My solution uses a MovingAggregation node to do a cumulative computation from top to bottom and from bottom to top. So all values of 0 from both cumulative computations can be excluded from the file.
See: Challenge 14
My first thought was the Moving Aggregation similar to @HansS solution. Then, I ideate an alternative option based on the usability of ‘Missing Value’ nodes. Both are similar.
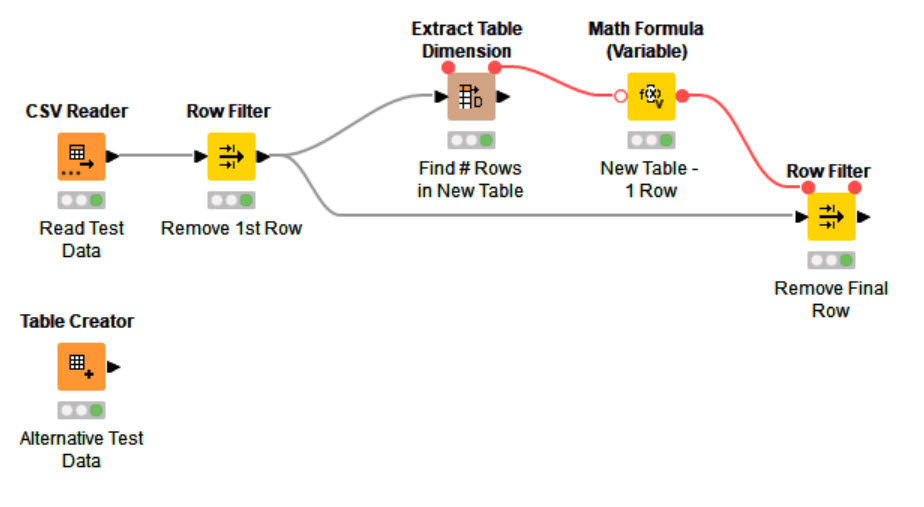
I struggled a little bit with lagging and stuff, so I decided to solve it using R.
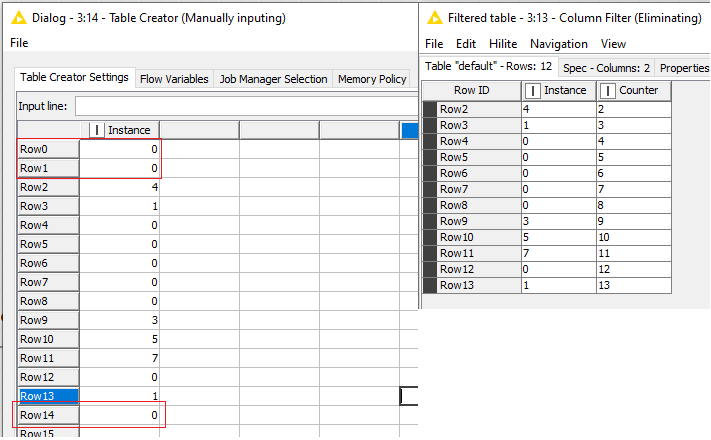
I used a table creator node to modify the input table a little bit, just to be sure that even if you have a long list of zeros in the middle of the input, the model is not recognising it as noise.
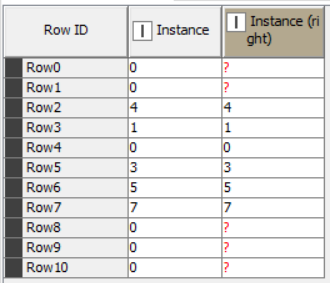
My solution centers around calculating running sum in both directions and removing rows with zero (0). The default rowid’s cannot be numerically sorted (obviously), so I had to add a counter generation node to sort on.
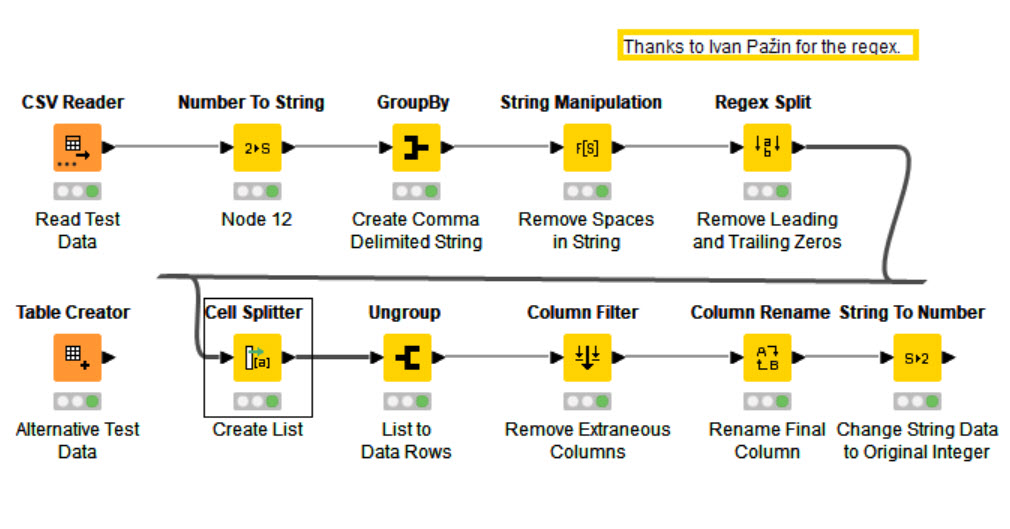
We could invent a bicycle, but there is already a function to strip the string. So my solution is as simple as group > strip > collection/list > ungroup.
My first solution was to use a lag column and moving aggregation (for cumulative sum) to identify groups. Then I used a groupby node to find the max group number, which I filtered out if it was full of zeros. I decided that was all overkill since I was only interested in the last group, so used a switched to using a Moving Aggregation (again for cumulative sum) to identify leading zeros and flipped the data to do it on either end. Looks like my solution is almost identical to HansS’.
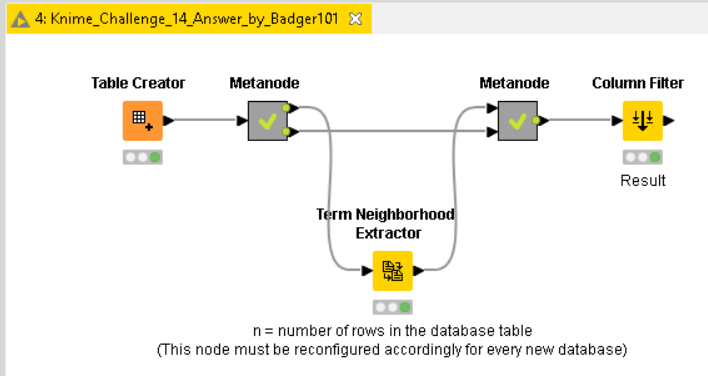
Here’s my go at this. Not attempting to provide an efficient way, but merely an alternative solution; a unique approach to solve an integer-based issue using KNIME Text Processing partly.
Lots of different implementations that I’d never be able to come up myself. Good job!
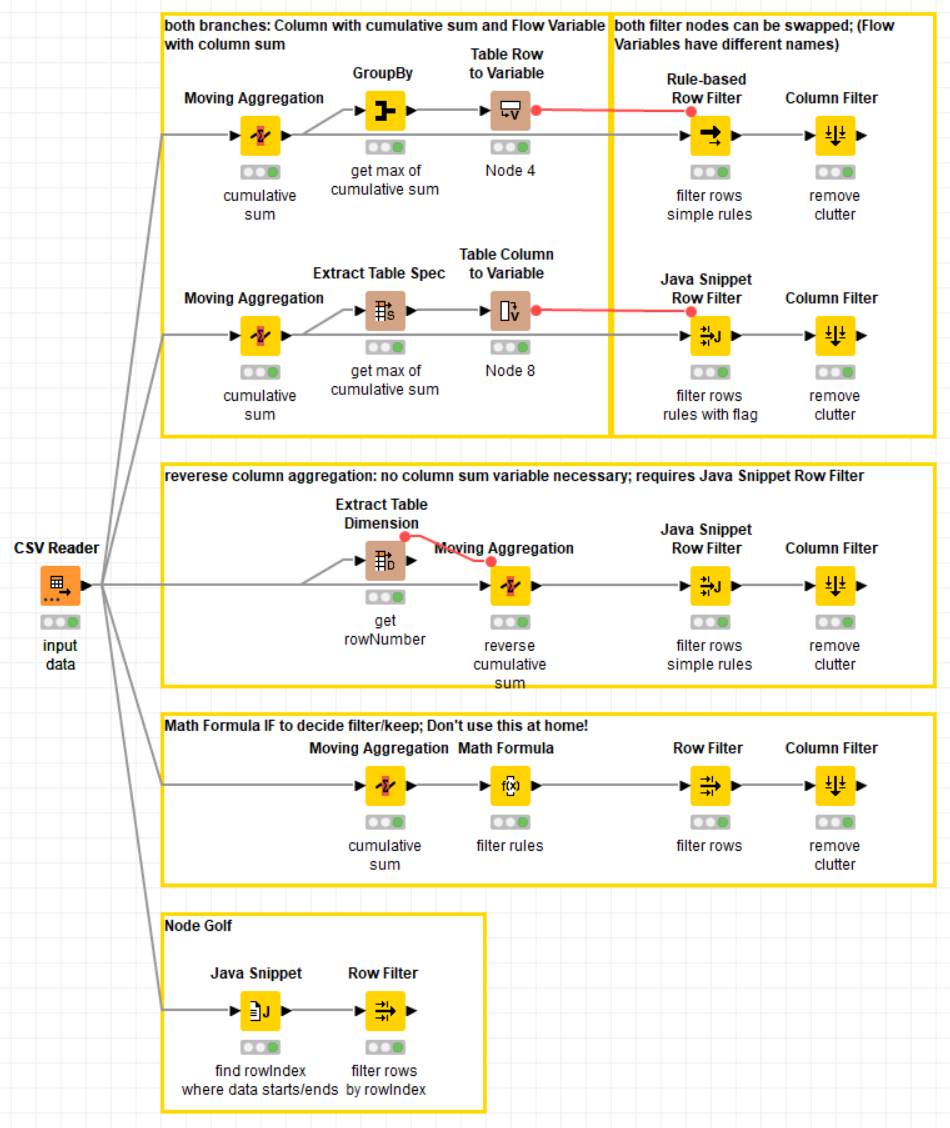
I did several variations. They all use the Moving Aggregation node for some reason:
The 2 topmost branches do the same thing with different nodes:
Step1: append a cumulative sum column and push its maximum value to a Flow Variable
Step2: use a row filtering node to filter the data set
Those sections can be mixed and matched from both branches.
We can also bypass the need for the column sum by doing a reverse column aggregation instead. The Moving Aggregation node requires the row number in this configuration.
More a proof-of-capability than anything useful, the Math Formulas IF-function can decide which rows to keep/filter. Needs a Row Filter to execute that decision.
Finally, the Node Golf version:
Step1: Java Snippet to find first and last row holding data; push it to Flow Variables
Step2: Row Filter to filter by rowIndex (Flow Variable controlled)
This is probably also the fastest to execute.
Looking at all these imaginative solutions gave me some insights, then my challenge workflow has been upgraded from two to four different optional approaches. There’re tons of fun in this challenge, we could keep ideating approaches forever.
Missing Value downwards (previous value) and upwards (next value) infill.
Conditional Loop End, computing stripped starting and trailing noise lengths.
String concatenate and Regex code to strip starting and ending zero values.
Last one inspired from @MEPivnenko 's concatenate (I didn’t check into the code avoiding spoiler); then deepening into ‘non-greedy’ Regex code with some help from forum and @ipazin solution.
In this workflow, the data rows are first labeled as 0 and non 0. Then add them in a list, use the Column Expression node to find the first and last index of the non-0s. The first and last index are then transferred as flow variables “start” and “end”.
Then loop through the table row by row, and check if the current iteration number is within the range defined by the index “start” and “end” variables, and add the column “include”. The rows are then filtered out if they have a “false” value in the "include"column. Then remove the “include” column.