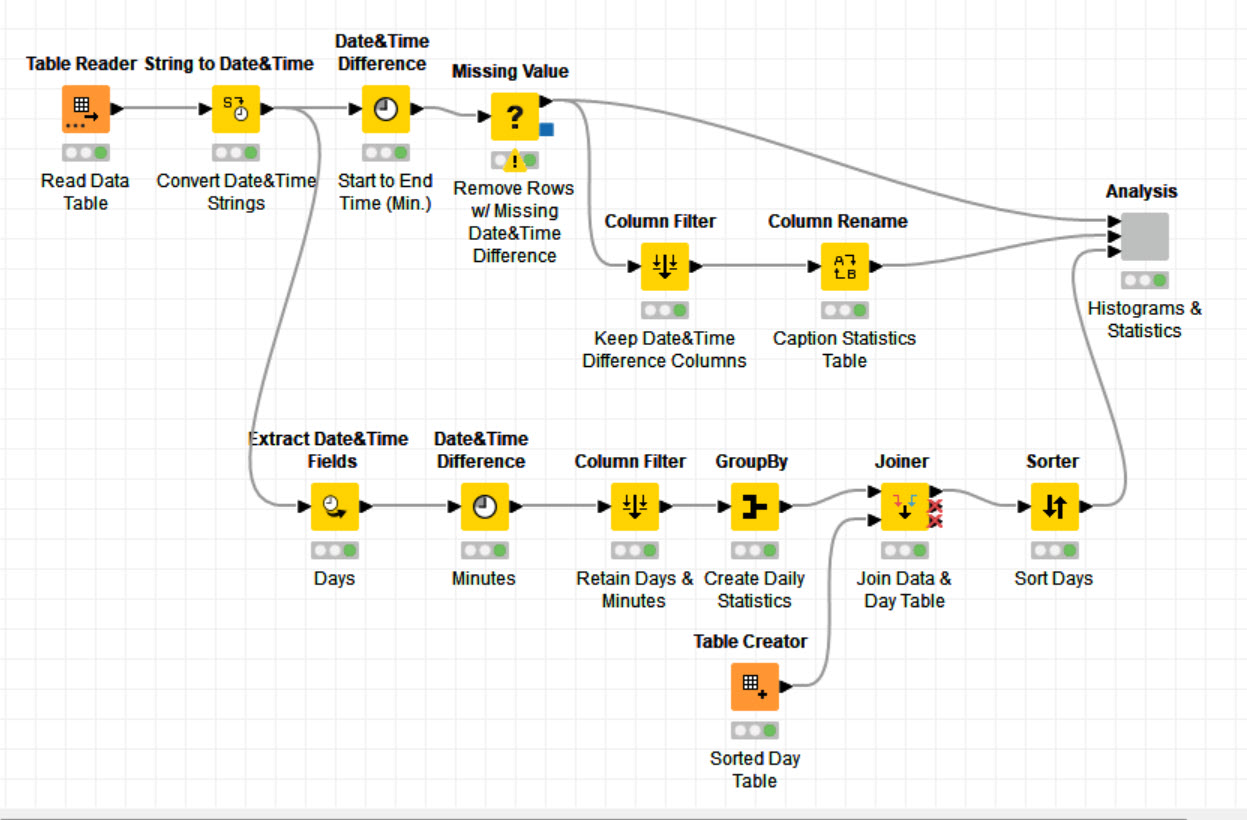
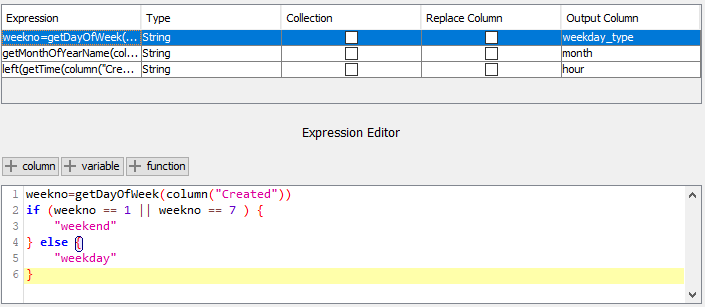
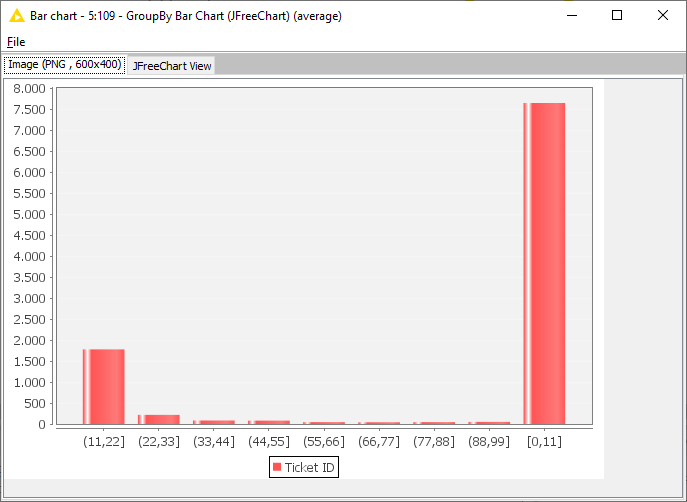
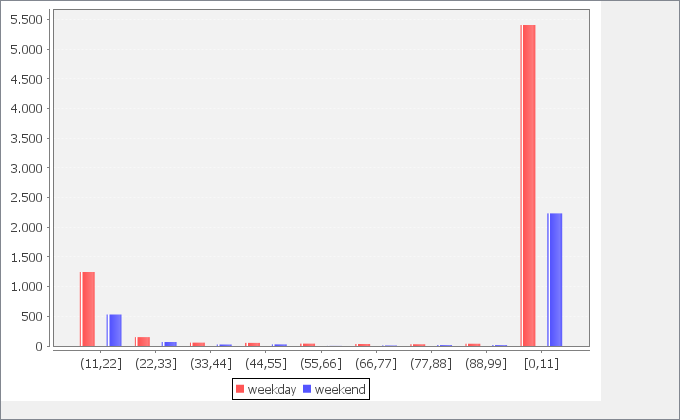
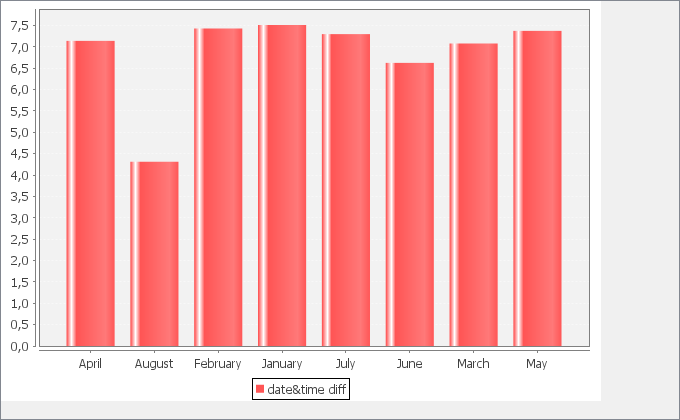
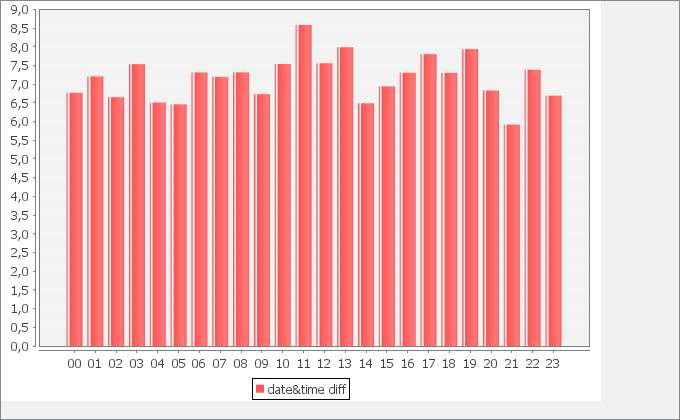
I made computations considering the difference between closing and opening date. This is right, but there should be another measure that excludes holidays, Saturdays and Sundays. I found a way to do it in Python (which I can’t use) and another one in R, but the latter works only with date (not datetimes). I was not able to implement it yet. Maybe I can try to do it in the following days.
Hi everyone,
Here is my solution:
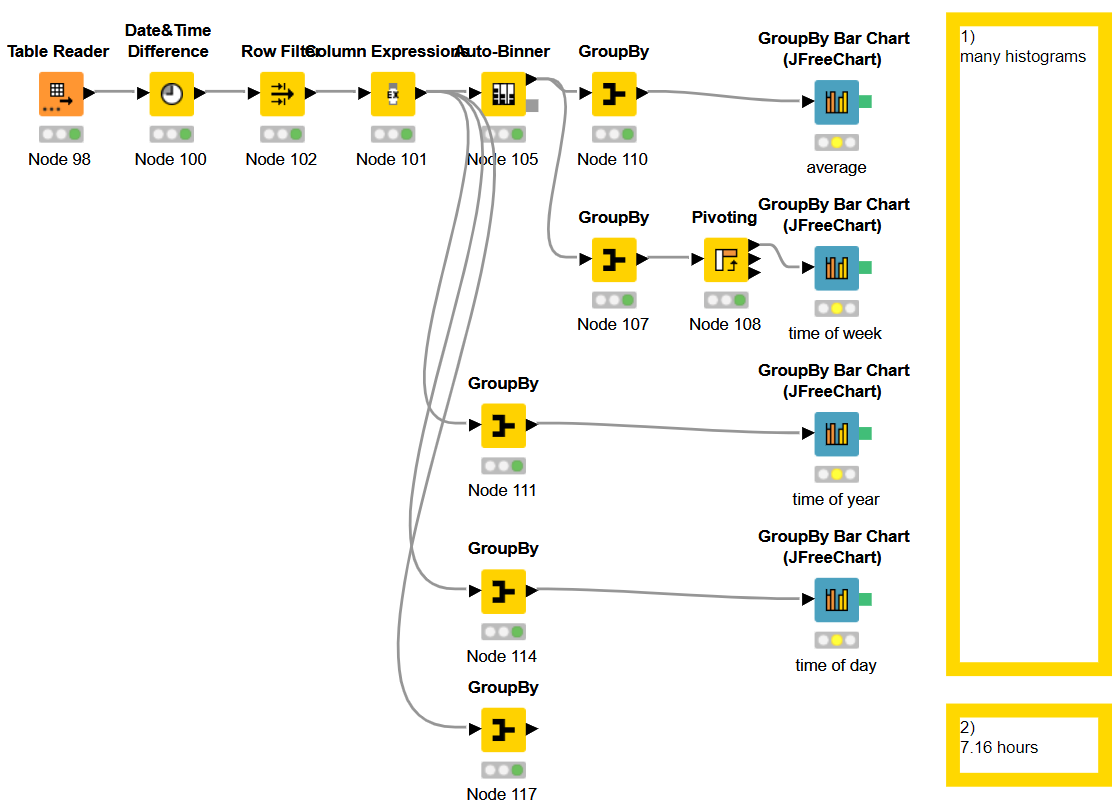
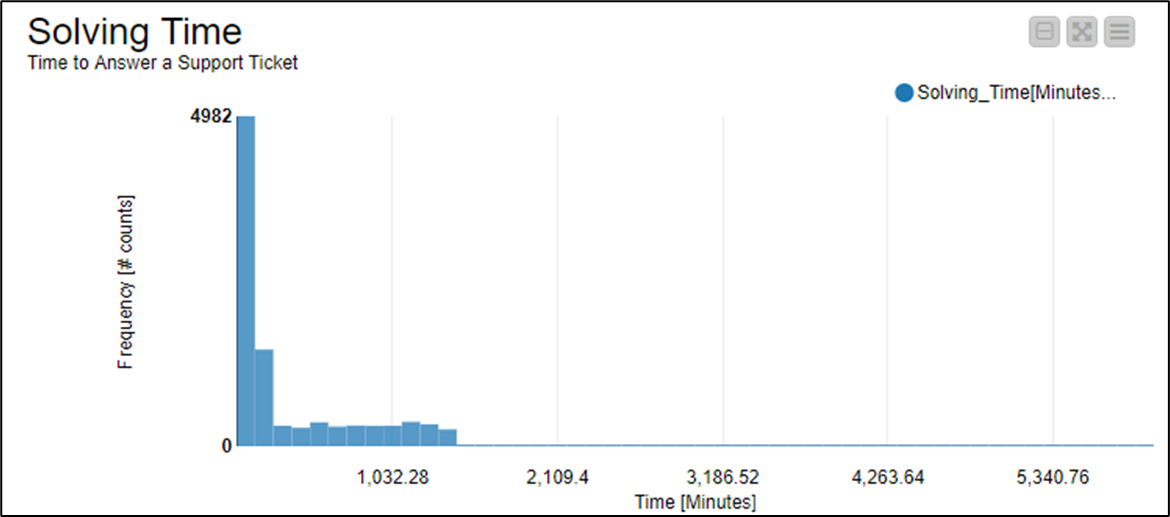
For visualizations I used 1 histogram and 3 text output widgets for total ticket count, open ticket count and mean ticket duration time (minutes).
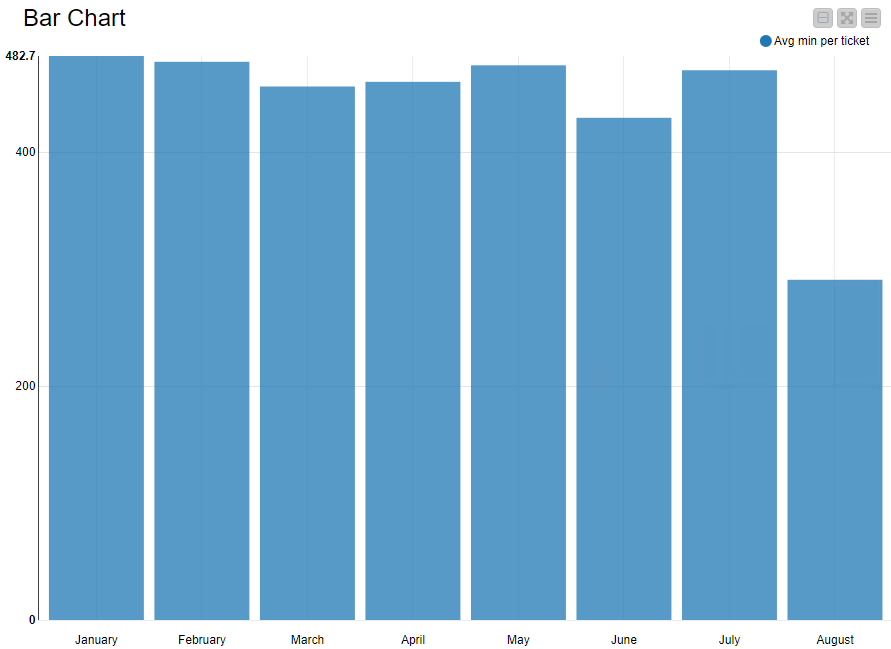
Task (2) As in the rest of answers, I’ve tested to calculate the means on different granularities. In the same way, only monthly averages give some feeling of trend…
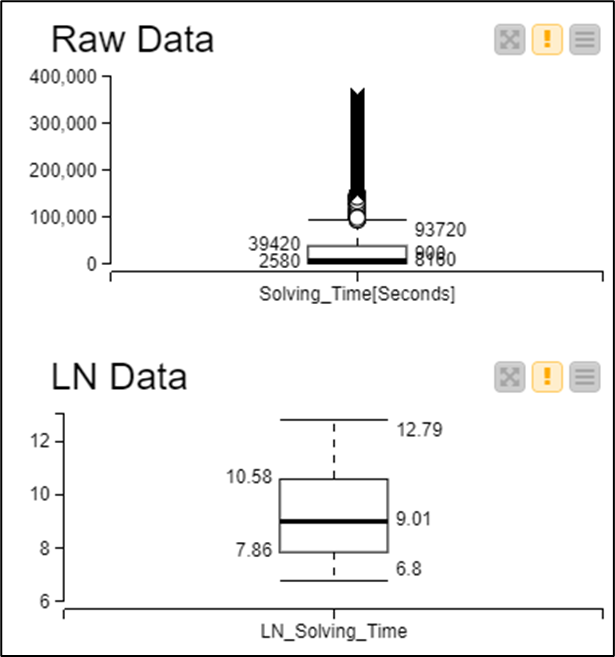
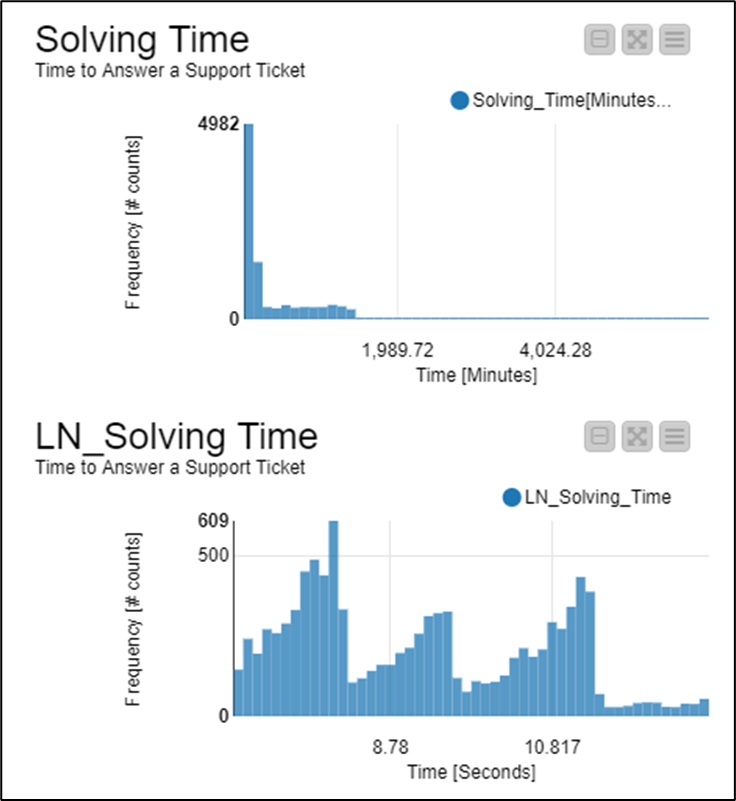
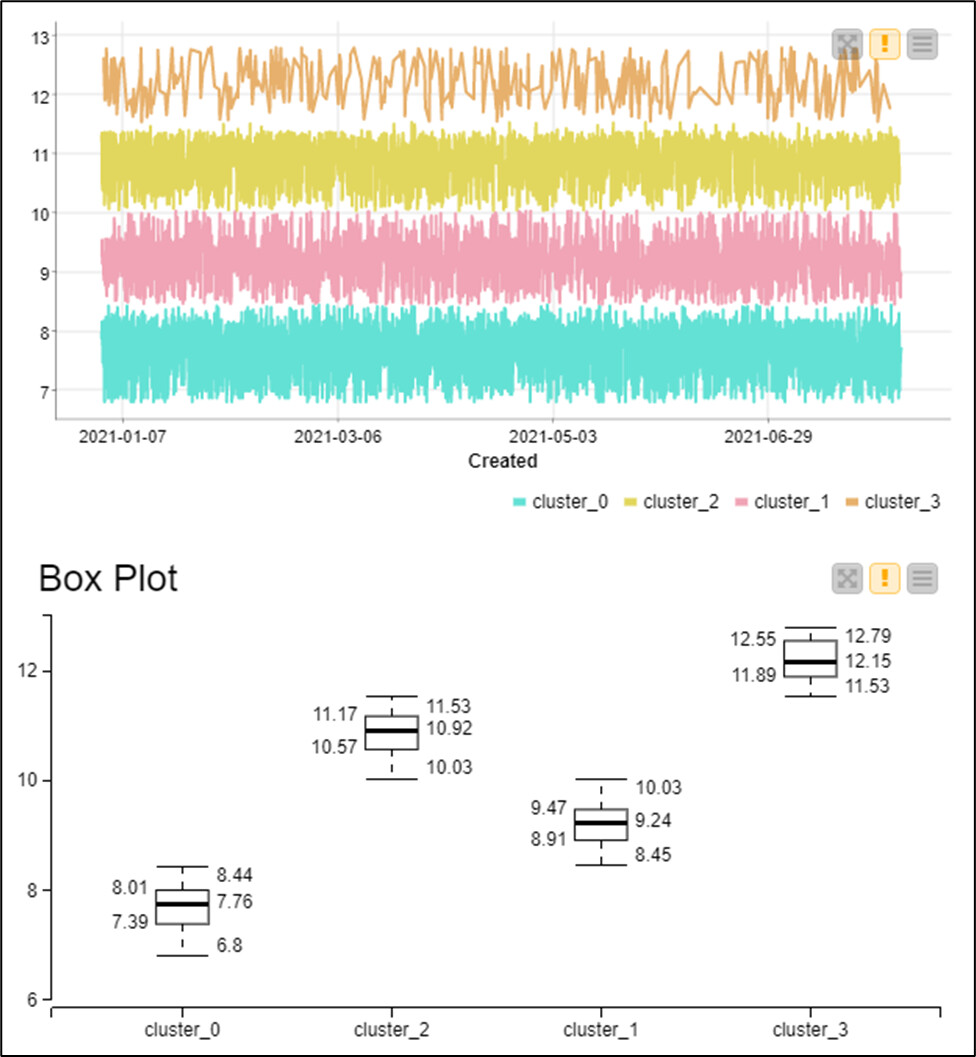
Moving forward on histogram analysis, displaying the histogram as LN values of time in seconds gives a better scale for the analysis, and a straight forward method to deal with like-outlier values in decimal scale. This chart shows box plots for Solving Time [Seconds] plotted in decimal vs. LN
Representing the histogram as the LN of solving time in seconds, it shows a better scale for analysis… however histogram frequency plot shows a tri-modal distribution.
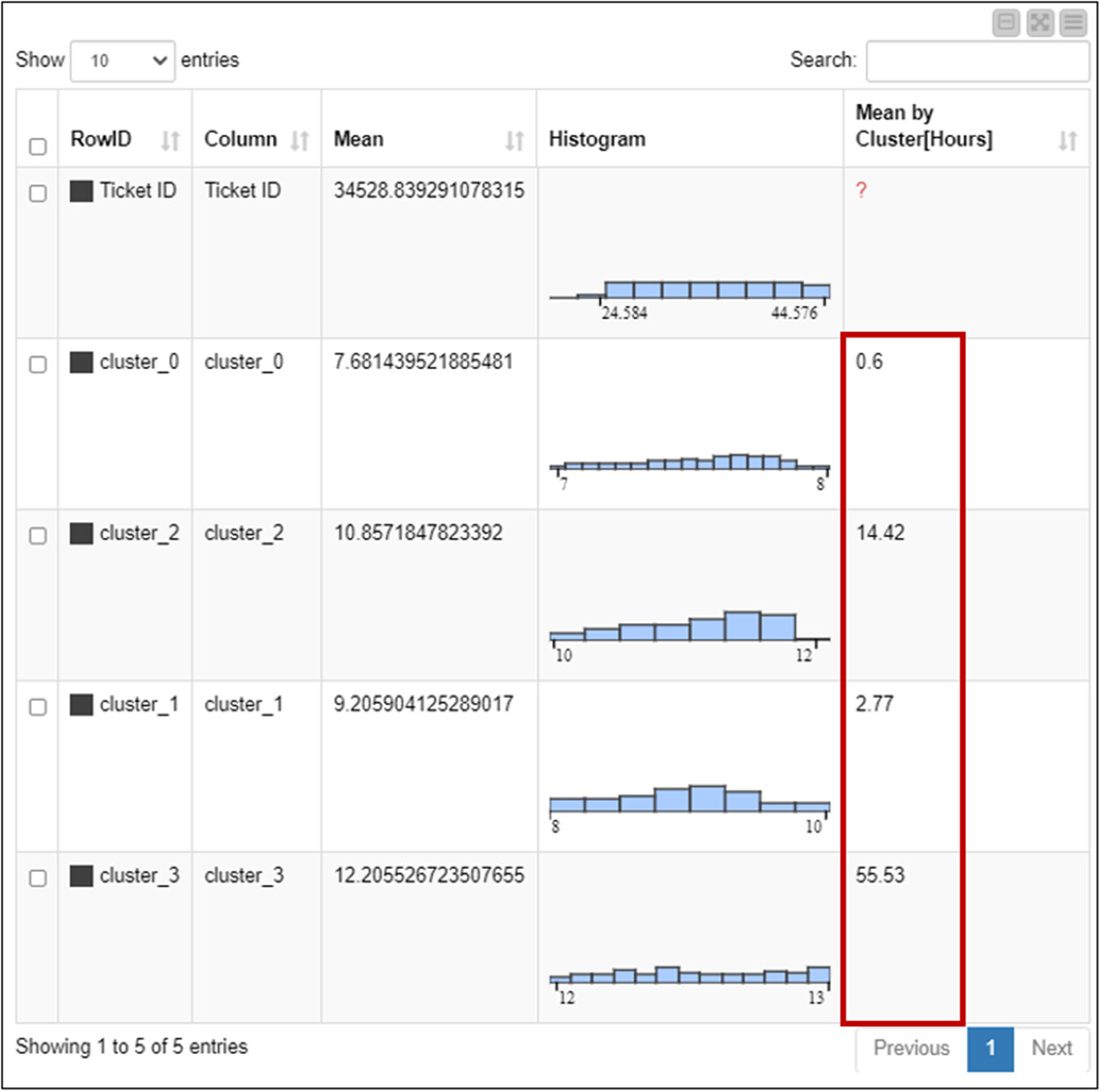
It is hard to move forward on this based on a single parameter; I’ve decide to assume 4 Ticket families with different Mean value in solving time. I ran a clustering based on a single parameter ‘LN_Solving Time [seconds]’ (!)
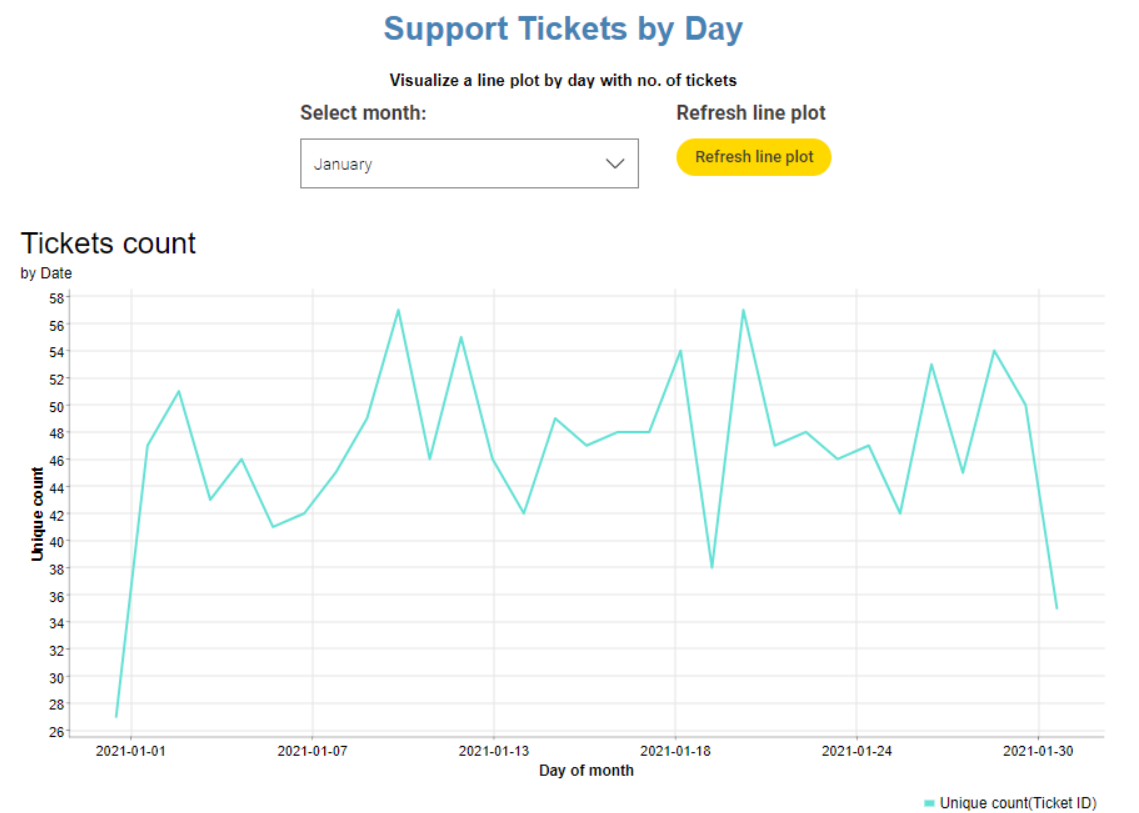
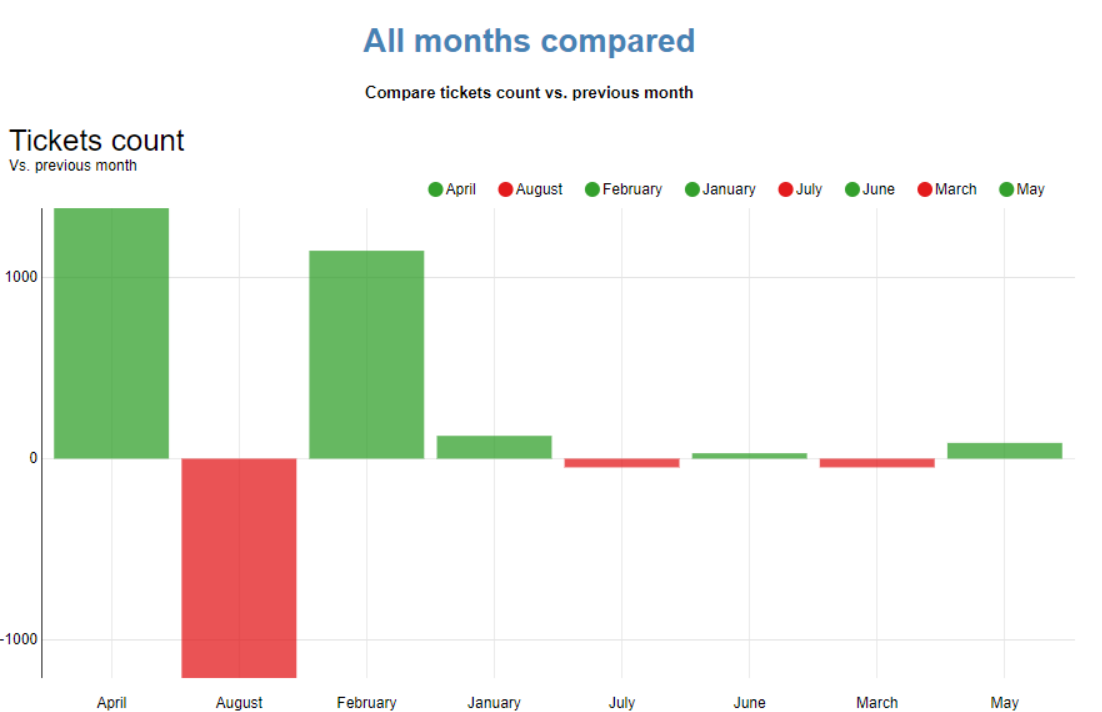
my approach for this challenge. Besides calculating the required measures I wanted to play around some more with a couple of visualizations that I always fund useful. Trend lines and month vs month comparison.
As you can see, we kept it simple: no assumptions regarding weekends or holidays, and we also did not use metrics that are more robust than the mean given how the data is distributed. Indeed a baseline for the problem — and we are so happy to see how you folks built way more complex solutions!