This week you’ll take the role of a clinician and see if machine learning can help you predict whether a patient has diabetes or not.
We spiced it up a bit and also asked you to beat a given baseline accuracy! Are you up fot this challenge?
Here it is. Let’s use this thread to post our solutions to it, which should be uploaded to your public KNIME Hub spaces with tag JKISeason2-19.
Need help with tags? To add tag JKISeason2-19 to your workflow, go to the description panel on the right in KNIME Analytics Platform, click the pencil to edit it, and you will see the option for adding tags right there. Let us know if you have any problems!
Here’s my solution. Used AutoML and Global Feature Importance. Has three models with different sampling appproaches. No attempt at optimization beyond different sampling approaches.
Why did the oversampling using the SMOTE method not take effect? I tried to change the hyperparameter, with the nearest neighbor=30 (default=5), and the effect has improved.
In addition, due to only a small number of samples in the validation set, this score may have already overfitted both the training and validation sets.
Hi everyone,
Here is my solution:
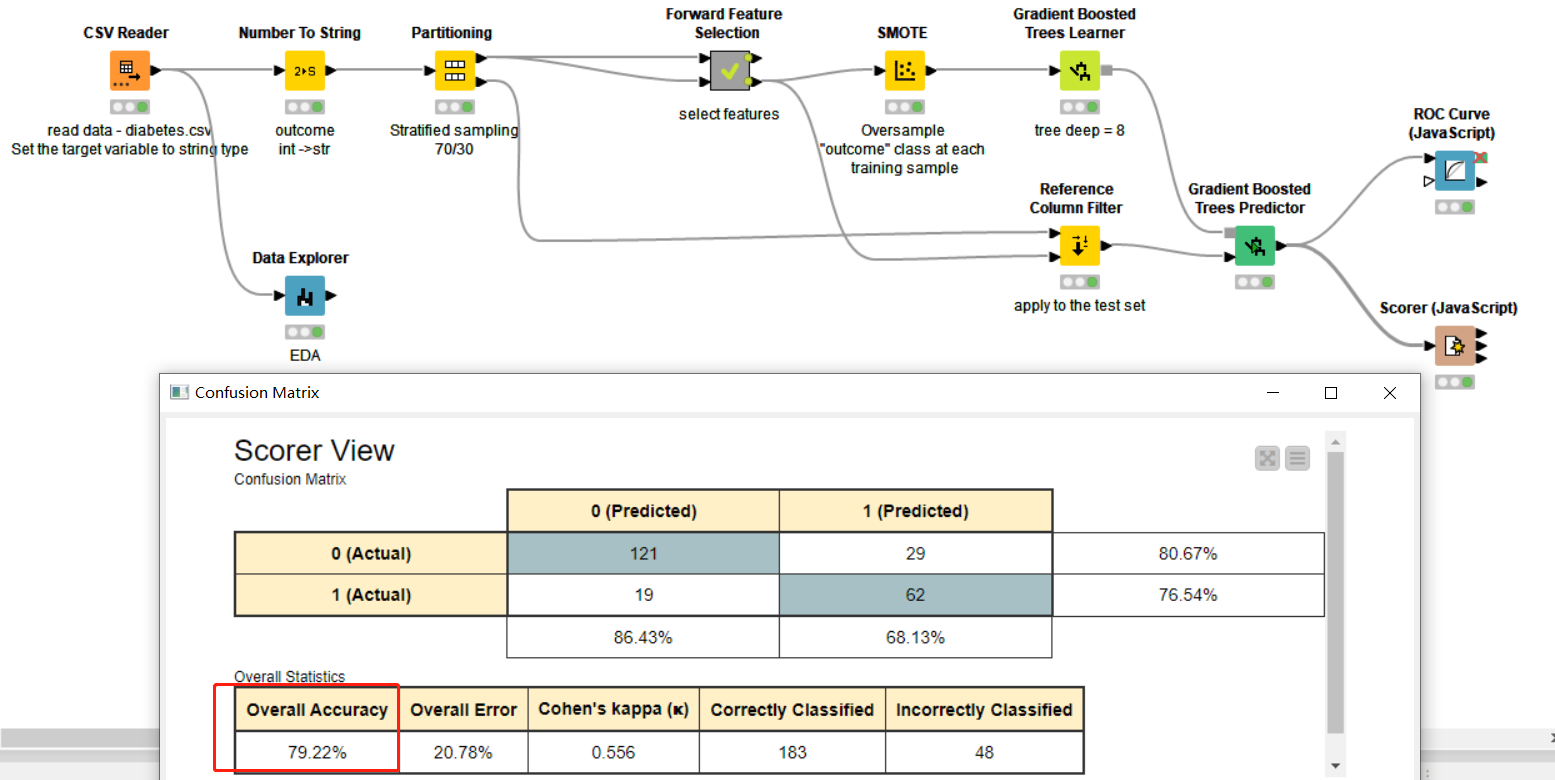
I used stratified sampling (70/30), removed feature “SkinThickness” (result of experiments with xgboost) from data and used Random Forest with default configuration. Accuracy = 79.22%
As part of the JKI Challenge 19 - Dealing with Diabetes, the Auto ML component was utilized to determine the optimal model for classifying patients as either diabetic or non-diabetic. Following this, the Global Feature Importance component was employed to identify the two most crucial features that contribute to a diagnosis of “Diabetic” or an Outcome value of 1 in the model. Finally, a Scatter Plot was generated using complete data to explore how these two key components interact and ultimately indicate an elevated risk for diabetes.
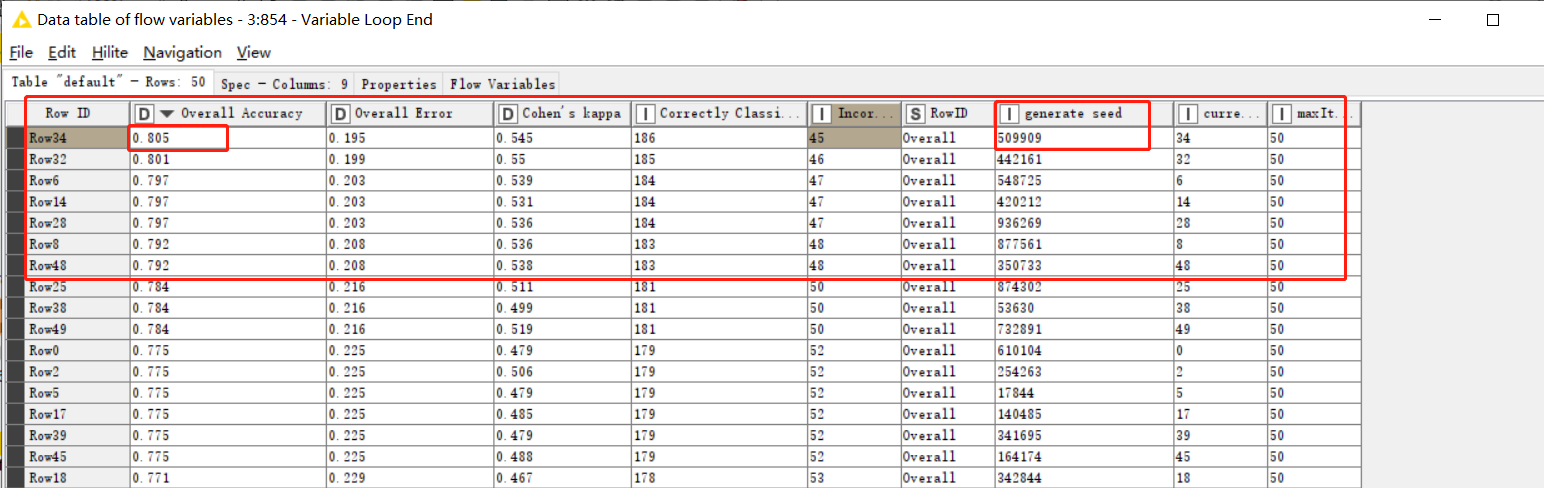
My personal opinion: In fact, some models and sampling methods have randomness. Due to various limitations, most of the time we can only fix the seed, which can lead to some deviations in model comparison.
Perhaps you have noticed that there are issues with the 0 values of some columns on this dataset, but I have not addressed them either. There is a notebook on Kaggle that analyzes this issue.
Hi Everybody,
I’m back after a one week absence. Here is my solution, which is far less sophisticated than some of yours. Like all of you, i started with the AutoML and Global Feature Importance components but for some reason, i could not get the AutoML component to work. In order to join the fun, i just started from scratch and tried to answer the challenge’s main points.
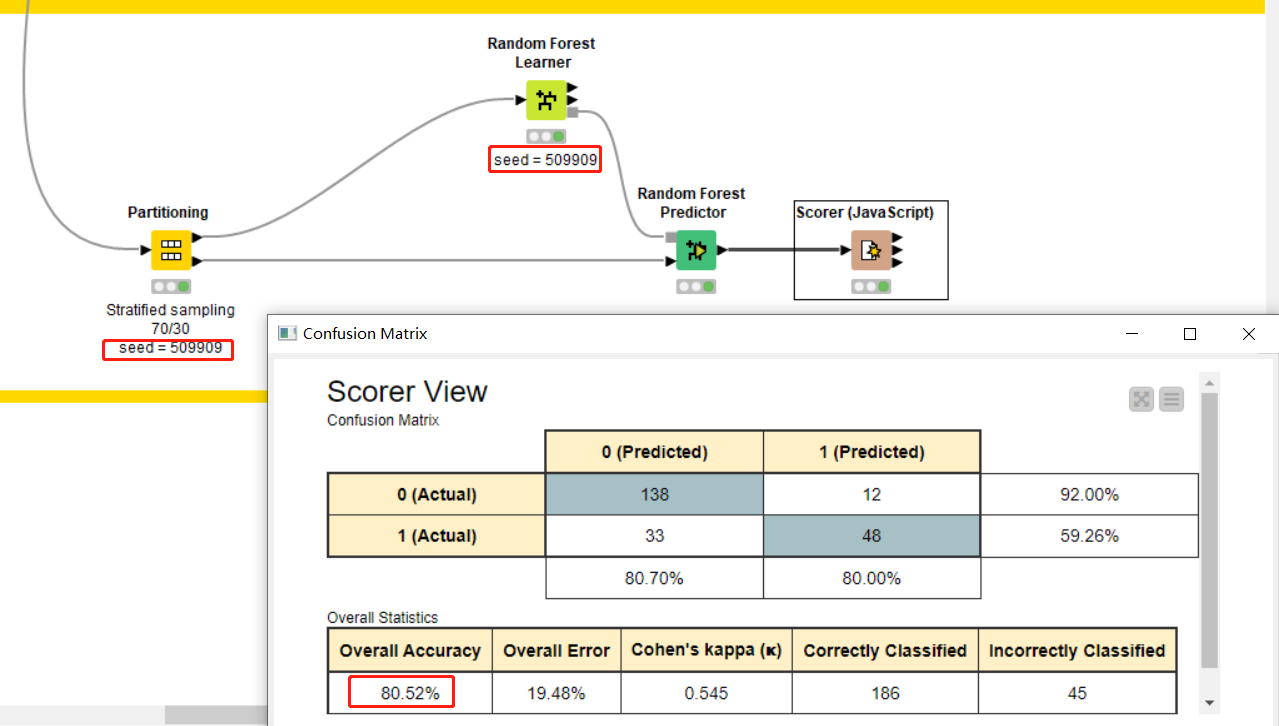
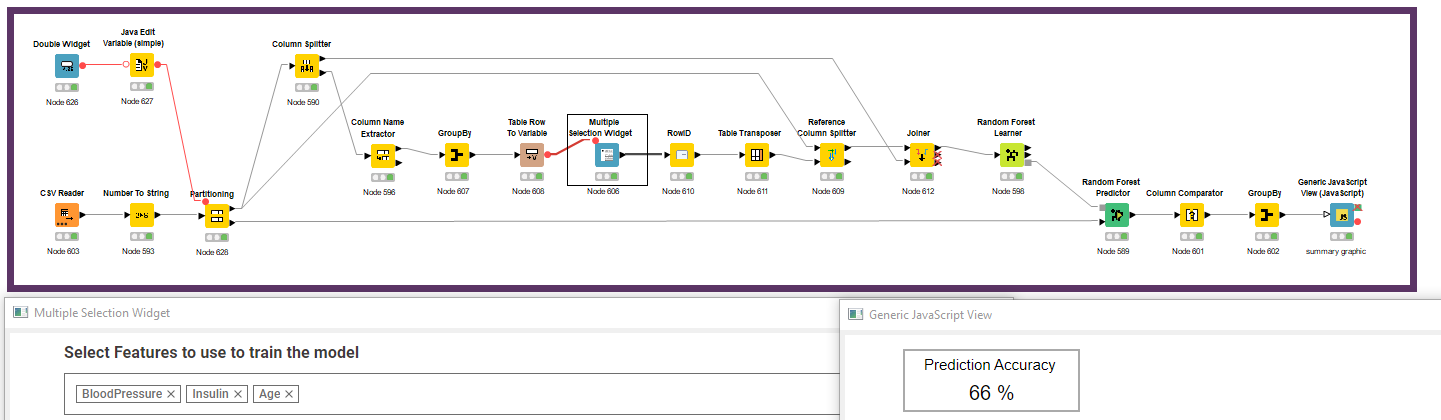
Here is just created a simple Random Forest classification model with 90:10 partitioning of the data. I created a simple KPI output to display model accuracy. 78% was not bad. Easy-peasy.
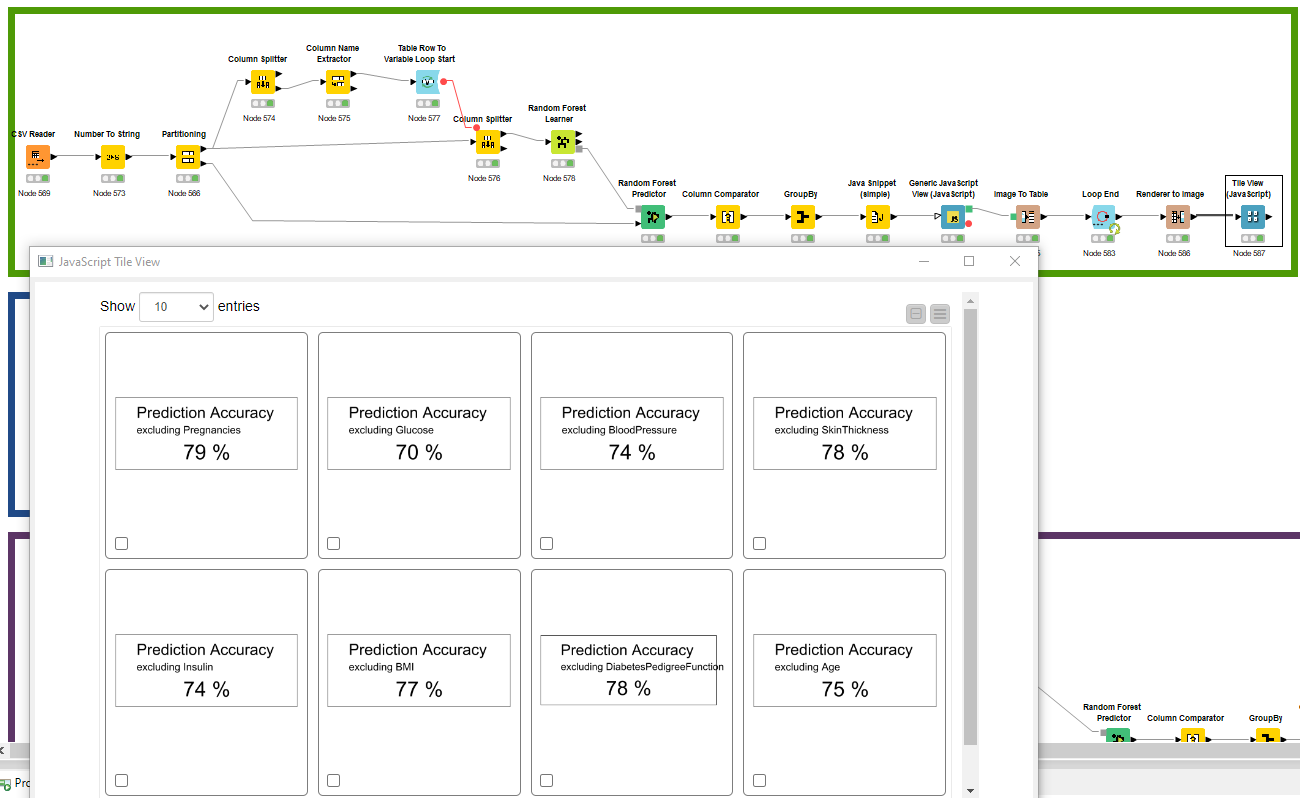
This modification was designed to assess feature importance in a really crude way. Model performance is compared by removing each feature one at a time with a loop and assessing model performance with the same KPI output in a tile view. Here we learn things such as; 1) when the pregnancies feature is removed, Prediction Accurancy is better; or 2) when we exclude the Glucose feature, Prediction accuracy is worse.
This modification allows you to vary the sampling split for train/test. The split is still randomly done, but even still i could see changes in performance.
Armed with the knowledge of which features where most important, a multiple selection widget was added to allow simpler models to be built and compared. Here we can balance the number and importance of features required to meet the performance standard.
I have run the workflow you shared and there are no issues. I copied AutoML from your workflow to my workflow, but there are still exceptions. I’ll check my local configuration again. Thank you!
Hi there. I have also encountered the problem with AutoML in v5.1.
I checked a simple workflow from the hub that works in 4.*, but also fails in 5.1.
So it might be a problem with the new KNIME version.
best, Tommy
having similar difficulties running autoML on my new knime 5.1 installation as i’m on my Linux machine.
autoML works fine on my 4.7.5 installation, so it is possible that there is a compatibility issue.
Here is my solution, and I have to say that challenge this week is quite exciting and interesting for me. First of all it is really nice and helpful to build the model factory - this might be useful for other projects. And with the help of the components for AutoML and Global Feature Importance it is quite easy. There was a hint to implement different sampling strategies, so having this feature is also helpful.
The only problem that I could not solve efficiently is the dependence on the sampling: as long as we do not have much data and data set is unbalanced, sampling really effect the end results. Let’s say I could get 85+% accuracy while training, however on test set it only gave me ~75% and vice versa.
Considering feature importance, it seems that BMI and Glucose are the most valuable features.
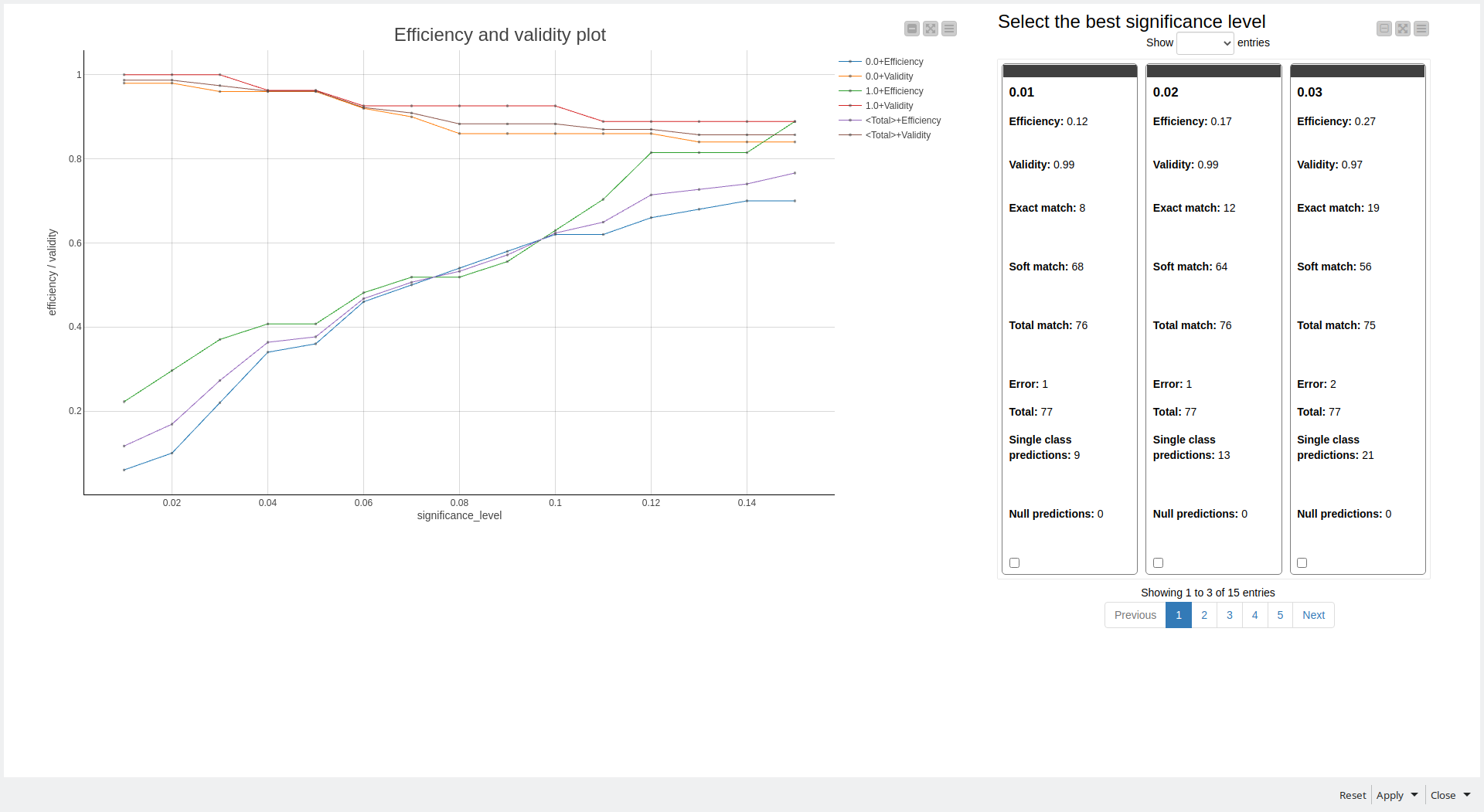
And of course I added my favorite conformal prediction approach that actually helps to find the most difficult cases for prediction and also compliments the feature importance analysis.
This isn’t the first time I’ve seen you use this prediction method. Do you have any best practices to share about this algorithm? I’m ready to learn about it. Thanks!
my petty try on the challenge.surprisingly Automl started showing error on changing the sampling node like smote or bootstrap. this was due to breakpoint. the accuracy if 76.52 .My flow is not spohisticated vis a vis peers.