I have a complex datamodel, which I am combining via KNIME “in-database”. All data is in Snowflake (Medium sized warehouse) and we want to prepare the data w/o extracting it and eventually write the results back as a new datatable.
As far as I understand how KNIME and Snowflake function, is that KNIME collects the consecutive SQL statements from the DB nodes and forwards the assembled SQL statement to Snowflake with a “WHERE 1 = 0” clause in the end. The latter leads to the fact that no data is actually recieved, but just the raw SQL statement is communicated to the Snowflake.
Yet, I recognized that for a longer pipeline, i.e., several consecutive DB nodes the process at some point slows down. One potential explanation could be that the SQL string gets longer and longer and this info must be transmitted to snowflake and it slows down due to the length. I also tried the “unnest” option in the Snowflake connector (KNIME version 4.7) to slim down the SQL statement, which did not improve the performance. This makes me doubt my hypothesis that performance correlates with the SQL query length.
Any idea how to improve performance in longer ELT pipelines? Please find attached the recorded workflow, some descriptions and the parametrization of the snowflake connector
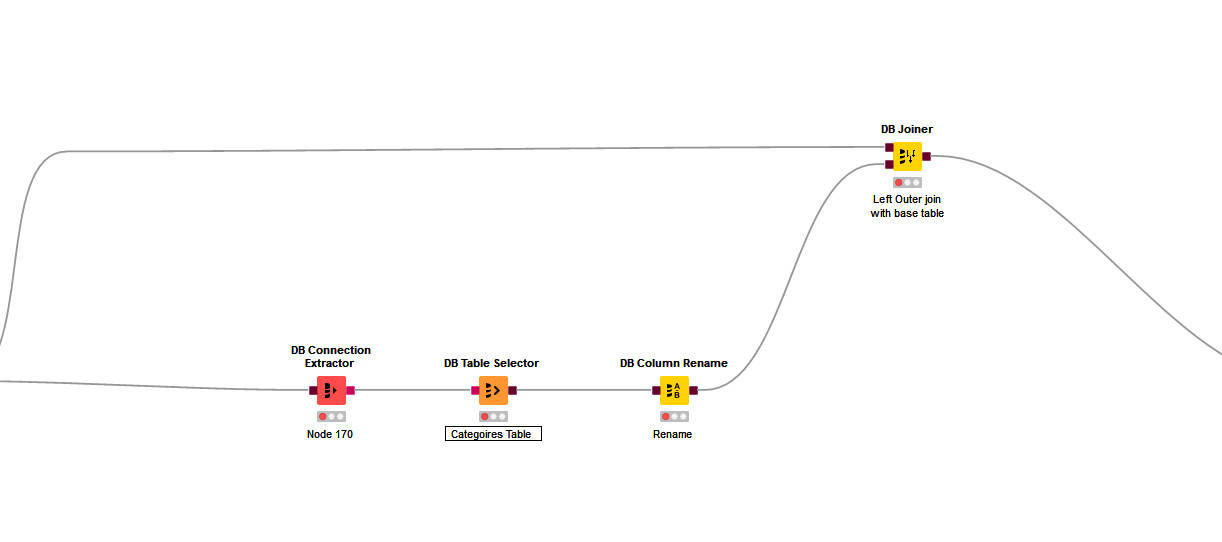
The workflow:
Inside of a Metanode (master data table gets joined to the base tables. Choosing serialization over parallelization for better readability. I noticed that snowflake is not the strongest with parallelization as well.)
I digged a bit deeper given my little knowledge about Snowflake.
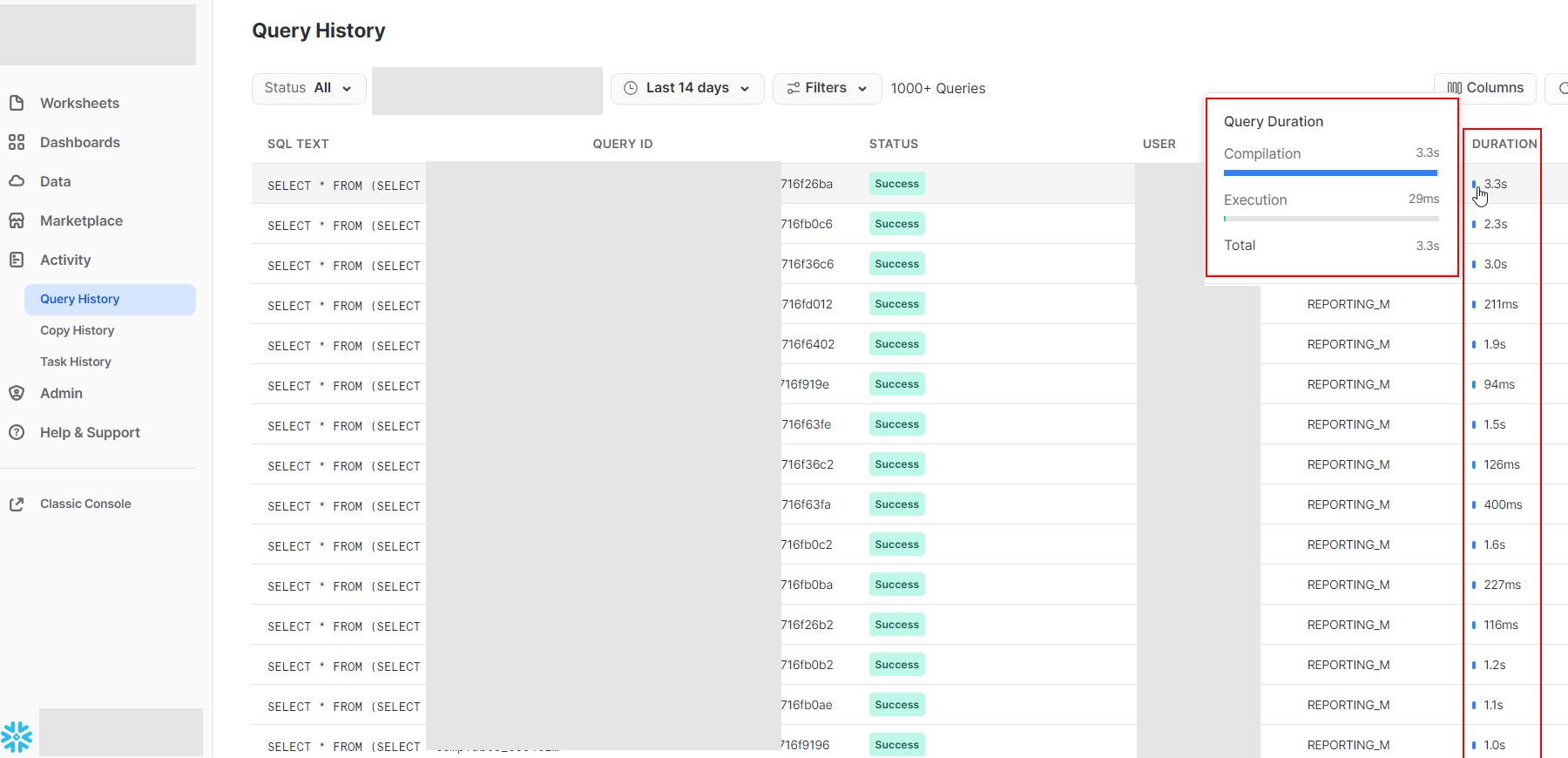
The query compilation on the snowflake side takes longer and longer the “heavier” the query becomes.
See attached screenshot:
I found a reference regarding this on the snowflake side:
One issue for this workflow might be the amount of objects (lots of master tables to be queried and joined eventually to a “transactional table”).
Interestingly, doing the same task on a legacy MS SQL database performs much faster.
Regarding “nestedness”, I am still not sure if that is the actual issue. As mentioned above, I gave it also a try with KNIME 4.7. and checking the unnest option in the Snowflake connector, with no success.
If anyone has still ideas, how to optimize the runtime, please let me know!
BR,
Stiefel
hi @Residentstiefel ,
As per the internal communication on the use of Snowflake nodes, parallelization will work using multiple Snowflake Connector nodes. Otherwise, parallel branches will wait for the single Snowflake Connector node’s single DB connection.
Thanks, I will give it a try.
The problem here is though: the whole ELT workflow is wrapped into a database transaction, i.e., we have a transaction start and end node wrapped around it. The DB transaction nodes have only one input port for the snowflake connection.
I could think of two strategies:
Either wrap the three branches into three different transactions and the join of the results will be another transaction
Somewhat use several Snowflake connectors within the one database transaction
I would need to play around a bit, to see how it could work. I would prefer something in the direction of 2) to keep it simpler
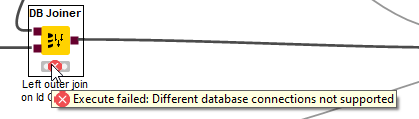
I tried to spin up three more snowflake connectors, to have 4 connectors in general - for every “base table” branch one. This is much faster, but unfortunately, I am not able to join the results, due to the fact that there are now different database connections involved.
I guess a solution to that would be to write temporary tables into snowflake and then join the results?
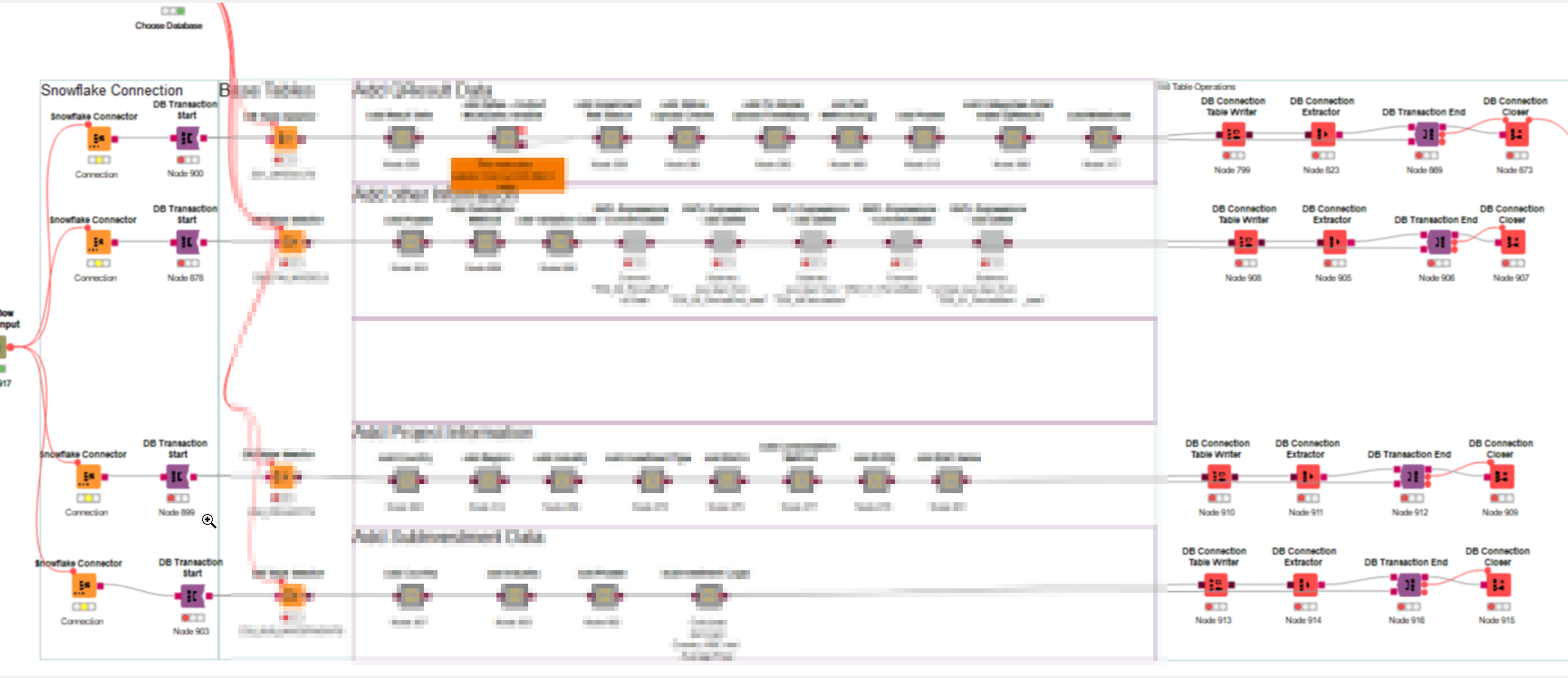
We ended up with solution number 1 (wrap all (actually now) 4 branches into seperate transactions).
I was not able to find a solution spin up several snowflake connectors within one DB transaction.
It currently looks like this: