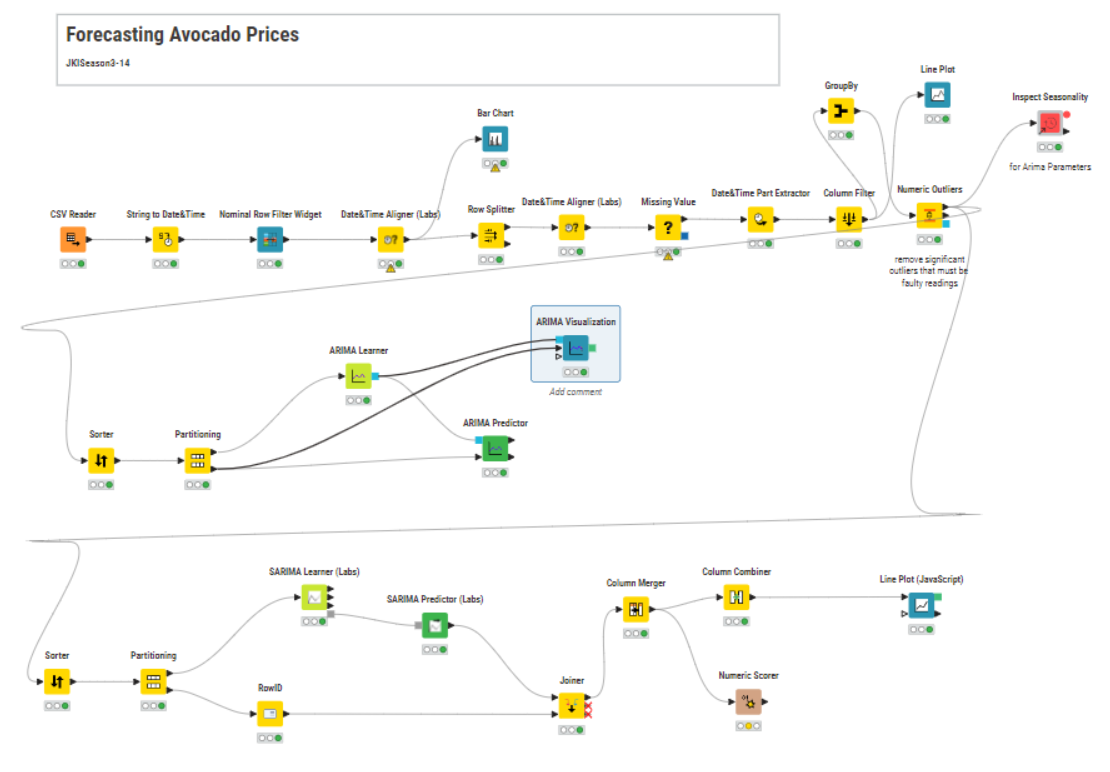
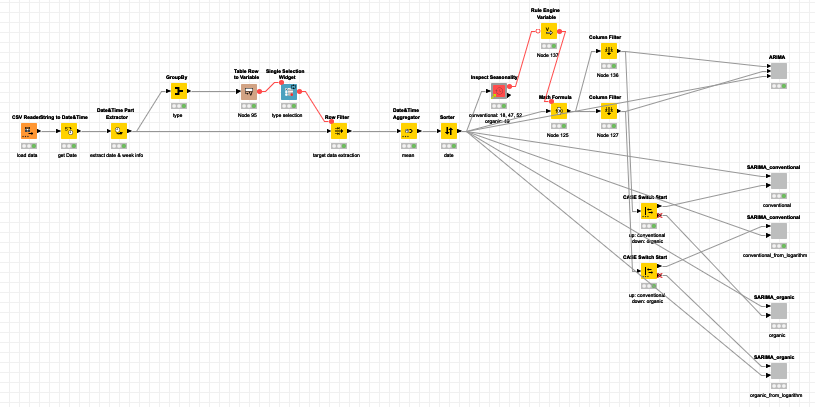
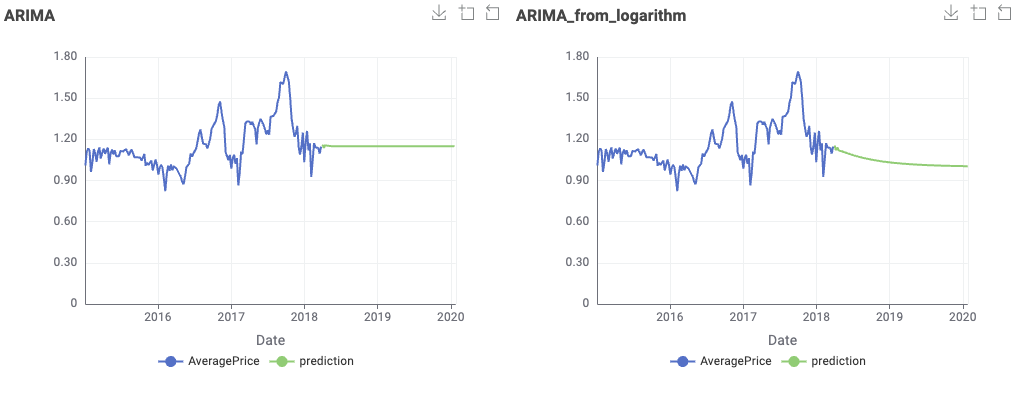
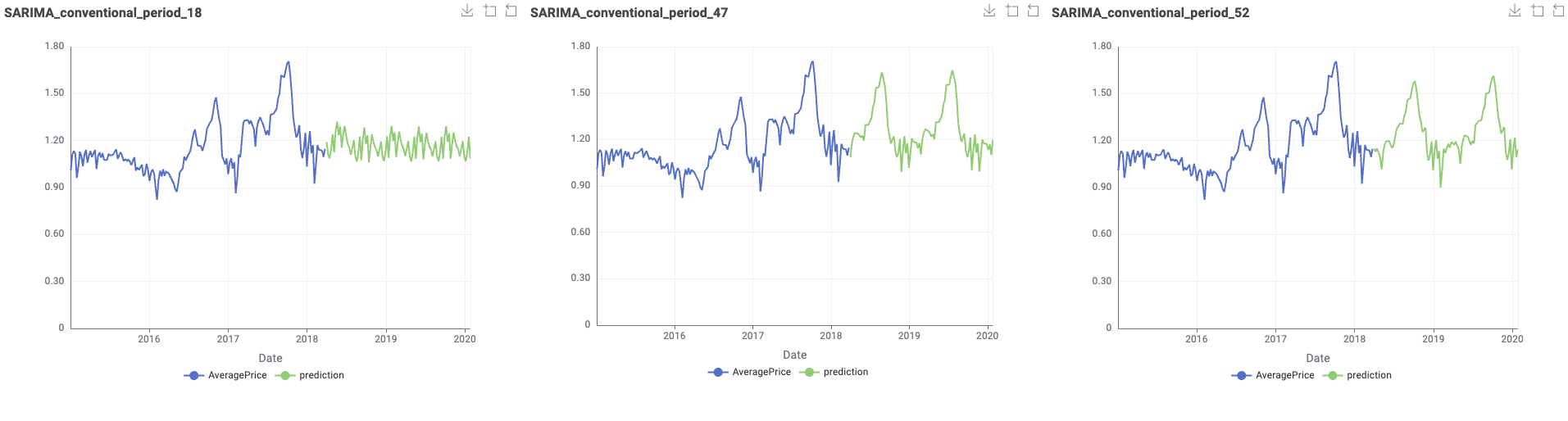
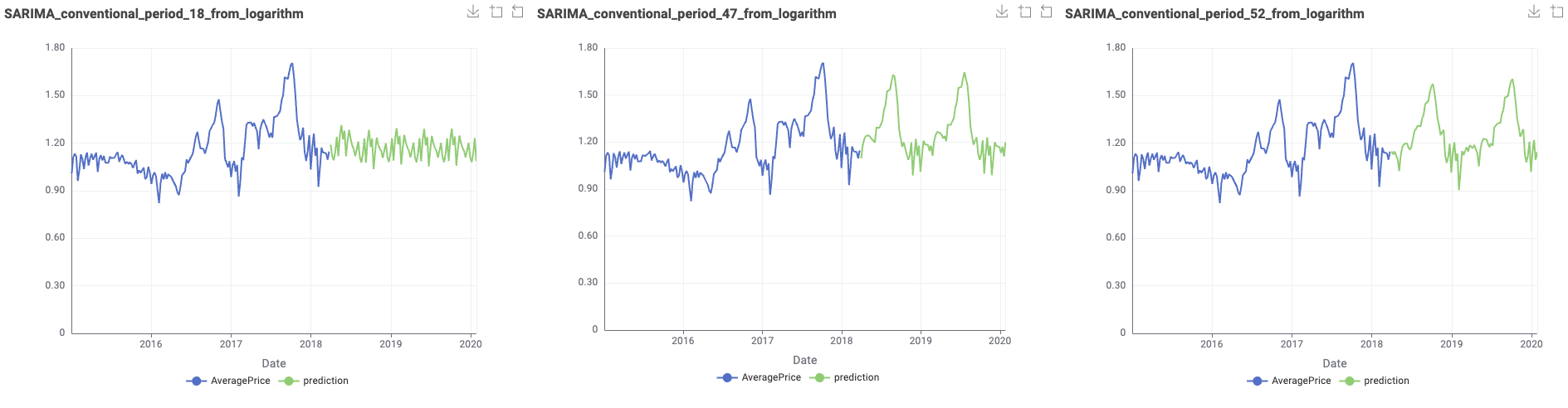
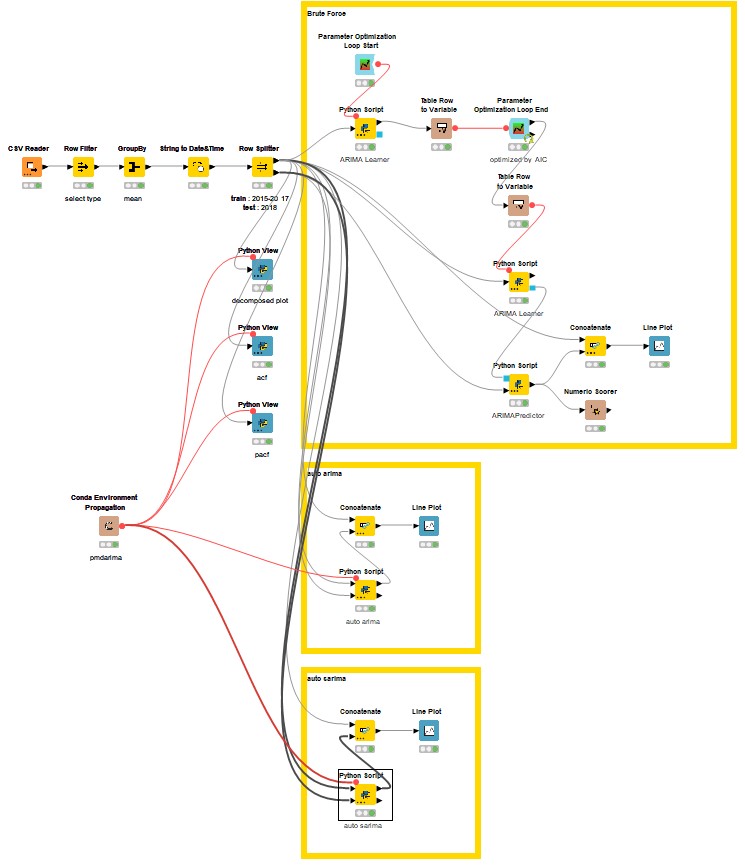
Hello everyone, this is my solution.This workflow should only run on versions above 5.3.*, because after 5.3, the SARIMA node has changed its extension.
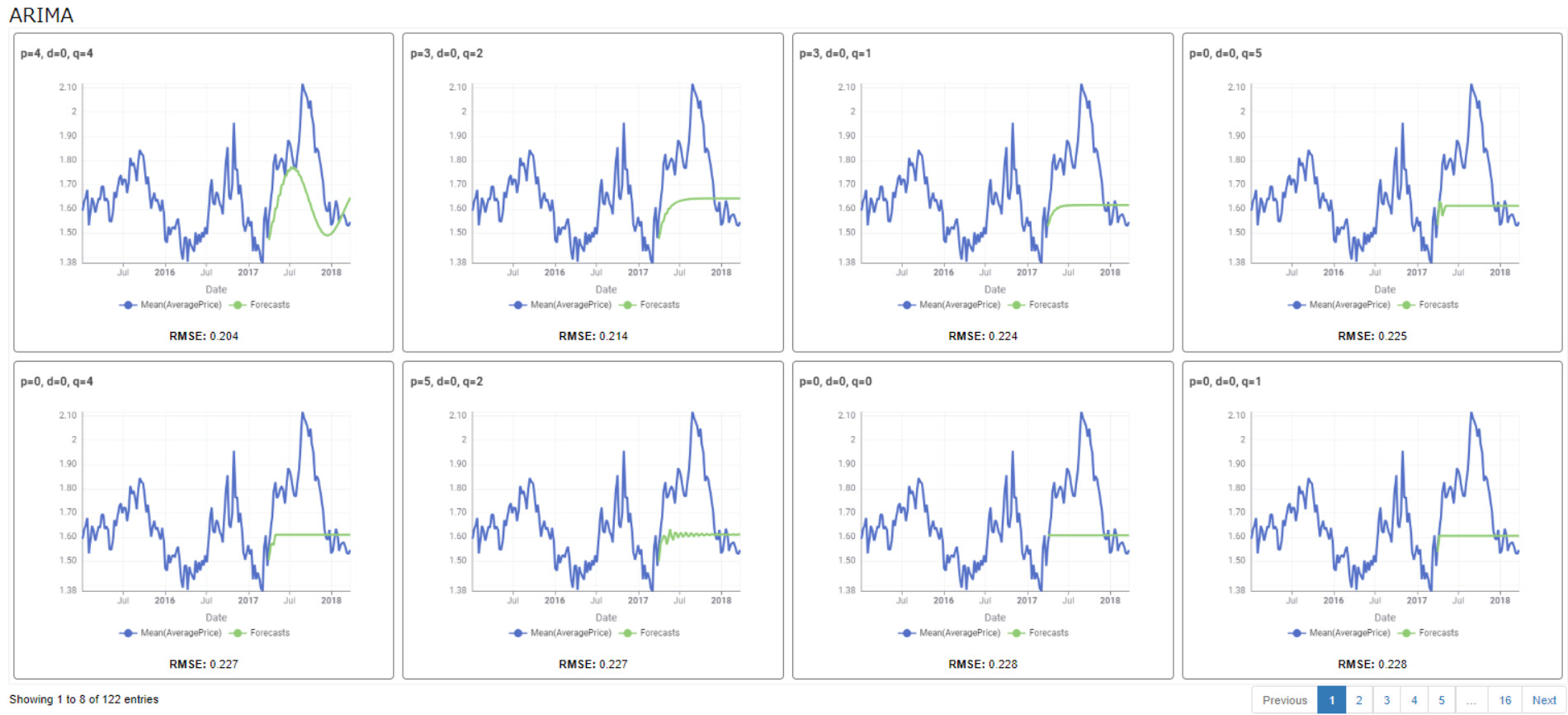
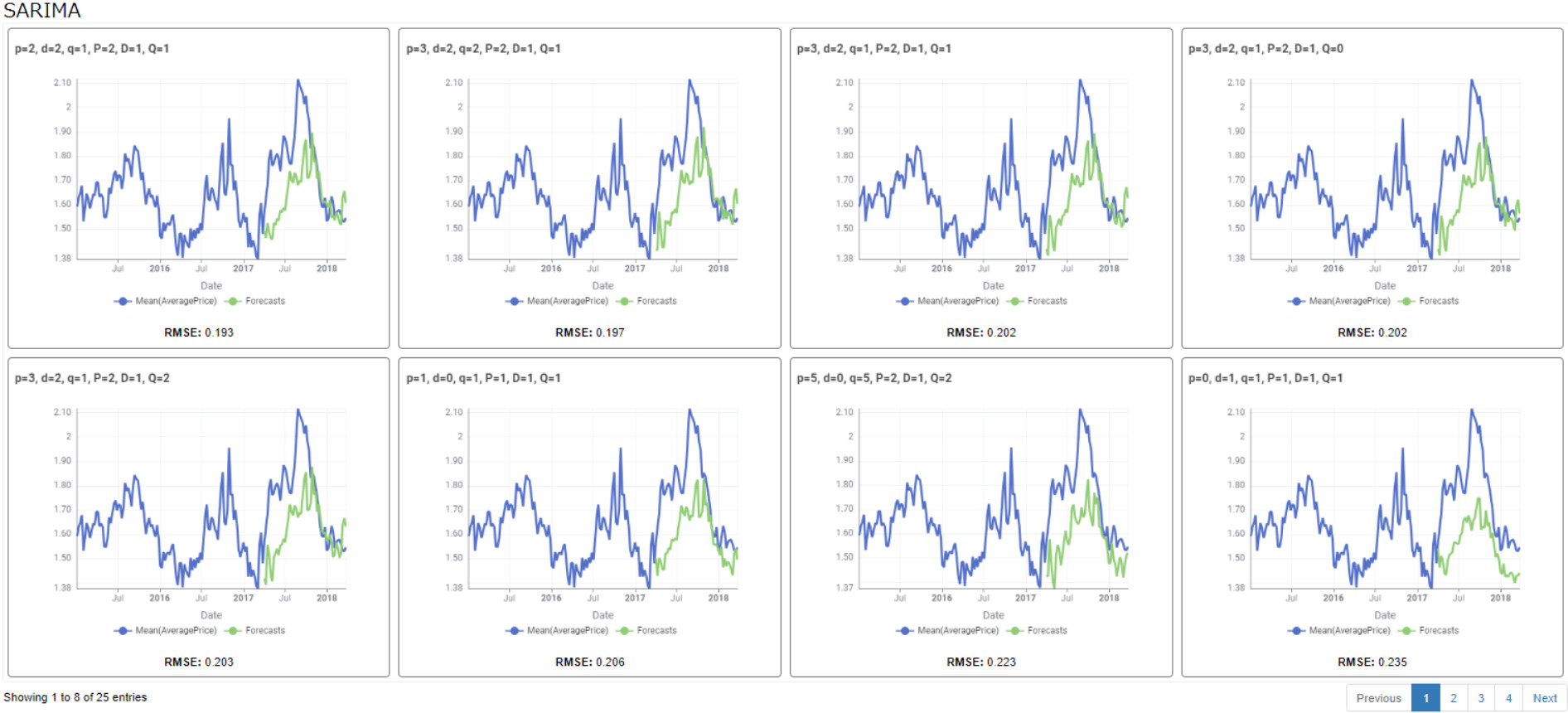
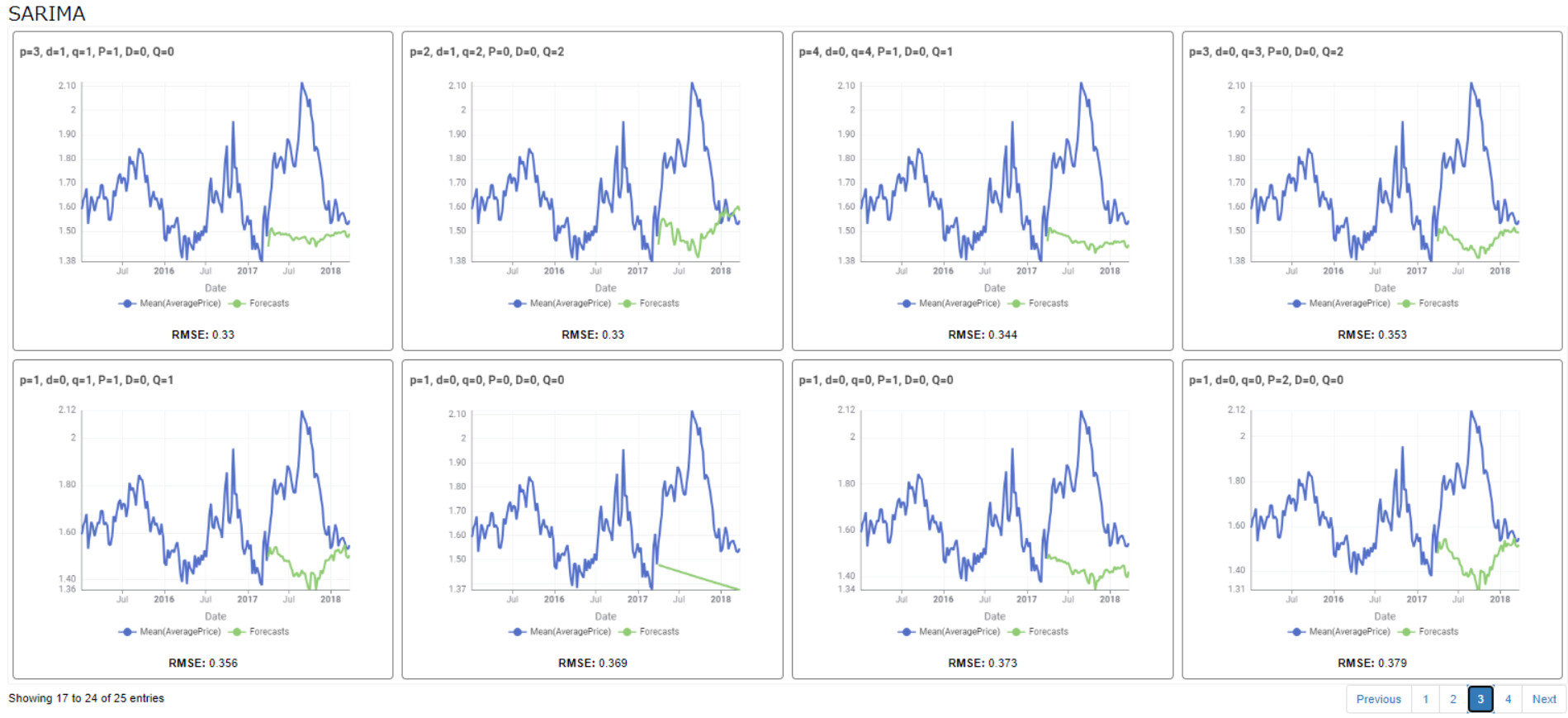
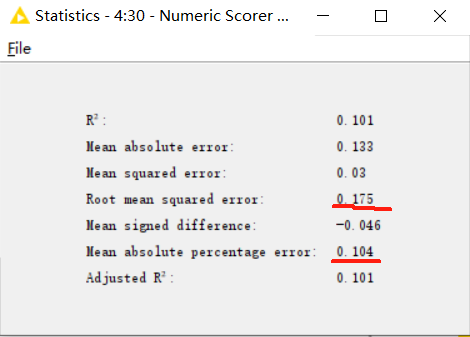
Regarding the confirmation of the hyperparameters of the SARIMA model, I also encountered the problem of overly long calculation time. Therefore, I adopted the method of manual judgment. Manual judgment has subjective factors, but judging from the model test results, the effect is good.
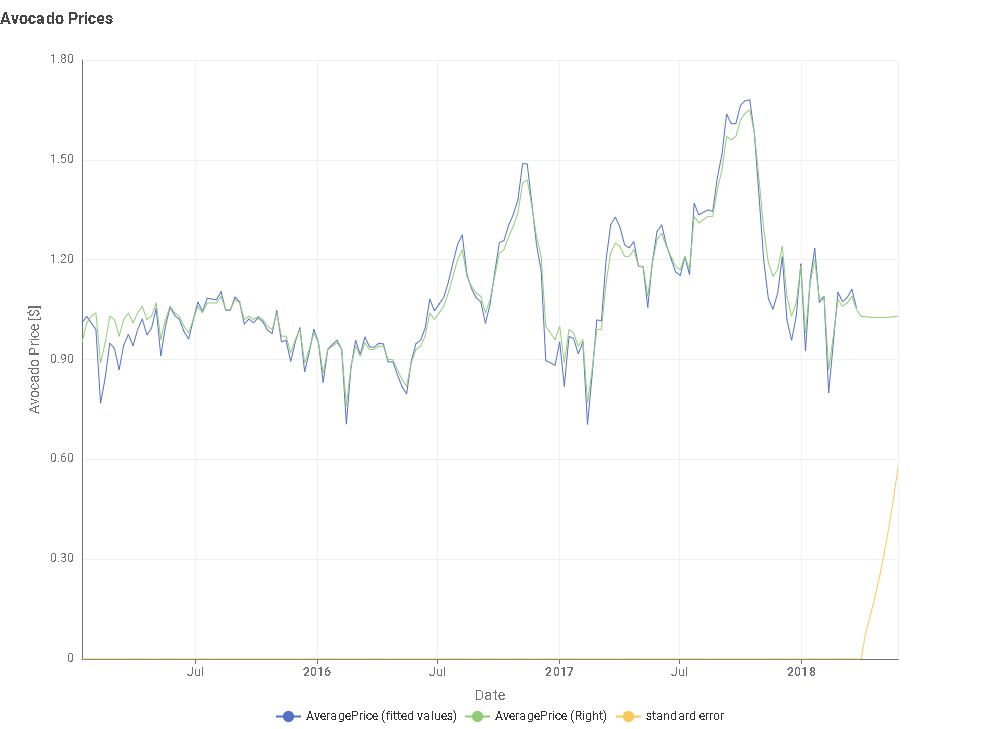
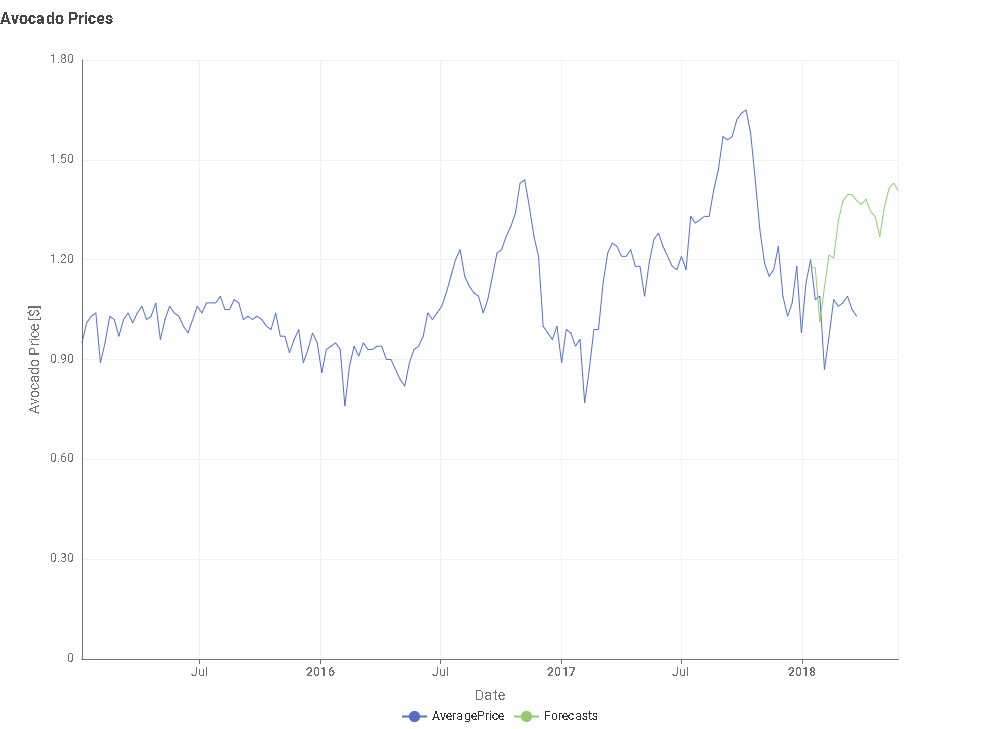
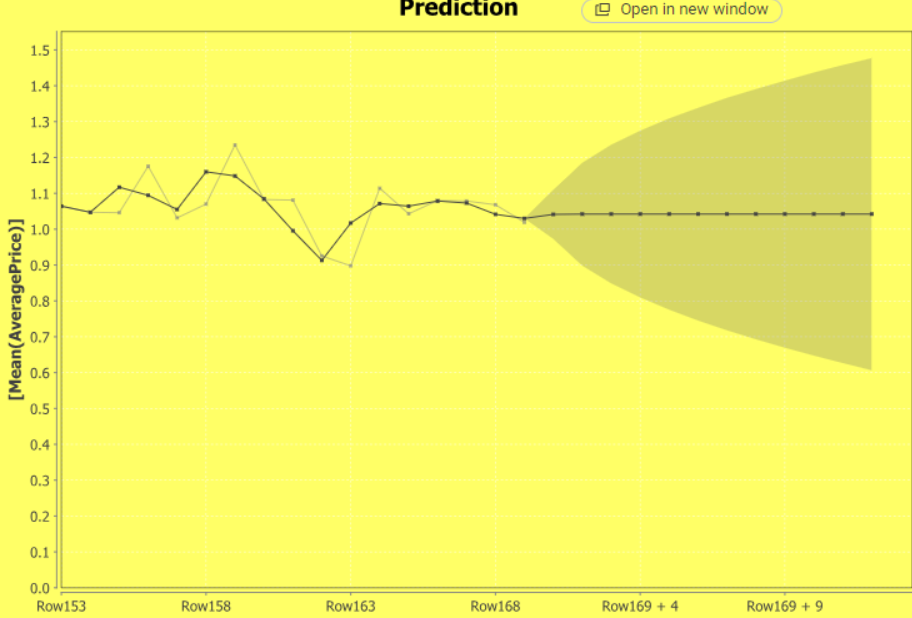
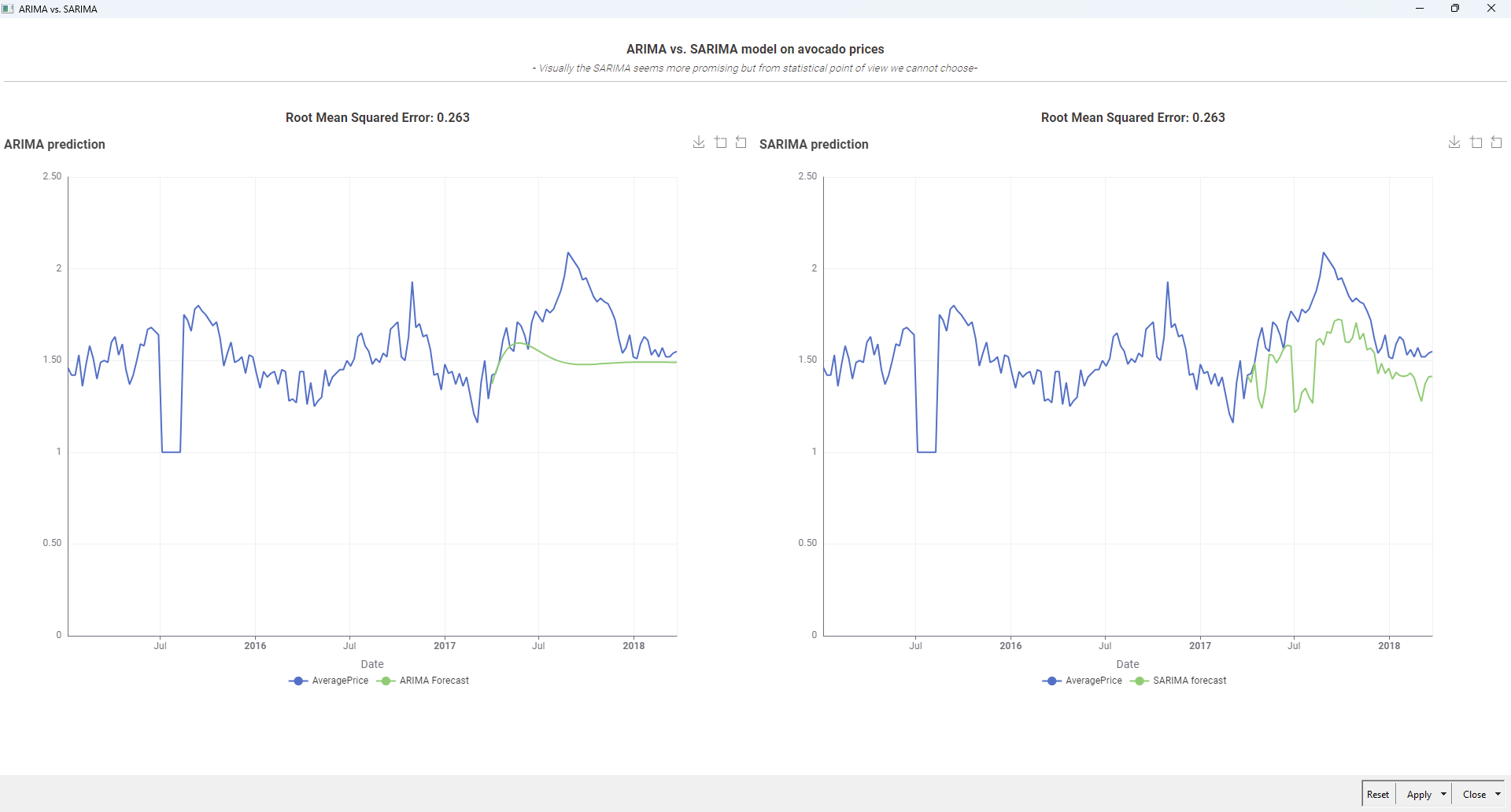
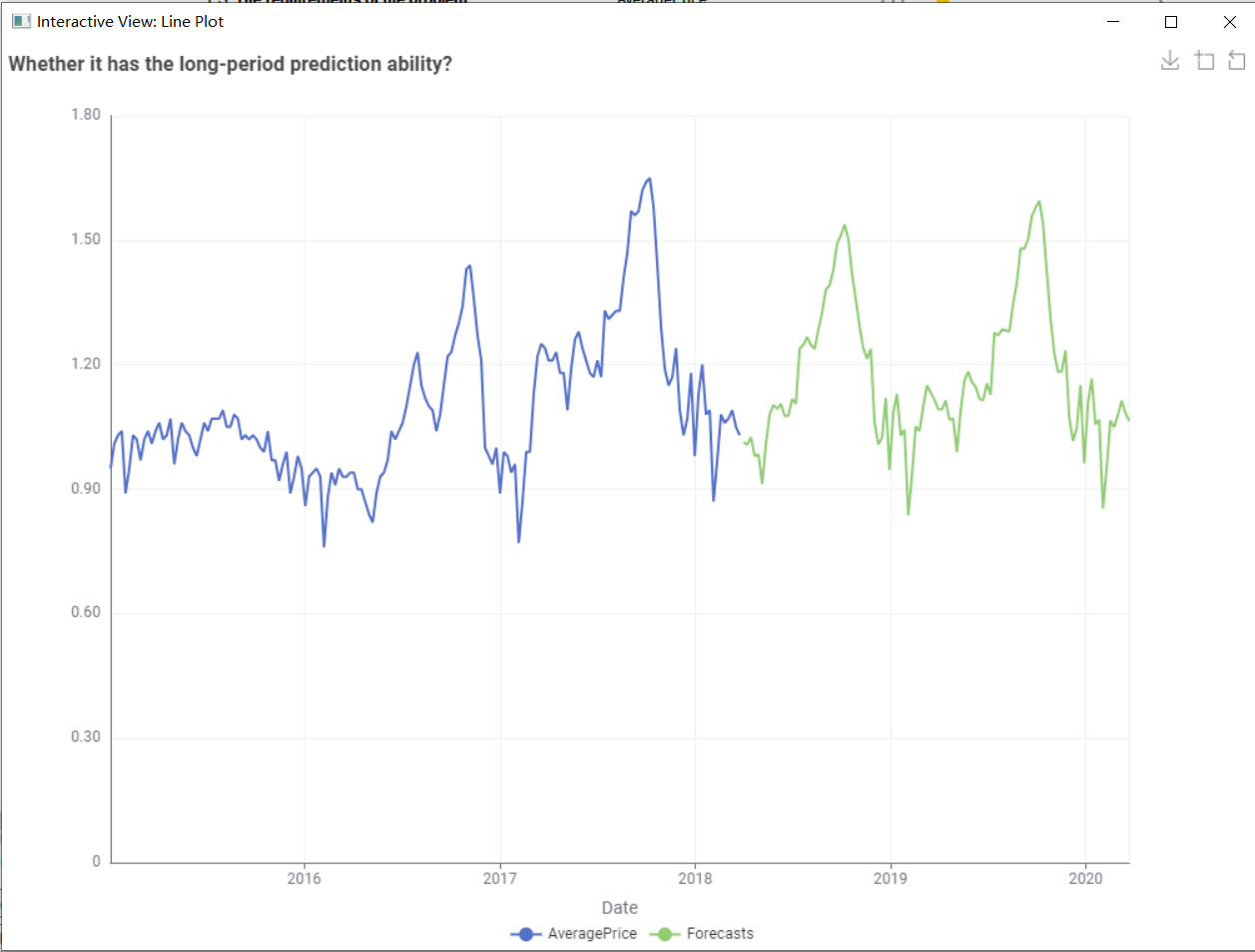
This is the test result where the length of the test sequence is 52.
PS: The test results are strongly correlated with data preprocessing and dataset division.
Explanation:
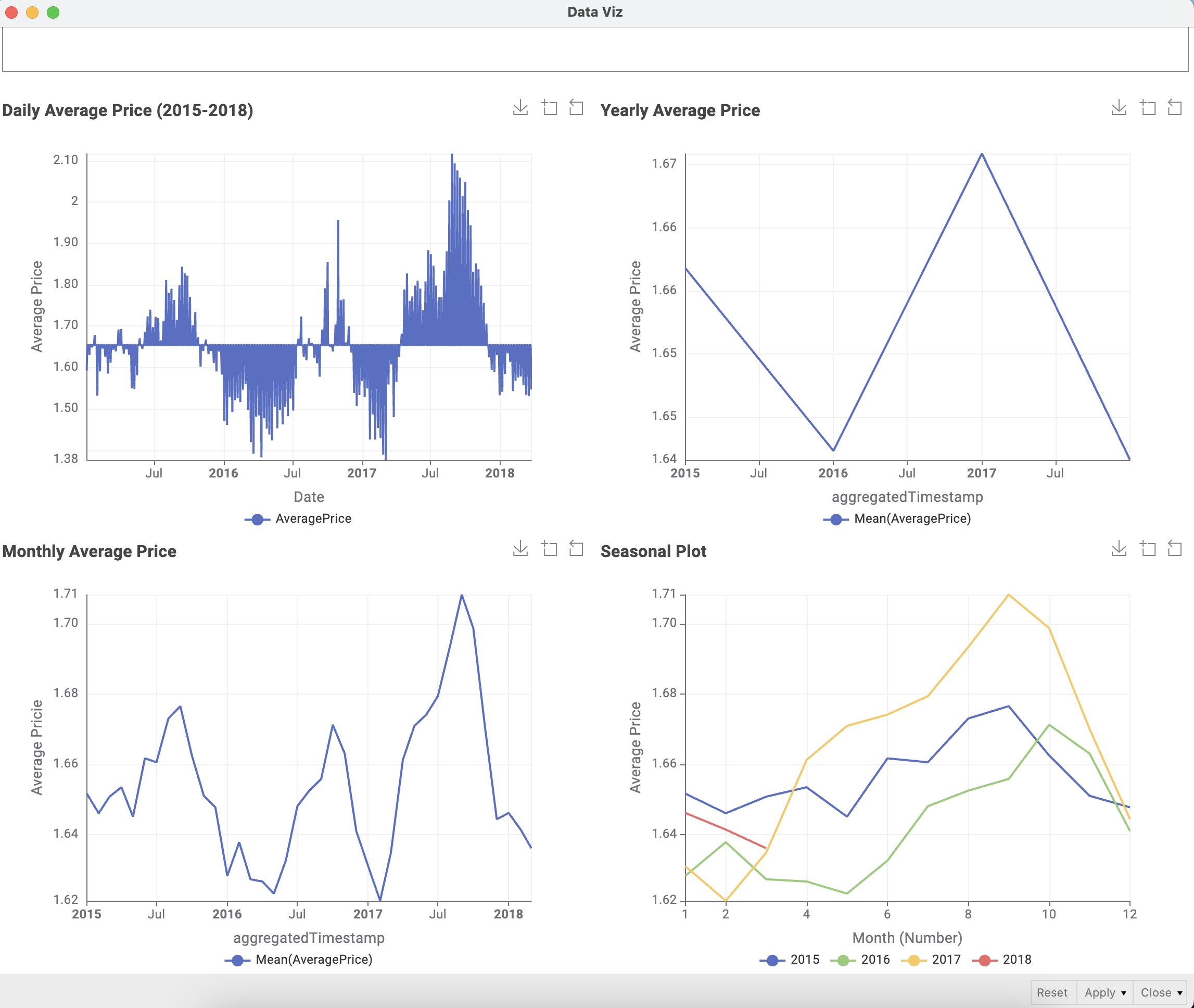
1.For data processing, only conventional types of avocados were considered because their sales volume was the largest, far exceeding that of organic types of avocados.
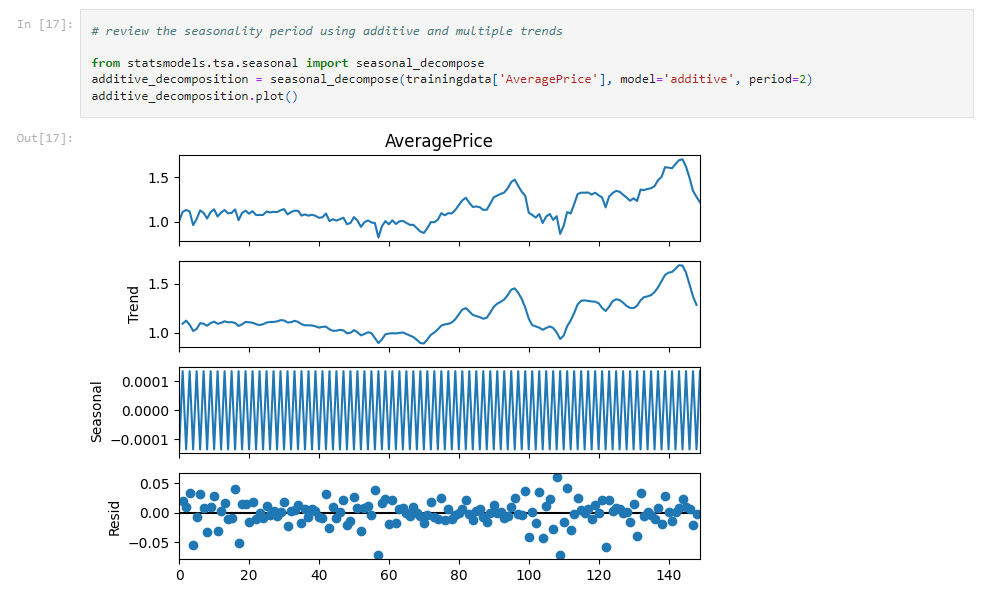
2.In the dataset division part, I referred to @sryu 's method. The retained sequence length of the test set is 52, which is exactly the length of one year. Because if the data is to check for seasonality, at least one complete cycle needs to be examined.
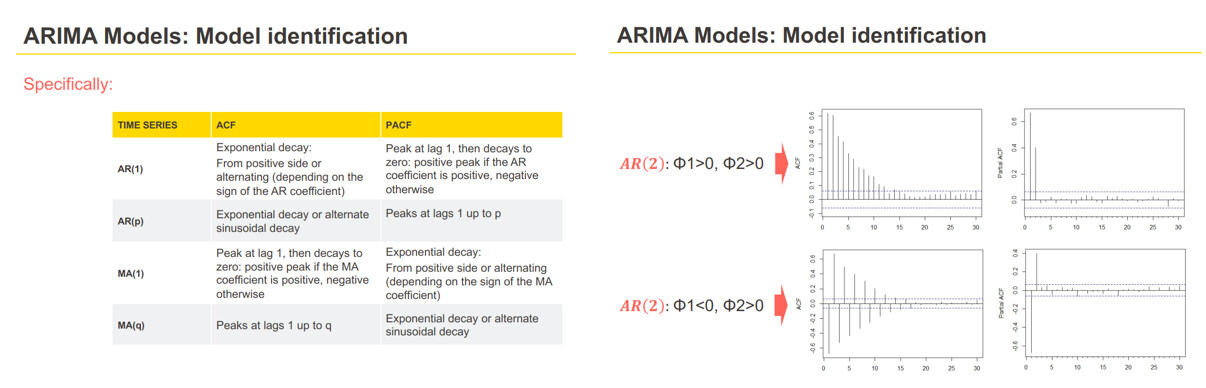
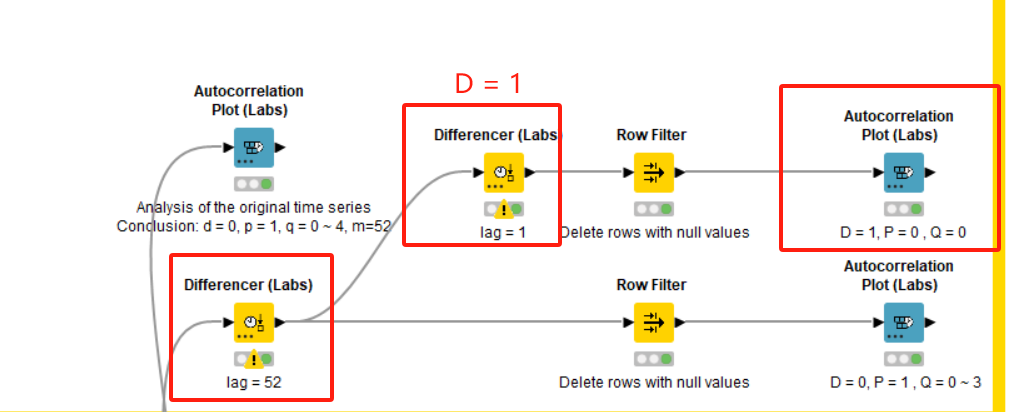
3.Manual hyperparameter judgment, as shown in the following figure:
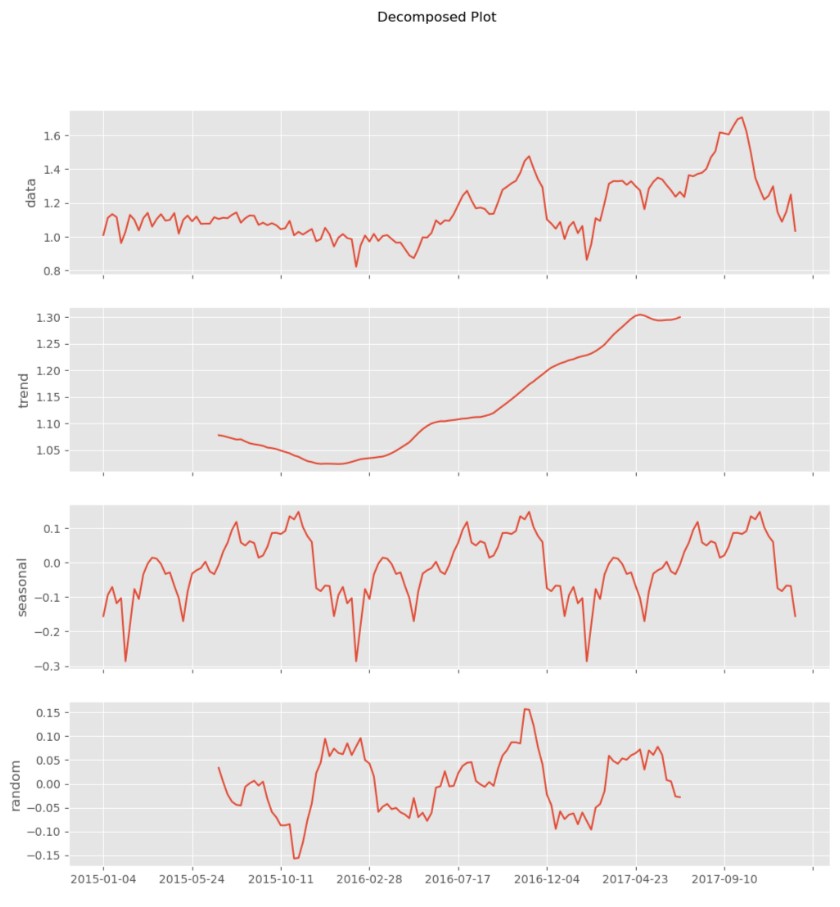
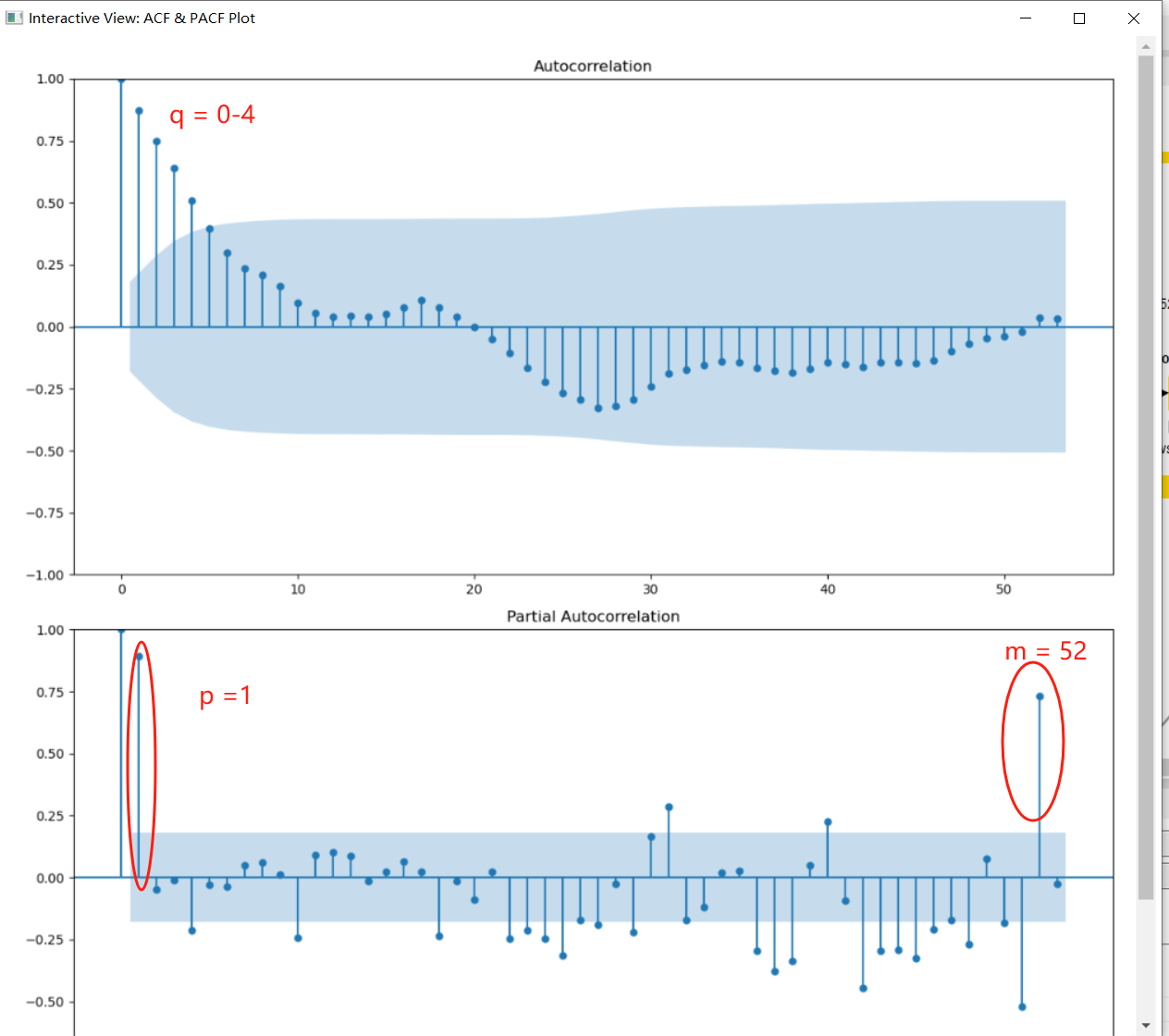
The ACF and PACF plots of the original data.
PS: The first-order difference graph of the original sequence eliminates the autocorrelation of the sequence. So there is no first-order difference here, that is, d = 0.
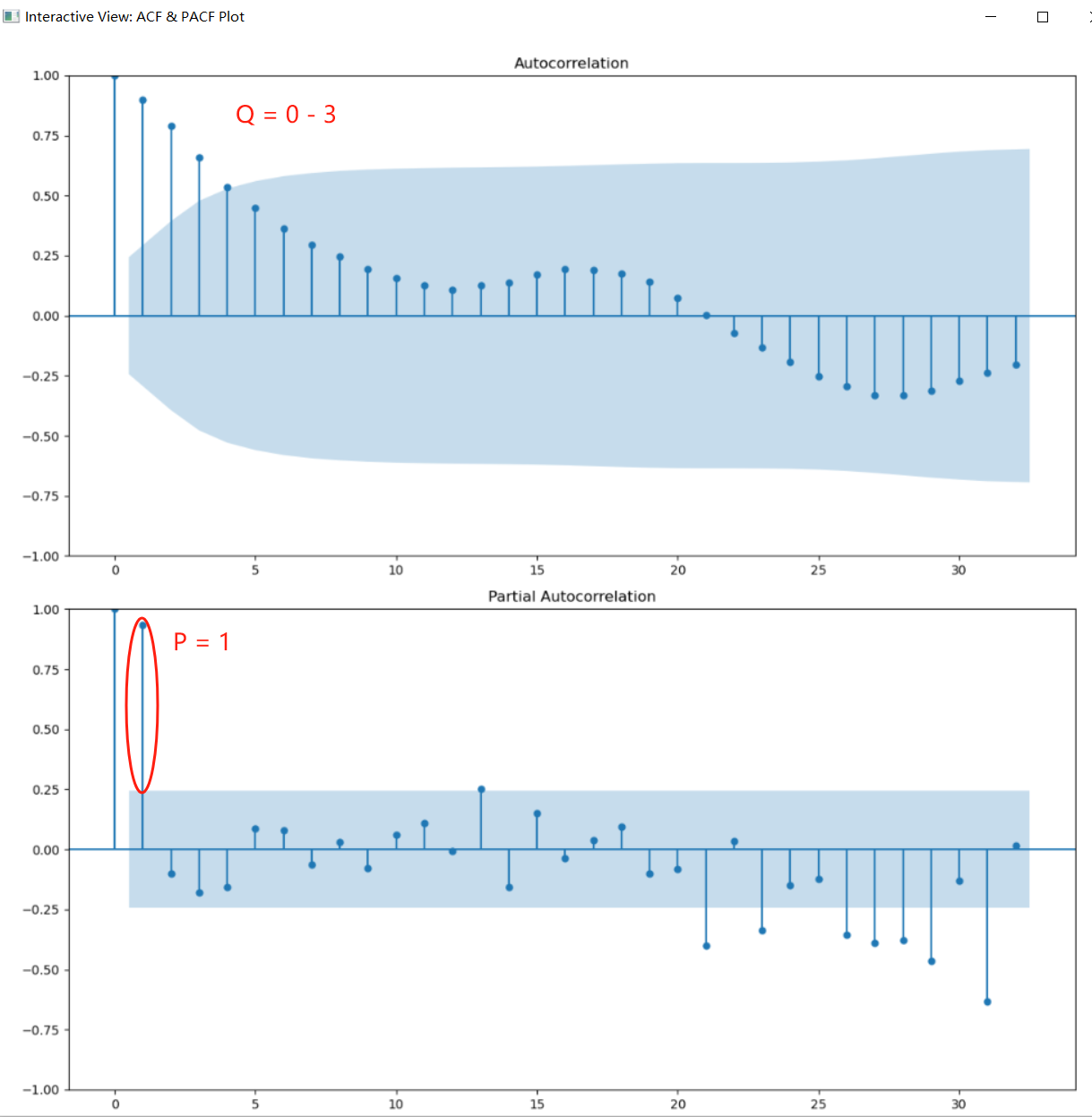
The ACF and PACF plots of seasonally differenced (lag 52).
PS: Here, D = 0 is default. However, if D = 0 in the final result, the trend between years will be lost. So here D = 1 is set.
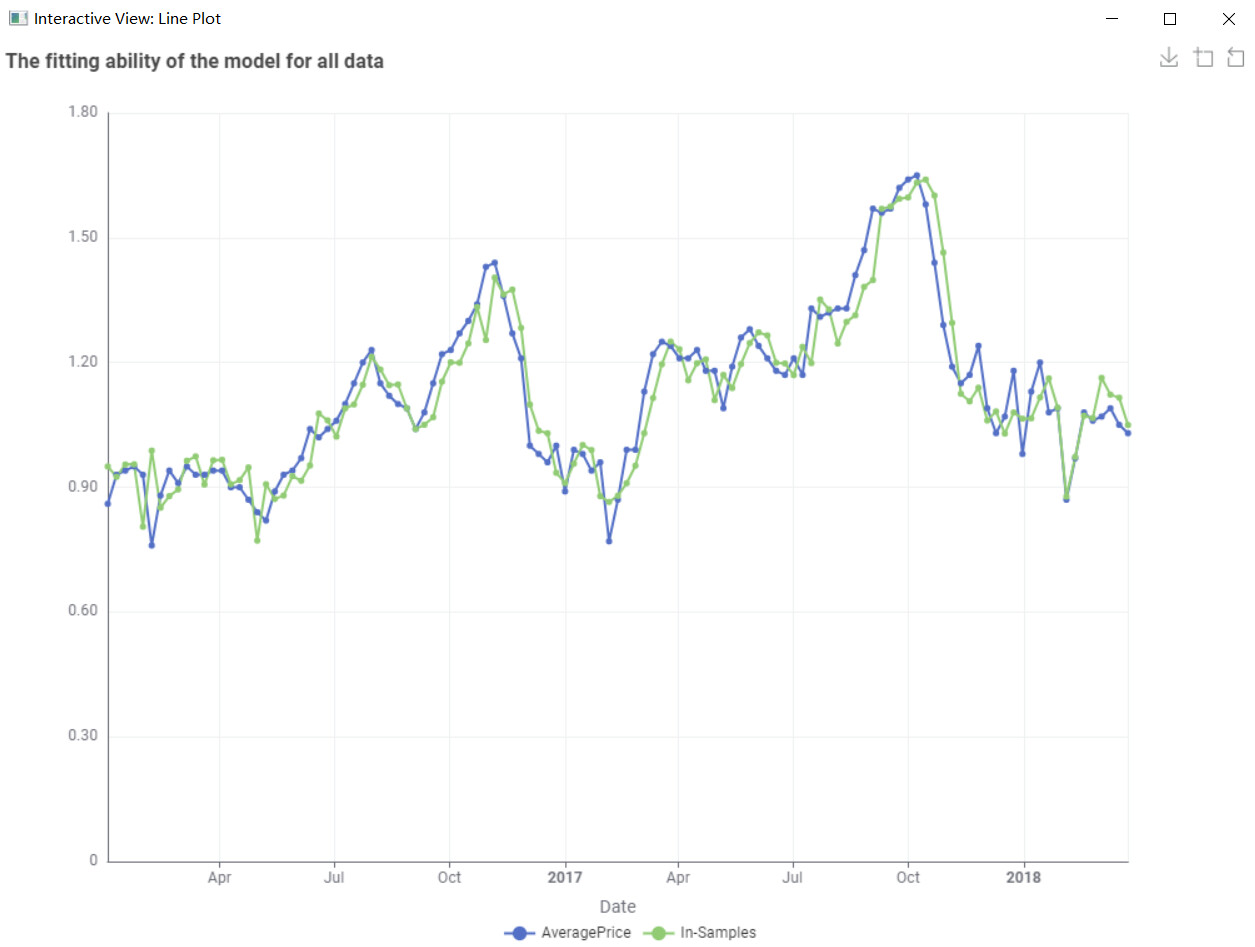
Result:
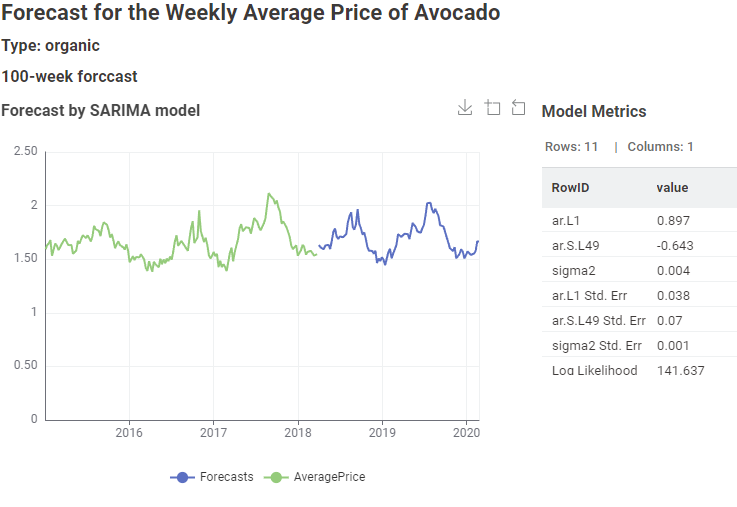
(p, d, q)(P, D, Q)m : (1, 0, 0)(1,1,1)52