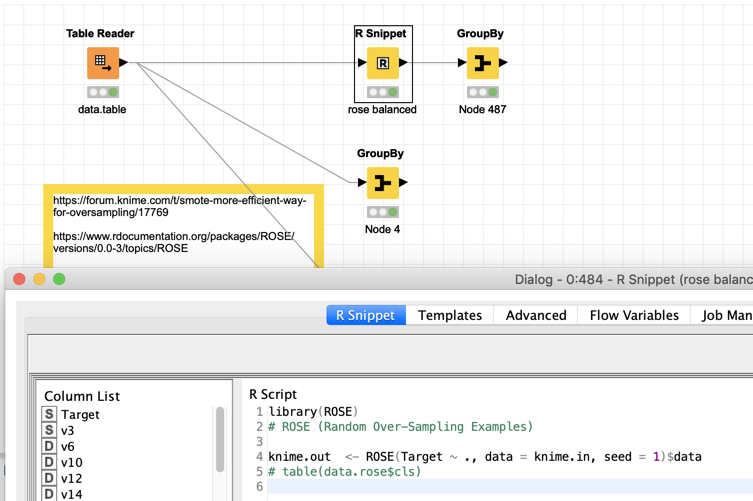
Hi, i have minor question - i am using SMOTE node to balance unbalnace data:
target class have to outcomes: 0 and 1
0 occurs in ca. 99,9% of cases, 1 in 0,01%
data set is ca. 2M of rows
i am using smote in two alternative ways: #1 - put node and configure it to “oversample minority class” #2 - put rowsplitter splitting target class - oversample “1” by smote x1000 and then concatenate what have splitted before
solution #1 is much more time consuming but gives very similar outcomes - is solution #2 proper way to use smote?
Both options are correct. So you are fine to use the faster option (#2, i.e. filter the minority class, oversample it with a fixed factor and then add it back to the majority class).
We identified the source of this performance difference and will improve the code to eliminate it in the future.