Hi,
I’m using KNIME version 4.1.1, with allocated RAM of 4GB (Total RAM in machine is 8GB).
When I try to write large number of records using excel sheet appender, it keeps throwing the Java heap space error. Tried changing the memory policies as well, but doesn’t seem to help out. Is there any other solution for the same? Any help would be appreciated.
Thanks!
1 Like
@Saishiyam how large is the data of you just write it to a KNIME table. How large is the Excel file if you say append.
Have you tried 6 GB? Leave some for the system.
Try a workflow that just does the export and utilize Garbage collection. Cache the data before export.
You could try a newer KNIME version although there seem to be problems with the very latest version of the Excel writer. So maybe look for version 4.5.3 and a solution to this ticket.
Next thing could be to try R or python openpyxl.
5 Likes
Hi @mlauber71
The file is only 35 mb, but I have no idea why KNIME struggles so much to write it. Also, I haven’t tried 6GB yet, I’ll try that.
And also we were advised not to use R or Python as it might cause troubles while deploying it in KNIME server.
As of now I’ll try the cache and the RAM method as mentioned by you and will let you know if it works.
Thank you so much!
In addition to what @mlauber71 has already posted:
- The Excel Writer has to read the entire workbook when appending a new sheet. This is why repeated appending gets increasingly slower. It also means that KNIME needs more and more memory to keep appending sheets.
- Since KNIME AP version 4.3 the Excel Writer can also write multiple sheets at once, using dynamic input ports. If you’re not appending sheets from within a loop, you can connect multiple tables to the Excel Writer. It saves nodes (+ configuration) and several read/write operations.
- XLSX files are actually zip files. While your file might be only 35MB on the disk, keeping it in memory (uncompressed) requires a lot more memory. I just tested appending a 1.5MB sheet to a 16MB XLSX file and the heap space used went up by at least 3.5GB. If you can’t get it to work, maybe you can do with mulitple XLSX files instead? Or use CSV files, those are memory friendly, but use more disk space.
3 Likes
Hi @Thyme
The thing is that this sheet would be used by the stakeholders and it has to be in a single excel file with multiple sheets in it, as requested by them. Also we can’t update the version as 4.1.1 is being used by everyone throughout the org.
By the way can you please let me know how do you check the heap space memory being used please? Would be useful for me ![]()
You can find that setting under File → Preferences → General → Show heap status
It will then show the current reserved and the used memory in the bottom. The garbage bin let’s you do a manual garbage collection.
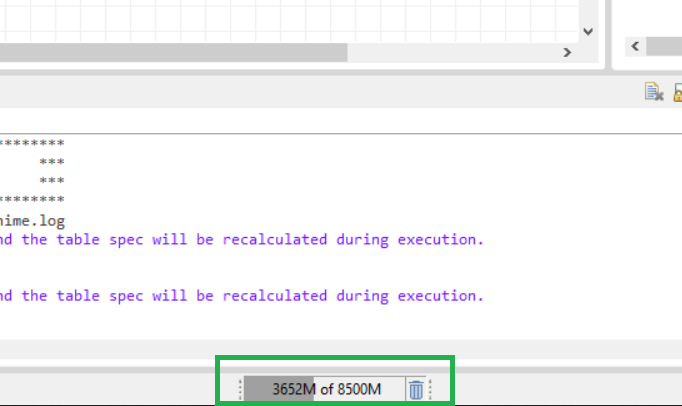
By default, it will show the reserved heap space as 100%, and the used heap space as grey bar. You can also set it to “Show Max Heap” (right-click on it), it will then show the max allowed heap space as 100%, the used heap space as grey, and on top of that the unused heap space as yellow.
4 Likes
@Thyme Oh got it, thank you. I just tried running it again, the heap bar just goes red (occupies it fully) and then my KNIME crashes .I need to look for some other way I guess.
I guess you can’t remove redundant information to reduce the file size? Kind of obvious to ask, but I want to make sure.
You also mentioned a KNIME Server. Are you only building and testing the workflow on your machine? Since the Server should have more RAM, can you use a reduced data set on your machine and then export the unrestricted workflow to the Server?
Hi @Saishiyam is there any way where you can run the Garbage Collector somewhere within your workflow? This can help free up memory during the workflow.
There are 2 Garbage Collector nodes from the Vernalis extension that can help. I use them sometimes in my workflows.
If you can share your workflow - even a screenshot, we might be able to advise where you add it.
3 Likes
Hi @Thyme, no we are not allowed to remove any information as it is being reviewed by other team and further tagging would be done by that team.
And yes, currently I’m building it on my local machine, I tried with reduced data set as well, by splitting the data into groups. But still, I keep getting the heap space error. I think the only option is to test in the server directly, right?
Hi @bruno29a Thank you for the suggestion, I’ll try running this node in my workflow.
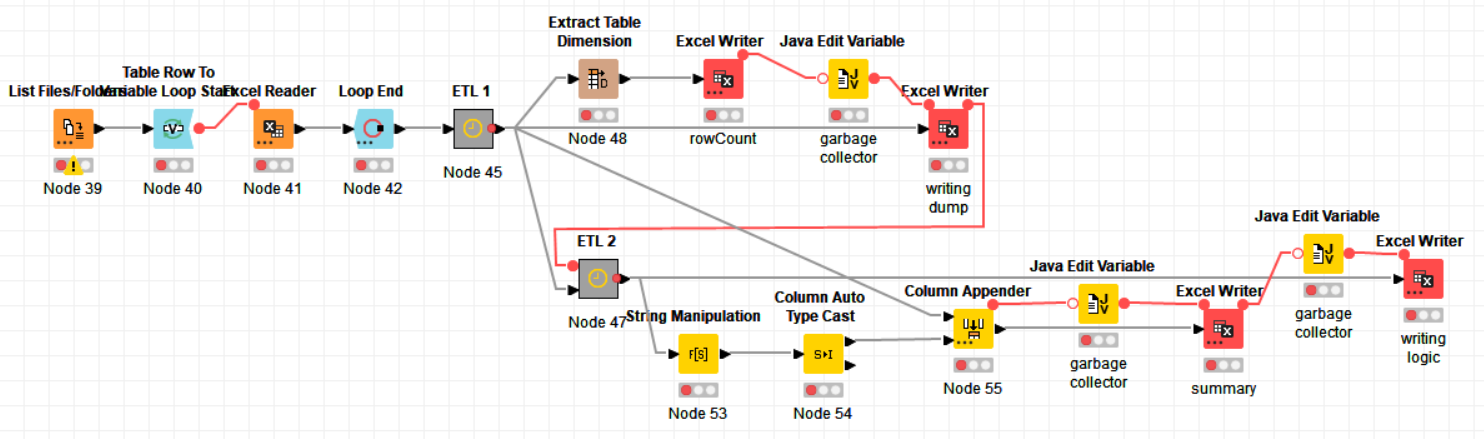
I’ll try to attach a replica of the original workflow.
Hi @bruno29a, I have multiple excel sheet appender nodes being used in my workflow. So before each and evrytime that node is being run, should I be attaching the heavy garbage collector node? IS that how it’s supposed to be done?
Hi @Saishiyam it’s hard to tell without seeing your workflow. You can try adding it somewhere after heavy processing has occurred.
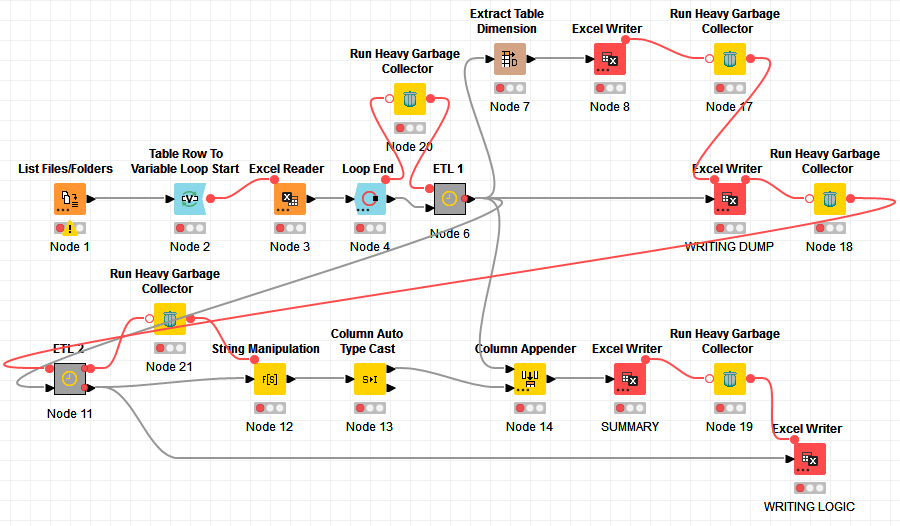
Hi @bruno29a, this is a replica of my workflow. The excel sheet appenders inside the workflow annotation are the ones where large amount of data is bein written. Should I have to fit the garbage collector once I write the first sheet? Is it supposed to work like that?
Attaching the screenshot for reference:
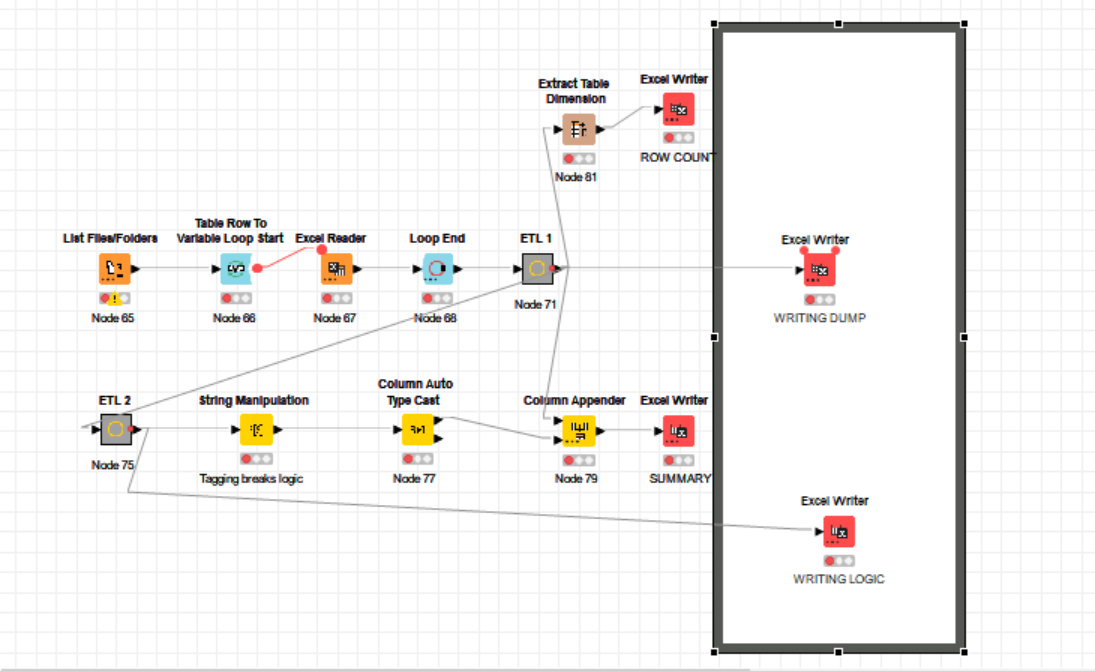
Thanks!
I see you’re not appending from within a loop, so you could also write the entire file at once. Click the 3 dots on the Excel Writer Node to add additional table inputs.
The garbage collector comes directly before the Excel Writer, with a Merge Variable node to ensure all preceeding nodes are executed before the garbage collection is run. You should also make sure that no other workflow is open, no other nodes are executing, and no other application is running on your PC.
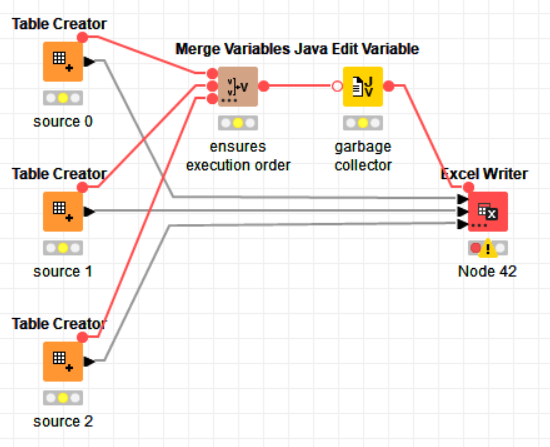
1 Like
Hi @Thyme, actually we are using Knime 4.1.1 where that option isn’t available, plus I’m using the excel sheet appender node. The screenshot which I Shared is the latest version whereas in my VDI it’s 4.1.1
Can the same be followed there?
Thanks!
Sure, but it’s not as efficient. Something you should always do is to have nodes that write to the same file execute one after another. You can do that with Flow Variable connections.
The execution order also determines the order of the sheets. You can rearrange the nodes if you need a different sheet order.
3 Likes
Hi @Thyme, Thanks! I’m trying to use the heavy garbage collector, so will it be same as this? Is it supposed to be connected between two excel writers only? or can it be connected to any other proceeding nodes as well?
Thank you!
Hi @Saishiyam , I don’t quite remember how the Excel Reader behaves in Knime 4.1.1. Is it appending the data of each Excel file to one table inside the loop?
What I would do is probably add a Garbage Collector after the Loop (so before the ETL 1) and perhaps have the Excel Writer be sequentially executed (one after the other) instead of in parallel and use the Garbage Collector between each Excel Writer.
I’m not sure what your ETL 1 and ETL 2 do, but if they’re doing some heavy work in memory, you may want to run the Garbage Collector after their execution too.
I think executing the Excel Writer sequentially could be enough though. Try this first:
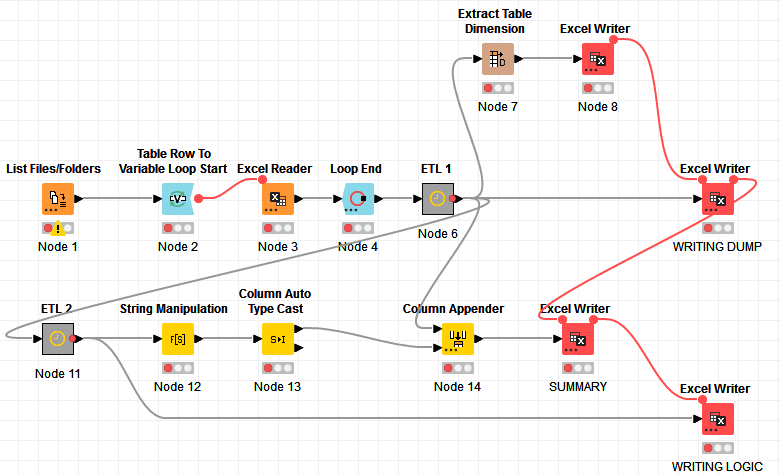
If this alone does not work, you can add some Garbage Collector in between, like this:
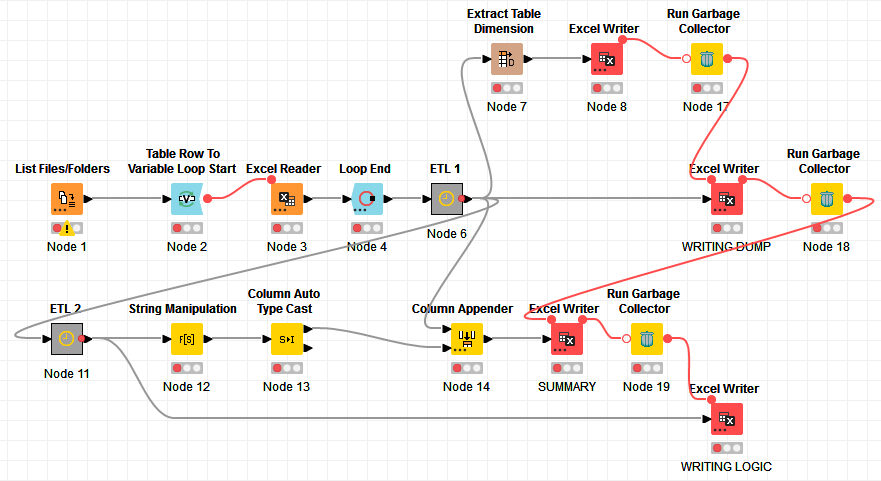
You may try using “Run Heavy Garbage Collector” instead too.
EDIT: Here’s the extreme case: