Hello @HaveF, of course I have it! You can check my blog posts on Medium. Here is the first post from the series, I would be glad you find it helpful. You can also find there the link to other resources regarding conformal prediction.
5 Likes
This is super cool! I wonder if this acc is statistically different from the 79%/80% I saw popping here too. ![]()
This would be a cool challenge, by the way! How to assess statistical differences in metrics. ![]()
![]() As always on Tuesdays, here’s our solution to last week’s Just KNIME It! challenge
As always on Tuesdays, here’s our solution to last week’s Just KNIME It! challenge ![]()
![]() We used a very minimal workflow and contrasted it with a baseline solution. It is pretty easy to beat this deadline, but results can definitely get more interesting!
We used a very minimal workflow and contrasted it with a baseline solution. It is pretty easy to beat this deadline, but results can definitely get more interesting! ![]() Kudos to everyone who experimented with other analytics techniques, including preprocessing the given dataset!
Kudos to everyone who experimented with other analytics techniques, including preprocessing the given dataset!
![]() And thanks for the report on the issue with the AutoML component on KNIME 5.1! It’s been reported.
And thanks for the report on the issue with the AutoML component on KNIME 5.1! It’s been reported.
Hi all, the AutoML components is failing for issues with the new release of KNIME AP 5.1.0
It will work again with the release of the bug fix KNIME AP 5.1.1 (likely later this month).
If you want to run the AutoML component for this Just KNIME It challenge you can download KNIME AP 4.7 at Previous Versions | KNIME
We apologize for the inconvenience.
4 Likes
Personal opinion:
On a large dataset, with enough samples, the impact of seed is relatively small. On small datasets, the impact of seed is relatively greater. If we don’t set the seed parameter, we want to get a more general result.
But in reality, in order to reproduce the results, seed is usually set to fix its value.
At this point:
1.arbitrarily set one seed
2.similar to a hyperparameter search, to find the optimal seed, and then set it.
There is no difference in approach, as a fixed constant is set. Why not set a better one
I have not analyzed the statistical differences. Speculation may have an important relationship with optimal dataset partitioning, as well as model optimization.
2 Likes
if a radical seed is used, there may be risk exposure, but I did not further analyze it.
1 Like
Hi, @paolotamag ![]()
![]()
![]()
Thank you for informing us about the autml component. I have a related question regarding the compatibility of the component.
If the nodes in the component are upgraded to version 5.1, what will happen if I open my workflow in version 4.7? Will it automatically update to the new 5.1 nodes, or will it consider my KNIME version first before deciding whether to update the component?
1 Like
In this case KNIME won’t perform any automated update of the component to make it work with 4.7.
KNIME in general is not made to work with workflows created in more recent version.
That is:
-
if you open an old version workflow with a newer version of KNIME, that old workflow should always work (backwards compatibility)
-
opening a new version workflow with an old version of KNIME might trigger issues (and there is no automation through shared component to fix that)
The shared component link only works to update a component to more recent version if that becomes available where it is shared (in this case at AutoML – KNIME Community Hub). This automated update happens regardless of which KNIME versions the component is opened with.
As you can see from the AutoML page, the component was last edited in 2022…
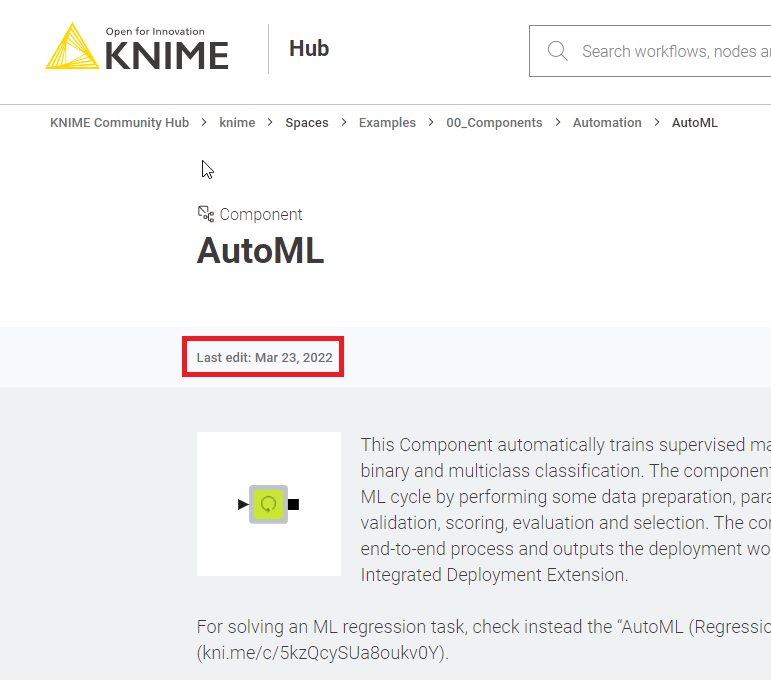
You can check here that it was then KNIME AP v4.5
https://www.knime.com/download-previous-versions
This means that the component should work with any KNIME Analytics Platform after 4.5. The fact that it does not work in 5.1 is a bug and it will be soon fixed in 5.1.1. Unless you have drag and dropped the component before such date (March 23, 2022) no automated update will take place.
Long story short, when you open the workflow with the component in KNIME AP 4.7 you will need to close any warnings and go through the worklow again to see if any node/component is missing or malfunctioning. If it is you can delete such nodes/components and drag and drop it again from the KNIME Community Hub or the node repository, connect and reconfigure it.
I would recommend to do so with the AutoML component too:
- Open the 5.1 workflow in KNIME AP 4.7
- Delete the corrupted instance of the AutoML component
- Drag and drop it again into the workflow from AutoML – KNIME Community Hub
- Reconnect it and reconfigure it
- Execute it and it should work again (I tested this and it worked for me)
1 Like
I believe I understand it. Thanks for your detailed explanation! @paolotamag
Hi Everyone ![]()
I’m a bit late to post my solution for this one, but I have spent a few days implementing several models ![]()
Firstly, I would like to share the link to a paper that was written based on this data:
It’s a nice read and talks through training and applying both a Logistic Regression Model and a Decision Tree (DT).
Hence in my solution this week, I decided to use a DT to determine the variable importance when predicting Diabetes. Just to be clear and to not cause confusion with KNIME variables, I’m using the word variable(s) in the statistical sense to describe the columns in the table.
I have also tested 3 other models (Random Forest, XGBoost and Logistic Regression) to compare the predictive capabilities of the models firstly with only the most important variables and secondly with all variables.
The original data made of 768 samples and 9 columns, uses 0 to represent missing values, so I used the -Math Formula (Multi Column)- node to convert these to missing values in the workflow. In order to handle these missing values, I decided to remove two columns with large amounts of them: Insulin (374/768) and SkinThickness (227/768). After removal of these columns, I then removed any remaining rows that still contained missing values, a total of only 44 rows. The reason for removing the columns first, was to significantly reduce the number of rows containing missing values and to preserve as many rows from the dataset as possible.
Before training any models, I have partitioned the data into internal and external sets. I have used K-Fold Cross validation on the internal set in order to run the DT model 5 times and gain Mean, Median and Standard Deviation values, using the -X-Partitioning- and -Loop End- nodes. Inside this loop, I have determined the Feature Importance by comparing the occurrence of each variable in the rule set of the decision tree against its shuffled counterpart. If the shuffled version appears more times in the DT rules than the non-shuffled version, then the variable difference becomes negative and it can be concluded that the variable is not important. The mean, median and standard deviation of variable occurrence and variable difference values can be viewed in the table below:
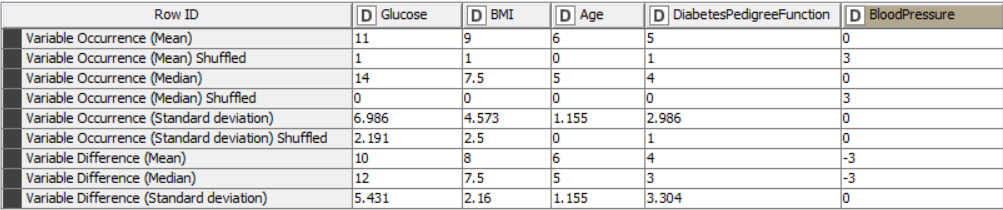
It is clear to see that the variable “Pregnancies” is not present in this table and this is due to the fact that it did not appear in any of the decision tree rule sets, neither in its original nor shuffled form. Therefore, it is possible to assume that this variable is not important in the prediction of diabetes based on this dataset. The variable “BloodPressure” appeared in rule sets as its shuffled form, but never in its original non-shuffled form, resulting in a negative variable difference. Again, this allows us to assume that this variable is not important in the model.
This leaves 4 variables, listed here in order of importance based on the variable occurrence; Glucose, BMI, Age and DiabetesPedigreeFunction. The most important being Glucose with the highest variable occurrence and variable difference. These important features also align with those determined by the DT model in the above scientific paper. However, it is important to say at this point, that further statistical analysis would be required to confirm these assumptions and any others made in the following paragraphs.
Following on from this, I implemented Random Forest, XGBoost and Logistic Regression models, firstly using only the 4 important variables and secondly using all the variables. I trained the models on the internal set using 5-fold cross validation and applied the models to the external set to predict the diabetes outcome.
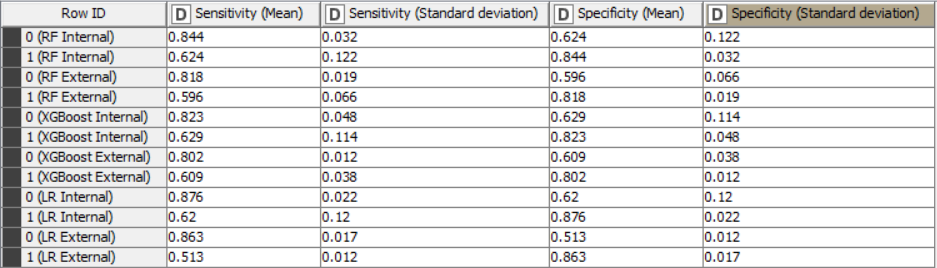
The Accuracy, Cohen’s Kappa, Specificity and Sensitivity results for internal and external sets are as follows for the models trained with only important variables:

Here are the statistics for the models trained with all variables:

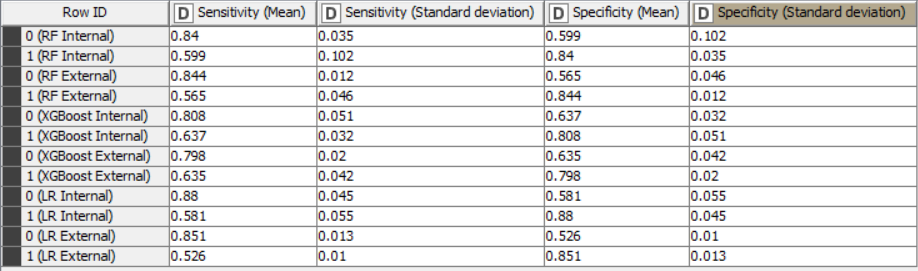
In fact for tree-based ensembles, the selection of important variables prior to training a model should not be necessary as they already have this capability built-in. For logistic regression models, it may be beneficial to create models with only important variables. However, in this case, the differences in statistical values don’t appear to be significant. Despite the non-significant difference in this example, it should be noted that it is useful to create models with only important variables, as this always improves the explicability of the model.
The accuracy of all models is inline with statistical results in the scientific paper and are higher than the baseline accuracy set by KNIME in this challenge.
This was a really interesting and enjoyable challenge ![]()
You can find my workflow here on the hub:
Enjoy it!
Heather
9 Likes
OMG, Heather! This is so detailed and insightful! Thank you very much for the great contribution to our community!
3 Likes
Thank you @alinebessa ![]() I’m happy to contribute and I really enjoyed this one!
I’m happy to contribute and I really enjoyed this one!
2 Likes
Wow, @HeatherPikairos, this is beyond impressive! Congratulations ![]()
Since you basically almost wrote a blog post around your solution, would you like to submit it to our community journal?
I’d be happy to help you shape it into a blog post (e.g., short intro, addition of meaningful screenshots) ![]() .
.
5 Likes
Hi @roberto_cadili thank you, that sounds like an interesting idea! ![]() Can we discuss this by email to see if it could be a possibility?
Can we discuss this by email to see if it could be a possibility?
Thanks
Heather
4 Likes
@HeatherPikairos wow. worth the wait!
3 Likes
Thanks a lot @l6fader ![]()
1 Like
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.