Hi @bruno29a Thank you for the suggestion. I just have a small query here, so from the first screenshot, please correct me if I’m wrong, does connecting the excel sheet appender sequentially using a flow variable, execute the nodes in the sequential order? Is that the idea behind using flow variables here? Do I have to be changing anything in the flow variables tab in the node as well?
Thank you!
Hi @Saishiyam , that is correct. When you link them with the flow variable like this, it will make the linked nodes run sequentially. For example, in my latest screenshot, WRITING DUMP cannot run until Excel Writer of Node 8 is done, and similarly, ETL 2 cannot start until WRITING DUMP is done, etc, etc
Or from my first screenshot, the 4 Excel Writer will run sequentially, one after the other, in the order of Node 8, WRITING DUMP, SUMMARY, and WRITING LOGIC
Nothing to change in the flow variable tab
1 Like
Thanks! @bruno29a. But unfortunately, even after using Heavy garbage collector, my KNIME crashes resulting in heap space error ![]() .
.
Hi @Saishiyam , I’m sorry to hear. Can you tell us after which Excel Writer it crashed?
And can you also show us the modified workflow?
Hi @bruno29a This is how my workflow looks like
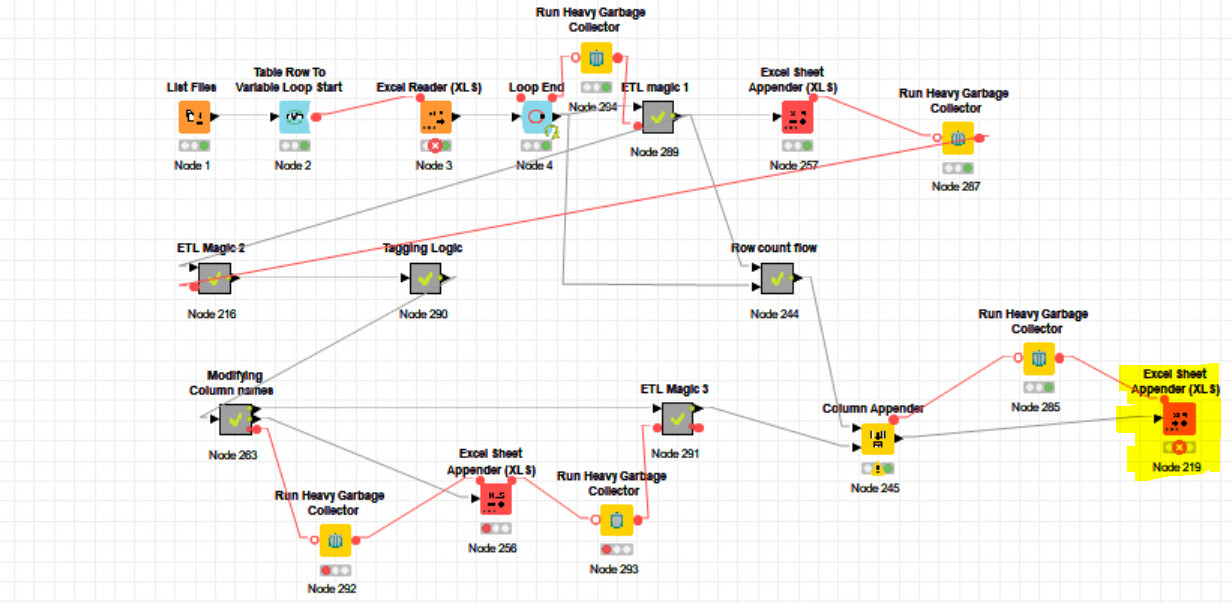
Only the first excel sheet appender has run and the file size is 19 mb with that alone. Do I have to be changing anything else here
The Garbage Collector nodes doesn’t help you at all in such cases. The Java runtime will invoke the garbage collector on its own if free memory falls below a certain threshold. In fact in 99,99% of all cases there is no need to invoke the garbage collector explicitly.
Hi @Saishiyam did it fail because of memory issue? It looks like the Column Appender (Node 245) before the Excel Sheet Appender is empty. Could it be that it complained/failed because there is nothing to write?
1 Like
@Thyme @bruno29a
Can you guys elaborate on why you prefer sequential (connecting flow variables) instead of concurrent? For memory issues it seems a good suggestion but otherwise I would see it as a deceleration of the execution?
Thanks
Have you tried store it in a different format first, e.g KNIME tables and only at the end convert it to excel? Just a random guess
br
yes, it’ failed because of memory issue @bruno29a . I’m using the column appender just to append the pivot and Row count together, as it needs to be in the excel sheet as well.
@Saishiyam , this is weird, it’s only 19mb? How can you be running out of memory?
Can you try to do just a few lines and see if it works? Just add a Row Filter somewhere and just do like a few lines, and try again and increase the number of lines and see where it fails?
@Daniel_Weikert , I had not noticed that @Thyme had also suggested sequential execution. On my part, the reason is that most probably memory is use to buffer some data before writing, therefore is there is concurrent writing, more memory might be used as opposed to sequential.
@thor , I would agree with you in theory. However, I’ve seen huge difference when using the Garbage collector. Basically in one of my workflows, I generate a few series of about 7 million random numbers on average for each series, and my system would become quite slow to use even after the workflow is completed. Running the Garbage Collector seems to free up the memory and my system becomes “normal”. So I added the Garbage Collector to the workflow within the loop, after each series of 7 million random numbers.
1 Like
@bruno29a The compression requires a lot more memory than the final file size. In my first post I mentioned some “testing” to show the difference (factor 200ish between file size and heap space usage).
@Saishiyam You mentioned that you have a KNIME Server, why are you not running the workflow there? Your machine with 8GB memory isn’t really up to the task. If your employer isn’t getting you stronger hardware, that might be your only option.
@Daniel_Weikert You’re right, I suggested sequential execution because of the severe memory constraints of OP. But apart from that, I generally write to the same file sequentially. Anything else I parallelise for execution speed. Never bothered to find out whether or not KNIME can handle it.
@bruno29a If your system feels sluggish when KNIME uses a lot of memory this indicates that it’s starting to swap memory to disk. In this case you should reduce the heap space size that you provide to KNIME via the knime.ini.
Still, invoking the garbage collector explicitly does not help you in any way if there is not sufficient memory to fulfil a certain task.
Hi @Thyme , yes we do have a server, I guess that’s the final option right now.
@bruno29a I tried to group the files country-wise and process, that seems to work for now. But I feel that it would throw the same error if the row count is more in some cases.
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.