This week we focus on XAI (we know you like this topic!) in the context of a real estate problem. Are you up for the challenge?
Here is the challenge. Let’s use this thread to post our solutions to it, which should be uploaded to your public KNIME Hub spaces with tag JKISeason2-13.
Need help with tags? To add tag JKISeason2-13 to your workflow, go to the description panel on the right in KNIME Analytics Platform, click the pencil to edit it, and you will see the option for adding tags right there. Let us know if you have any problems!
I’m definitely in the deep end of the pool, but here’s my try. It would be nice in the future if we could get a data dictionary for the column headers. A lot of the abbreviations mean nothing.
Maybe the following information gathered from different sources can help:
The Boston Housing Dataset is a widely used dataset in machine learning and statistics, particularly in the field of regression analysis. It was first introduced in 1978 by Harrison, D. and Rubinfeld, D.L. as part of a study on housing values in the Boston, Massachusetts area.
The dataset contains information on various factors that are believed to influence housing prices. The goal of the study was to analyze the relationships between these factors and the median value of owner-occupied homes in different suburbs of Boston. The dataset consists of 506 observations and 14 attributes.
The attributes in the original dataset include:
CRIM: Per capita crime rate by town
ZN: Proportion of residential land zoned for lots over 25,000 square feet
INDUS: Proportion of non-retail business acres per town
CHAS: Charles River dummy variable (1 if tract bounds river; 0 otherwise)
NOX: Nitric oxides concentration (parts per 10 million)
RM: Average number of rooms per dwelling
AGE: Proportion of owner-occupied units built prior to 1940
DIS: Weighted distances to five Boston employment centers
RAD: Index of accessibility to radial highways
TAX: Full-value property tax rate per $10,000
PTRATIO: Pupil-teacher ratio by town
B: 1000(Bk - 0.63)^2 where Bk is the proportion of Black individuals by town
LSTAT: Percentage of lower status of the population
MEDV: Median value of owner-occupied homes in $1000s (the target variable)
The dataset has been used extensively for regression analysis and predictive modeling tasks. It has provided a valuable benchmark for evaluating the performance of different machine learning algorithms, especially those used for predicting housing prices.
Over the years, the Boston Housing Dataset has become a popular choice for teaching and learning purposes due to its relatively small size, well-defined attributes, and real-world applicability. It has served as a foundation for many studies and research papers in the field of data analysis and machine learning.
The Boston Housing Dataset was used in a machine learning and regression competition hosted on Kaggle 5 years ago and complementary information can be found at this link:
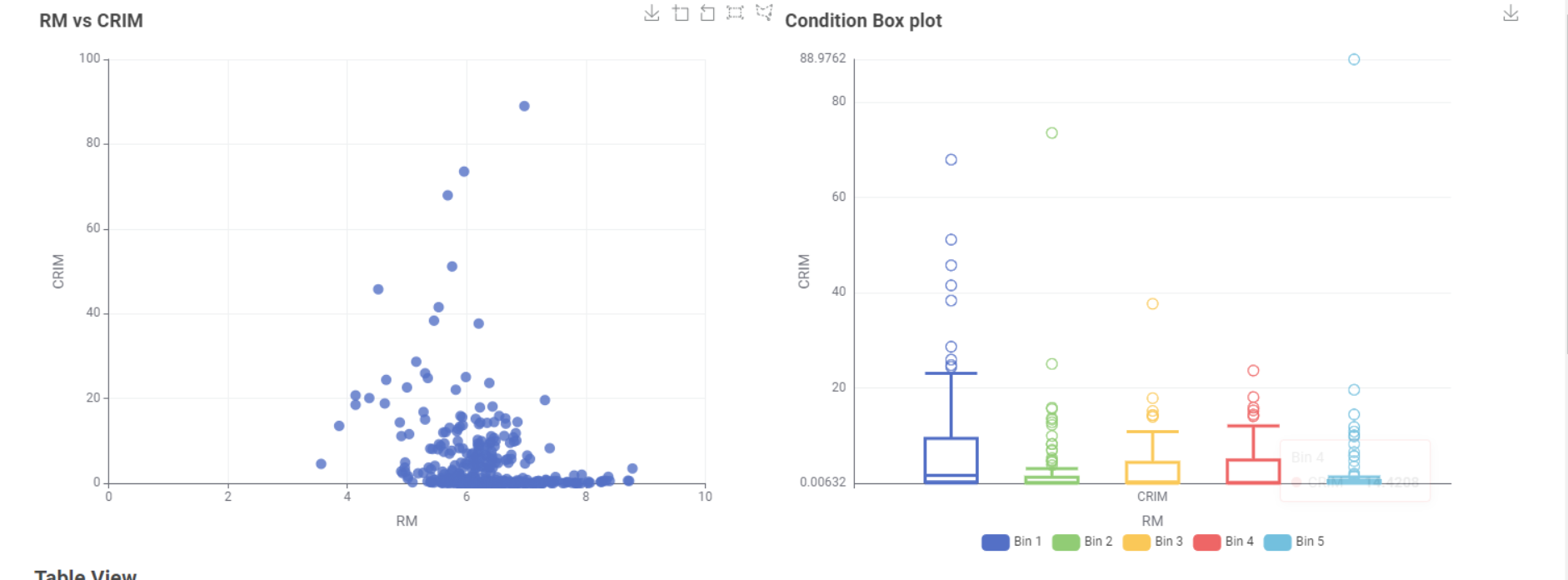
Basic visualization (scatter plot and conditional Box plot) is used to analyze the basic relationship between the two features.
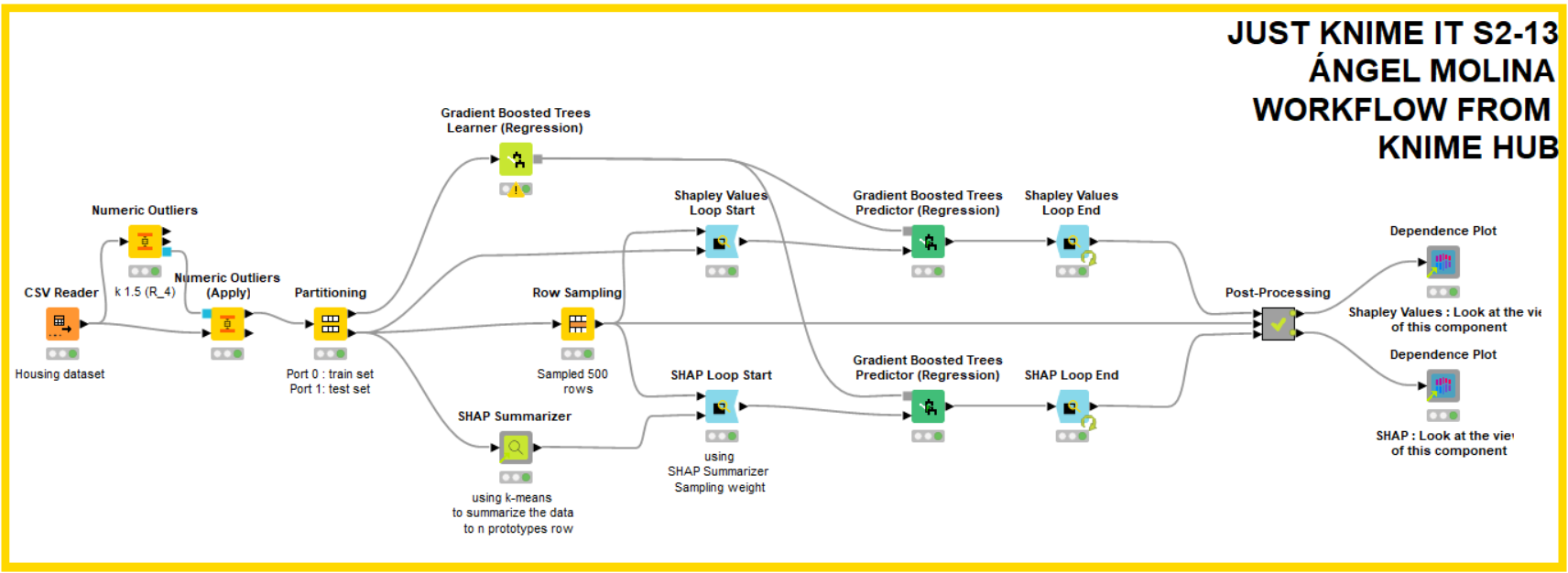
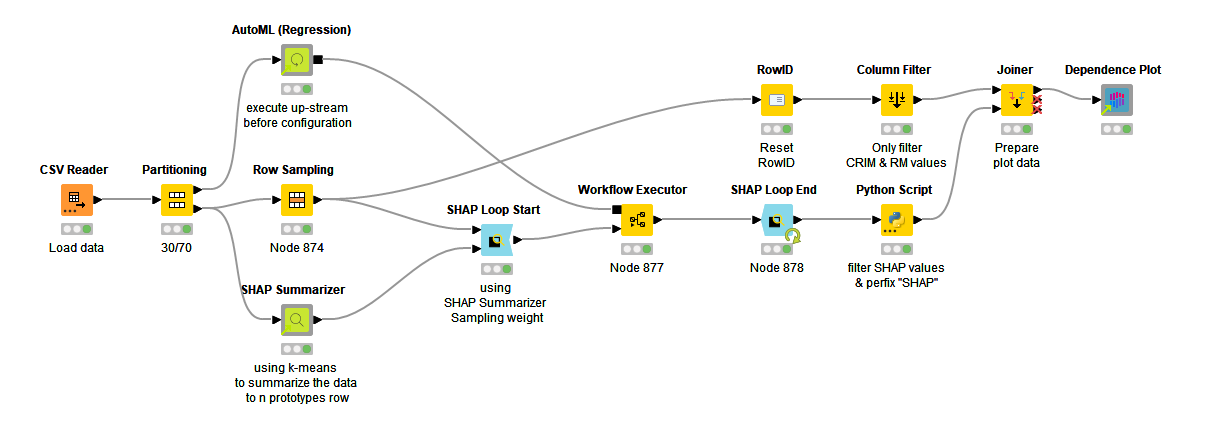
Referring to knime examples, based on setting the prediction target (housing price) and establishing a model, we used the SHAP value analysis.
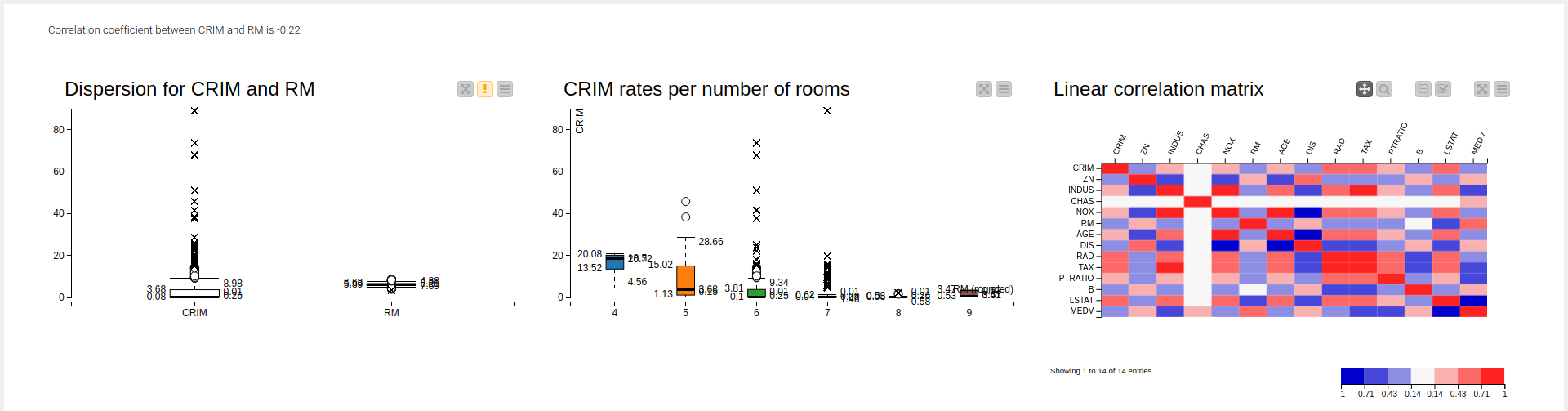
From the perspective of the overall sample, the sample with high crime rate is relatively small, resulting in Outlier on the Box plot. Only when the number of rooms is small, the median of the crime rate is slightly higher (Bar1)
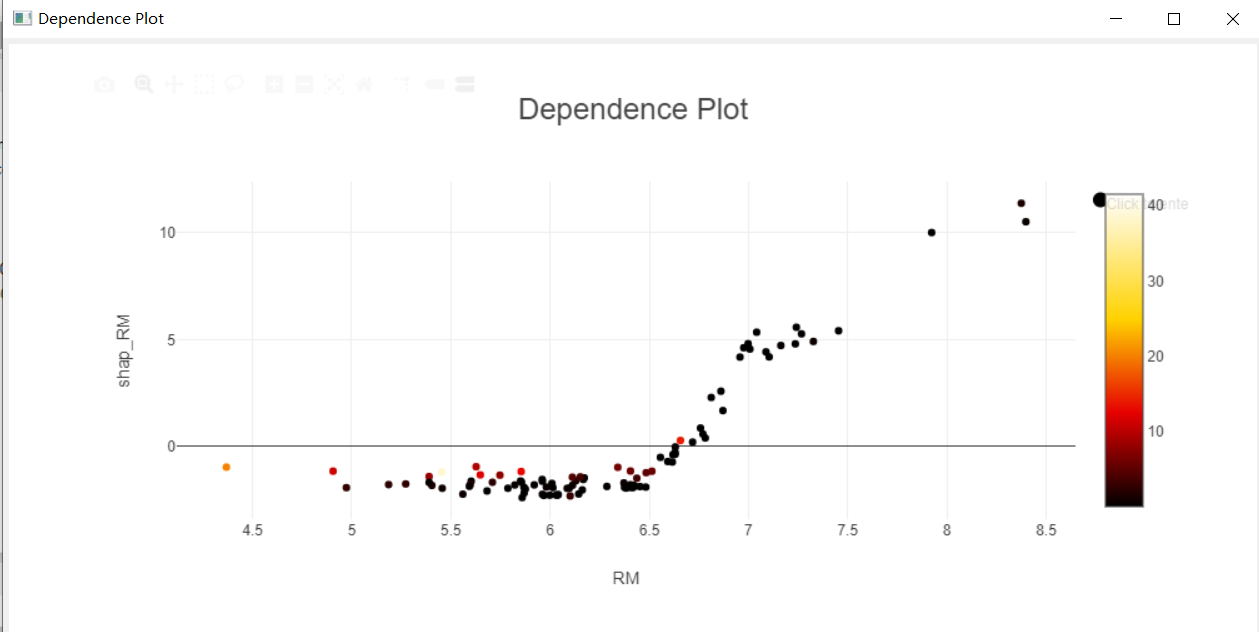
The shap value can analyze more details, and the dependency graph can have three dimensions. Generally, the x-axis is feature 1, the y-axis is the shap value of that feature, and the third dimension represents feature 2 (or target) with color.
Nothing new, I take an example in the KNIME HUB as my colleague @tomljh
I have checked it and it worked perfectly. I have preferred don´t touch anything, it´s perfect for this challenge. I have just added the missing values nodes.
Here is my solution. It is not ingenious at all, I just took the example workflow as many here did and tried to customize it a bit.
I also have done some preliminary analysis:
the correlation coefficient between CRIM and RM is quite low;
the dispersion for RM is not that big comparing to CRIM;
as @tomljh suggested I also tried to find out if there is a connection between number of rooms and crime rate — so in general it reduces with increase of number of rooms, while for RM=6 there are the most amount of outliers. This looks strange and I have no explanation for this.
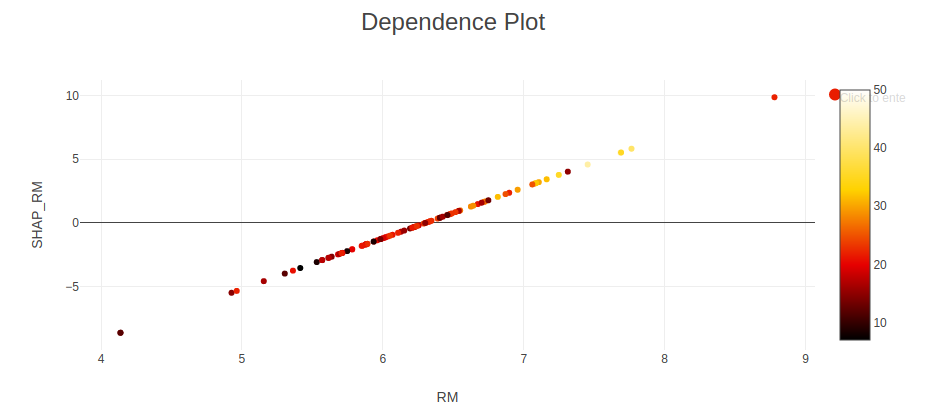
As for the SHAP values analysis, I tried out 3 models. And it seems that linear regression shows quite well that the connection between CRIM and RM is very weak.
The same thing for me this week. I have also used the example from the hub for my workflow to calculate the Shapley Values and SHAP using the loop nodes.
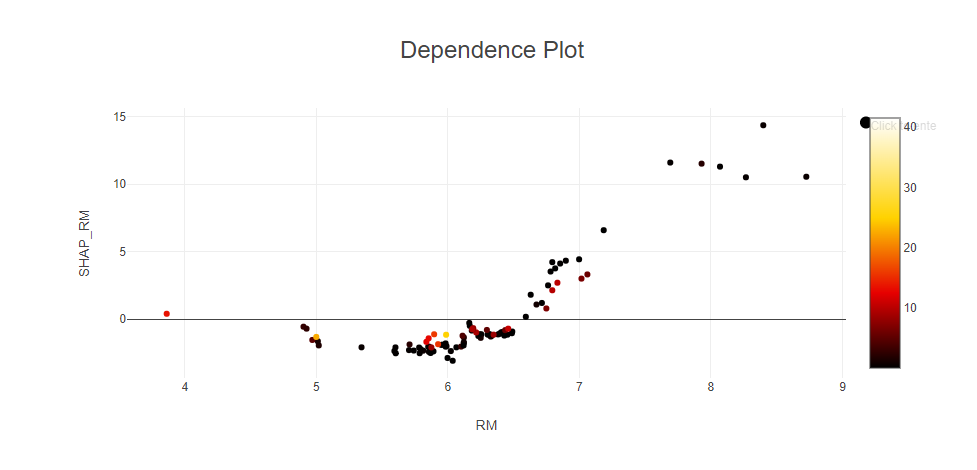
For the dependence plots, I followed the set-up from the example workflow and therefore plotted the RM column (x-axis) and Shapley_RM (y-axis) with CRIM as the colour. It appears that the majority of points on the Dependence Plot are black indicating a low crime rate in general. There are a few red points indicating higher crime rates and these appear to be around low to medium RM values, where as at high RM values, all points are black (low CRIM):
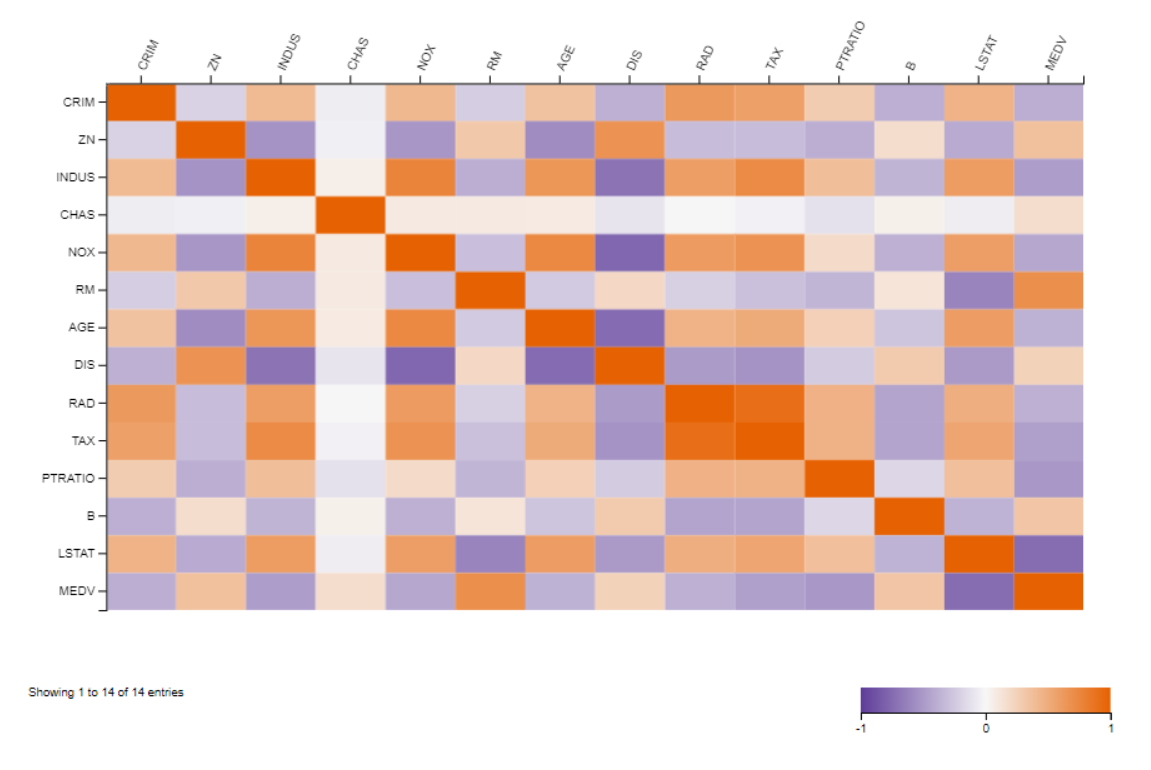
As an extra, I also performed Linear Correlation on the original data and created a Heatmap to show the correlation of all pairs of variables. Looking at RM and CRIM on this heatmap, the lilac colour represents a negative correlation:
Hey All -
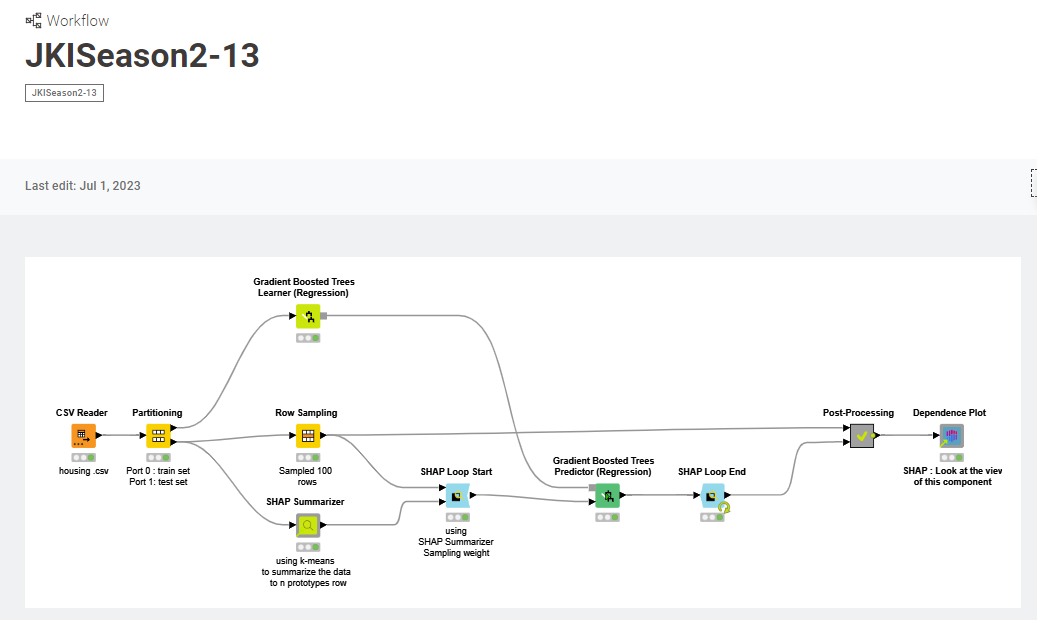
I didnt really enjoy this challenge, mostly because the topic was super tough for me and I didnt actualy build anything, but saw it through to learn something new. I easily followed the hint, borrowed the SHAP value WF from the Hub and modified it to crunch the data. No problem.
My issue was that i didnt understand what i was doing and could not interpret the output. The real hint came when i read the solution today… after completing Challenge 14! For the most part, i didnt know what the columns meant and so without any context, i just didnt know how to work through the problem. Worse yet, probably because of the version i am using the solution does not import properly for me:
But the solution mentions median value of the house in the final line, so i looked back at the columns and found “MEDV”. Eureka! Now i knew what i should predict and then i could look at RM and CRIM the way it is done in the hint. Here is the modified workflow:
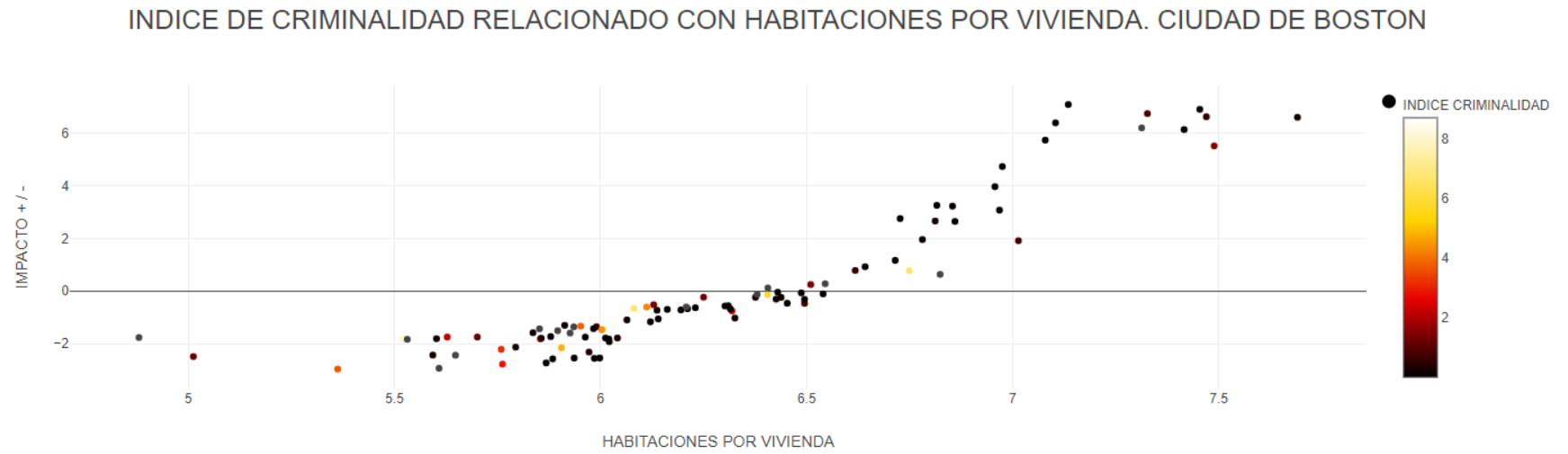
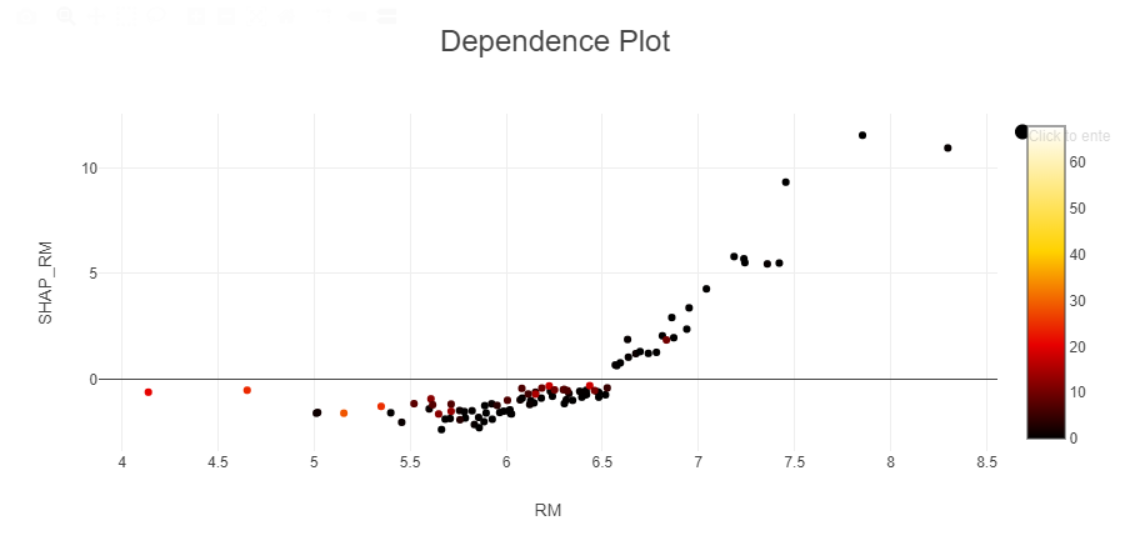
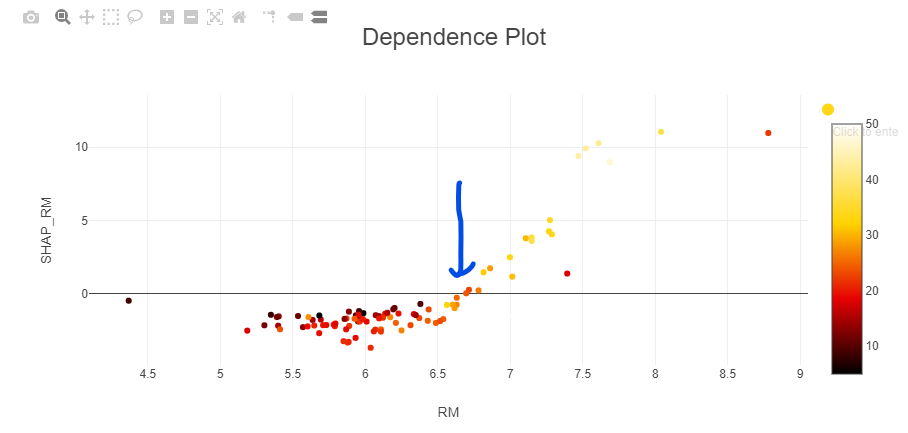
But now what - I had to do some reading to find out what these plots mean. (this is probably the page that got me over the hump: Explaining Machine Learning Models: A Non-Technical Guide to Interpreting SHAP Analyses). I had never heard of XAI or SHAP values. The way i interpret this plot now is that when RM is below 7, RM as a feature has a weak negative impact on the predicted median value of the house. Above 7, there is a strong positive correlation to median house value.
Thanks for this challenge - it was unpleasant and i am still confused, but it forced me out of my comfort zone, which is where i like to be.
L