KNIME Forum Archive
SMOTE - more efficient way for oversampling
KNIME Analytics Platform
mlauber71
August 31, 2019, 10:33am
2
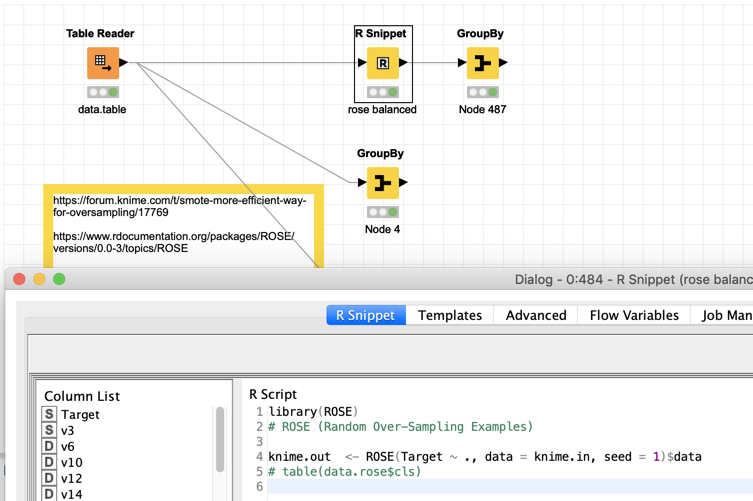
You could try your luck with R’s
ROSE
library.
image
753×501 83.7 KB
kn_example_rose_balanced.knwf
(905.8 KB)
1 Like
show post in topic