Happy Wednesday, everybody! This week we’re back with a medium-level Just KNIME It! challenge. And remember: even if you can’t solve an entire challenge, there are always easier objectives for you to play with. We are all here to learn!
This week you’ll explore what drives global listening trends. Using a dataset of most streamed songs up to 2024, your goal is to uncover which artists dominated the charts. Which artists released the most music? And who ranked highest in average track score? Discover which artists make the cut on both popularity and consistency.
Here is the challenge. Let’s use this thread to post our solutions to it, which should be uploaded to your public KNIME Hub spaces with tag JKISeason4-22 .
Need help with tags? To add tag JKISeason4-22 to your workflow, go to the description panel in KNIME Analytics Platform, click the pencil to edit it, and you will see the option for adding tags right there. Let us know if you have any problems!
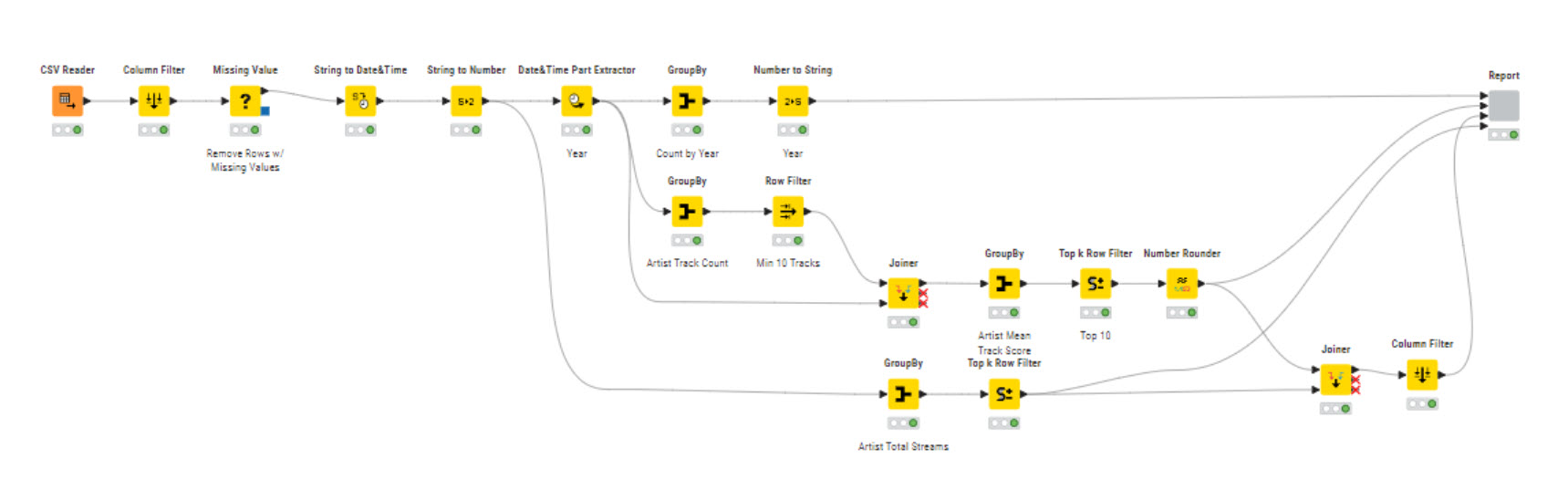
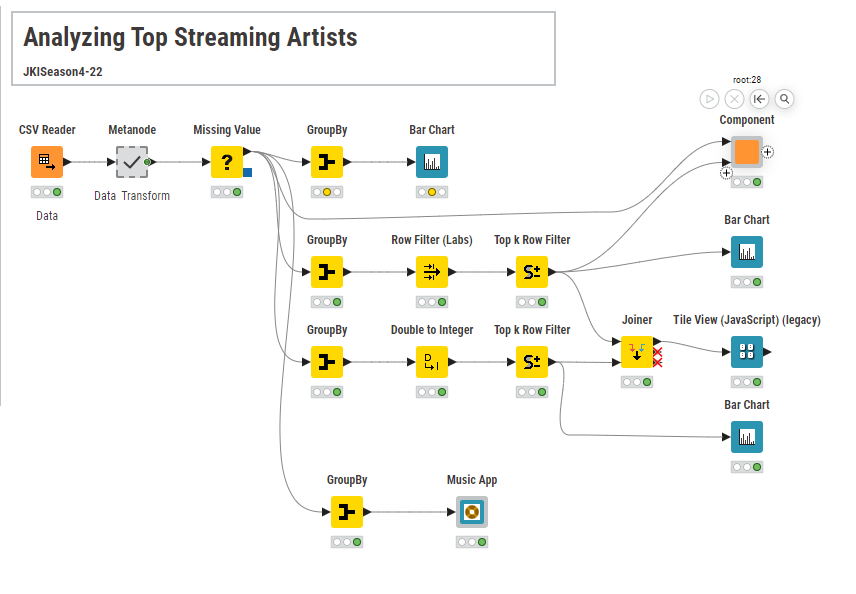
I noticed some strange track name formatting, most likely to a change in the encoding. This is not handled here, but should be done for a prod workflow. Same with duplicates, nothing is checked in this current workflow, but should be done - also some inconsistency checking (dates, etc.)
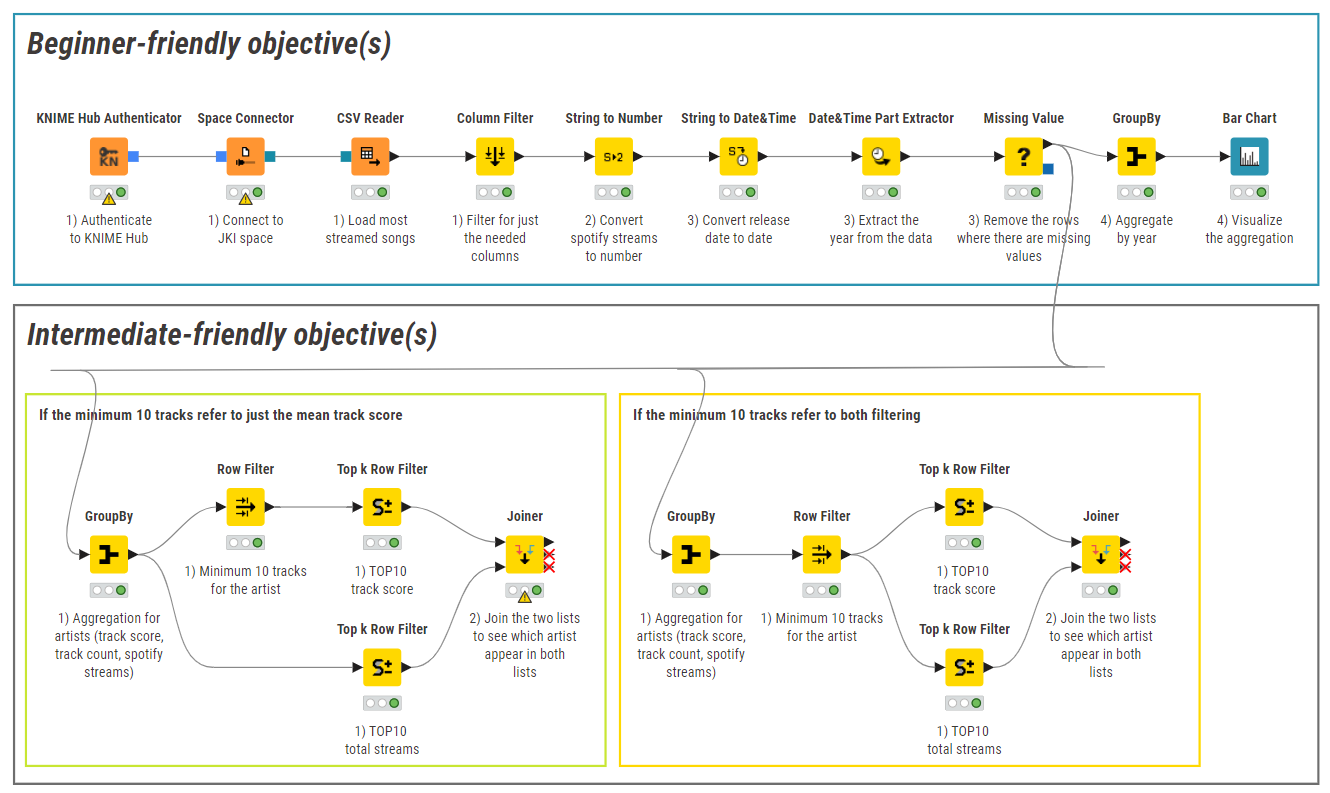
just filter for the needed columns and convert them to the needed data types (filtered out all the missing values)
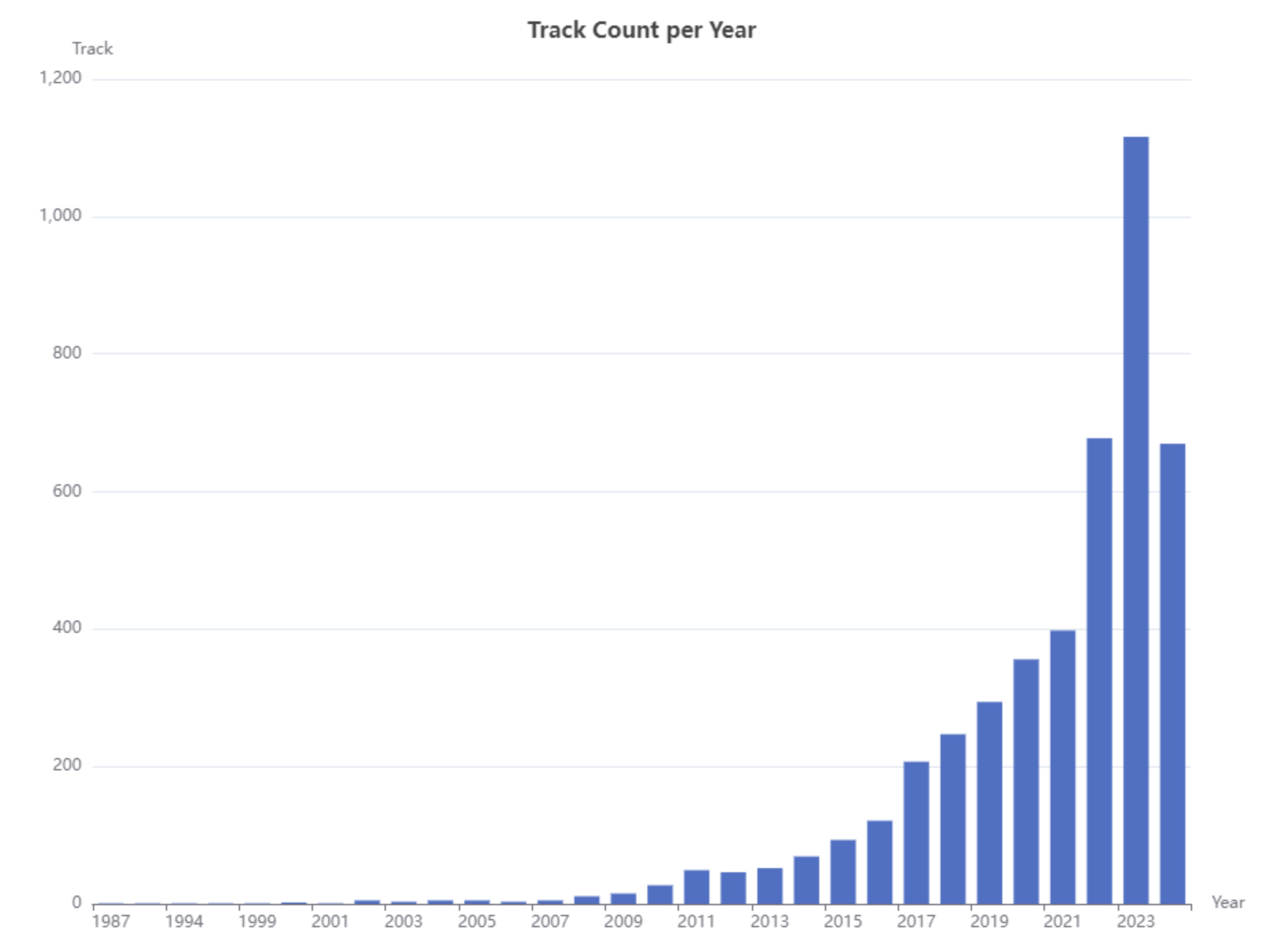
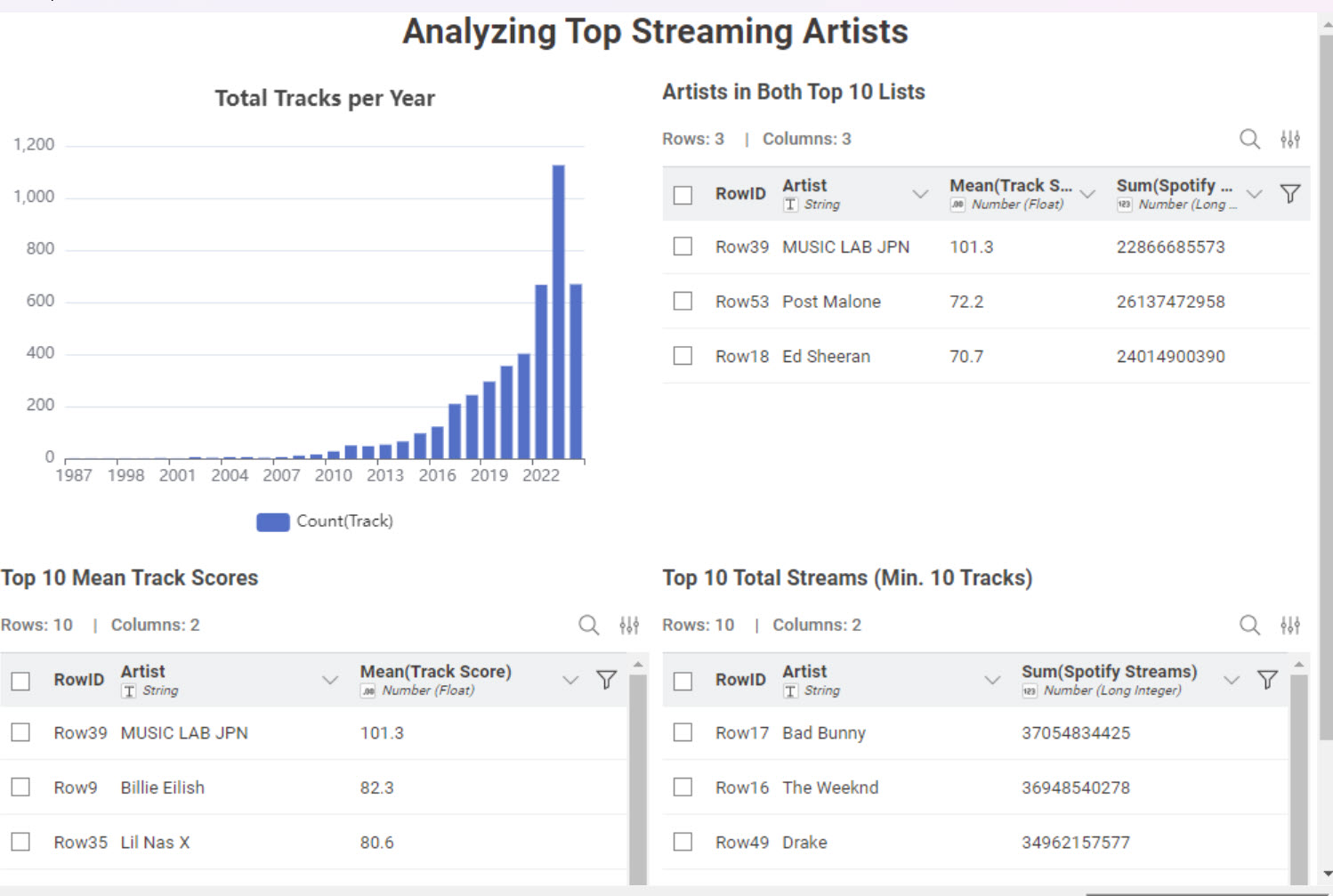
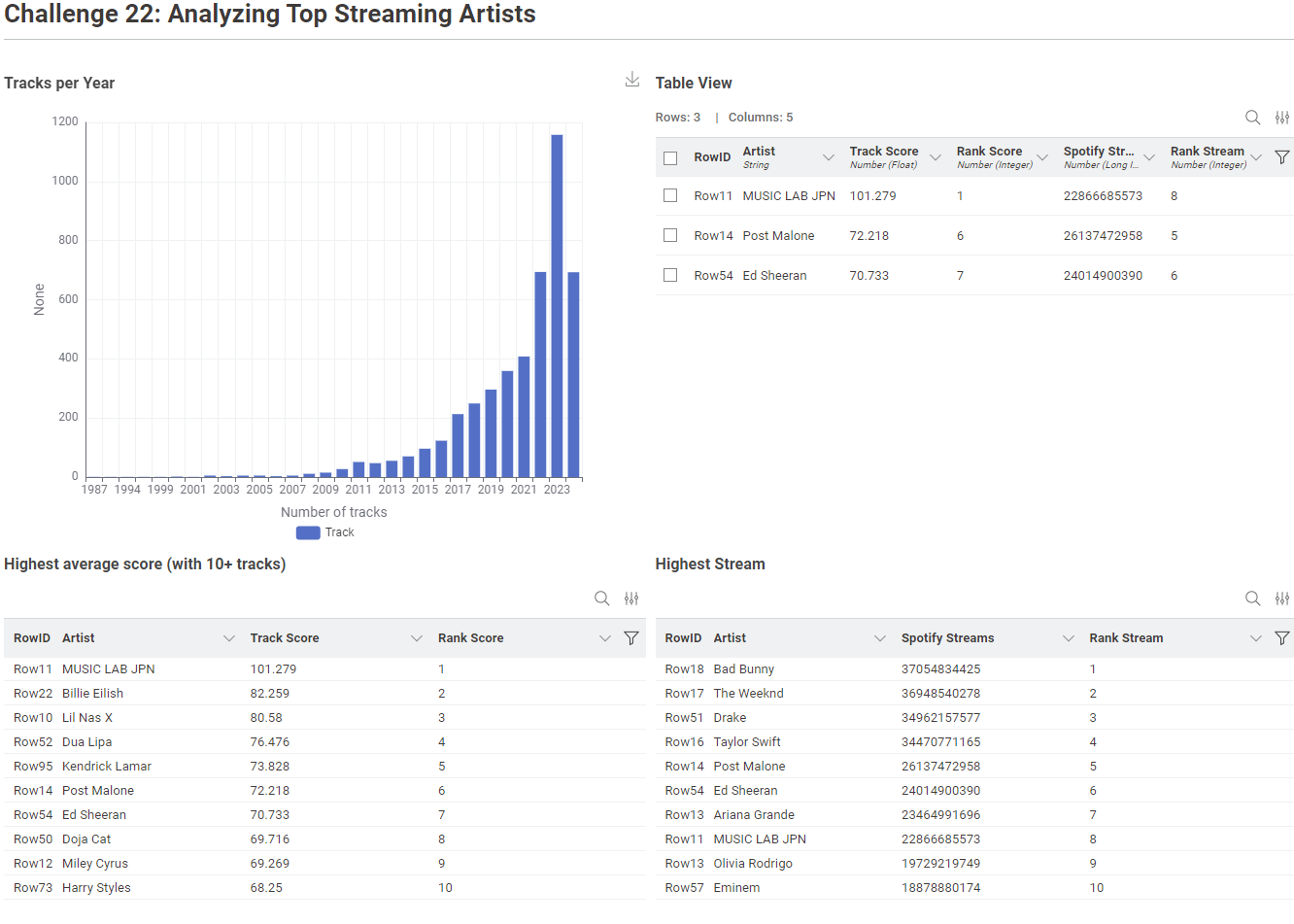
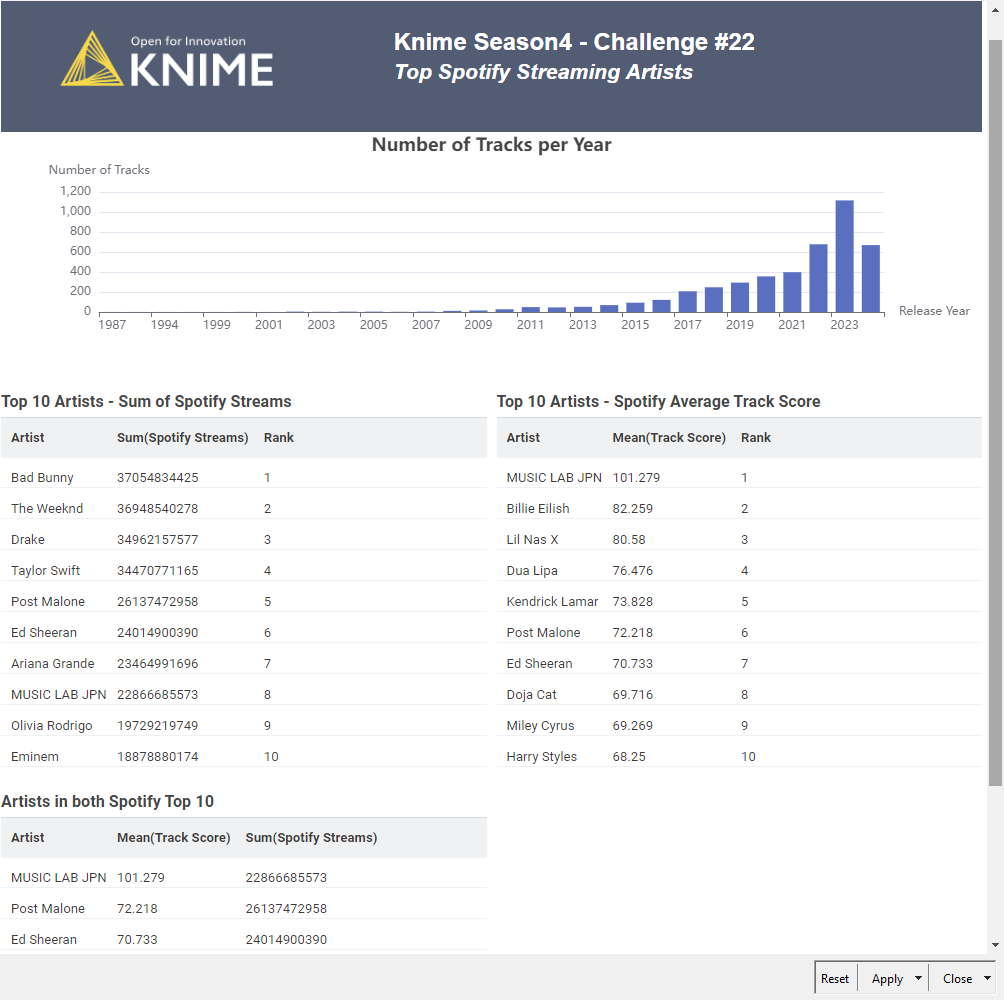
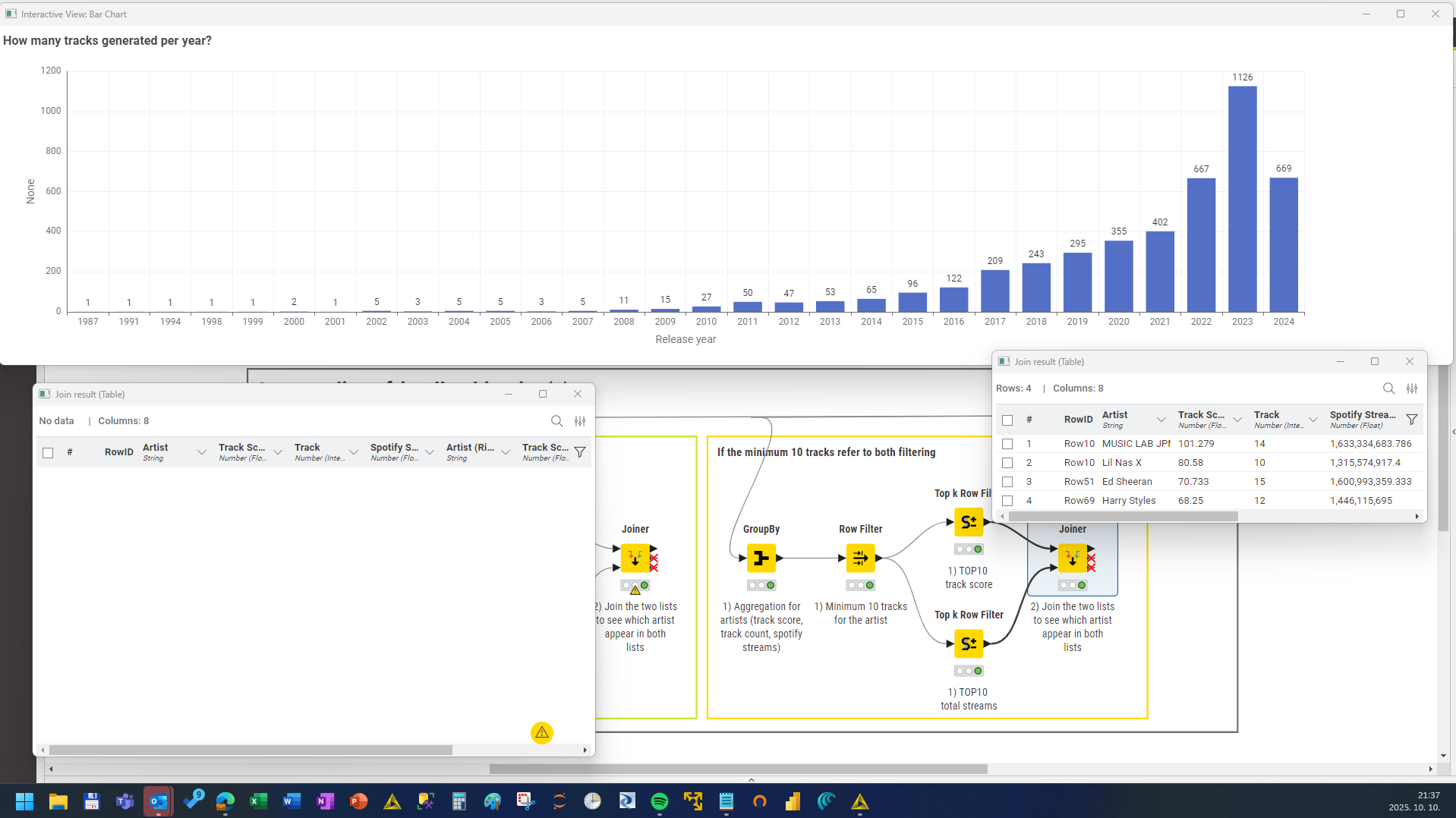
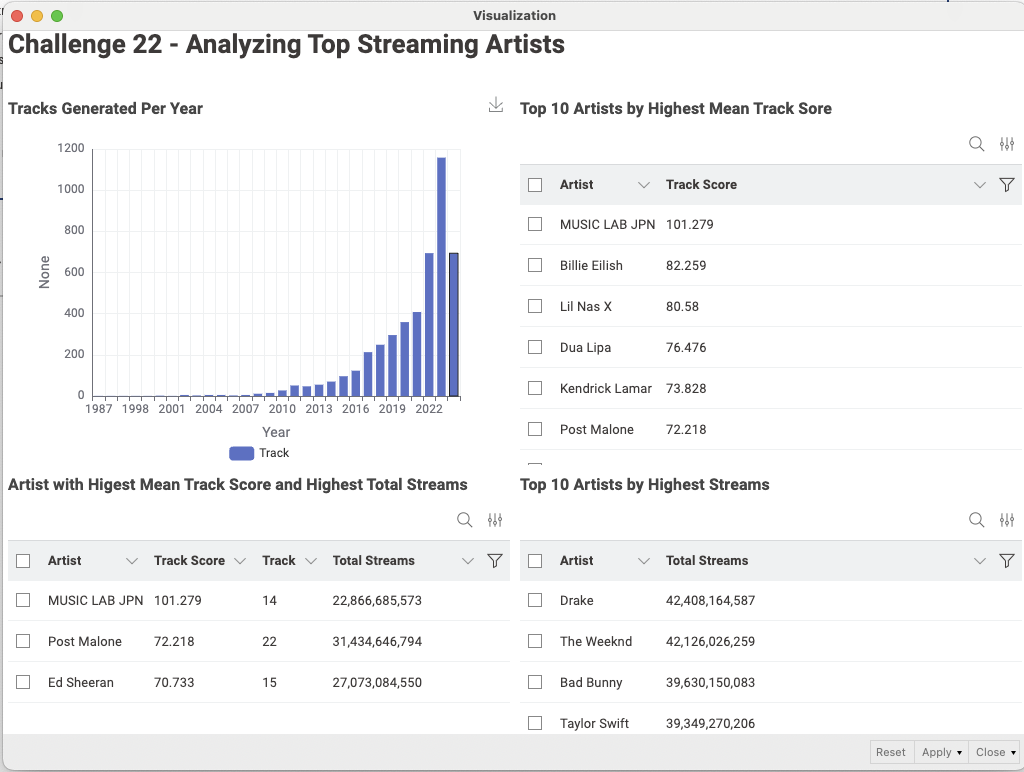
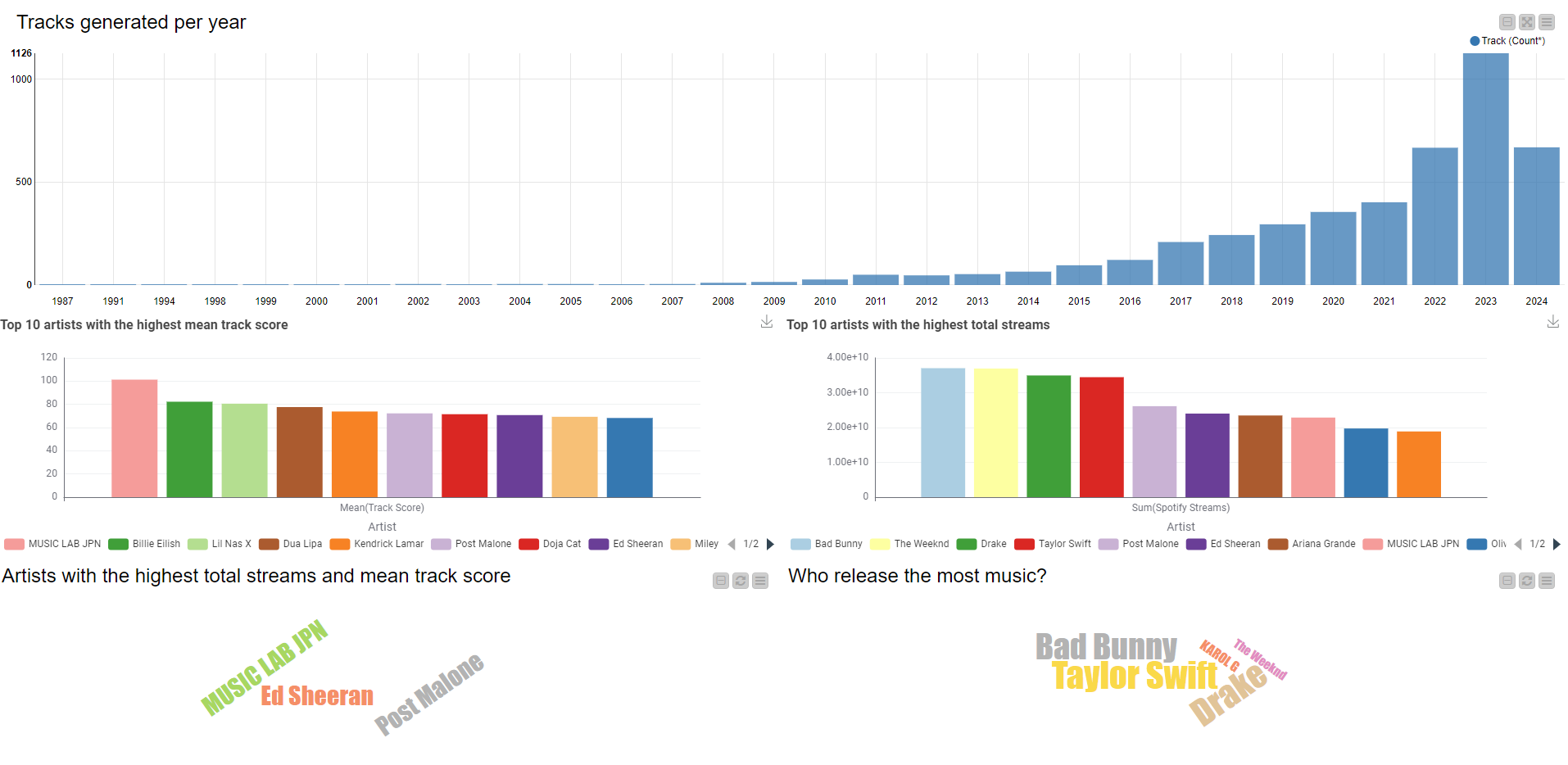
Aggregate the data to year and visualize it in a bar chart
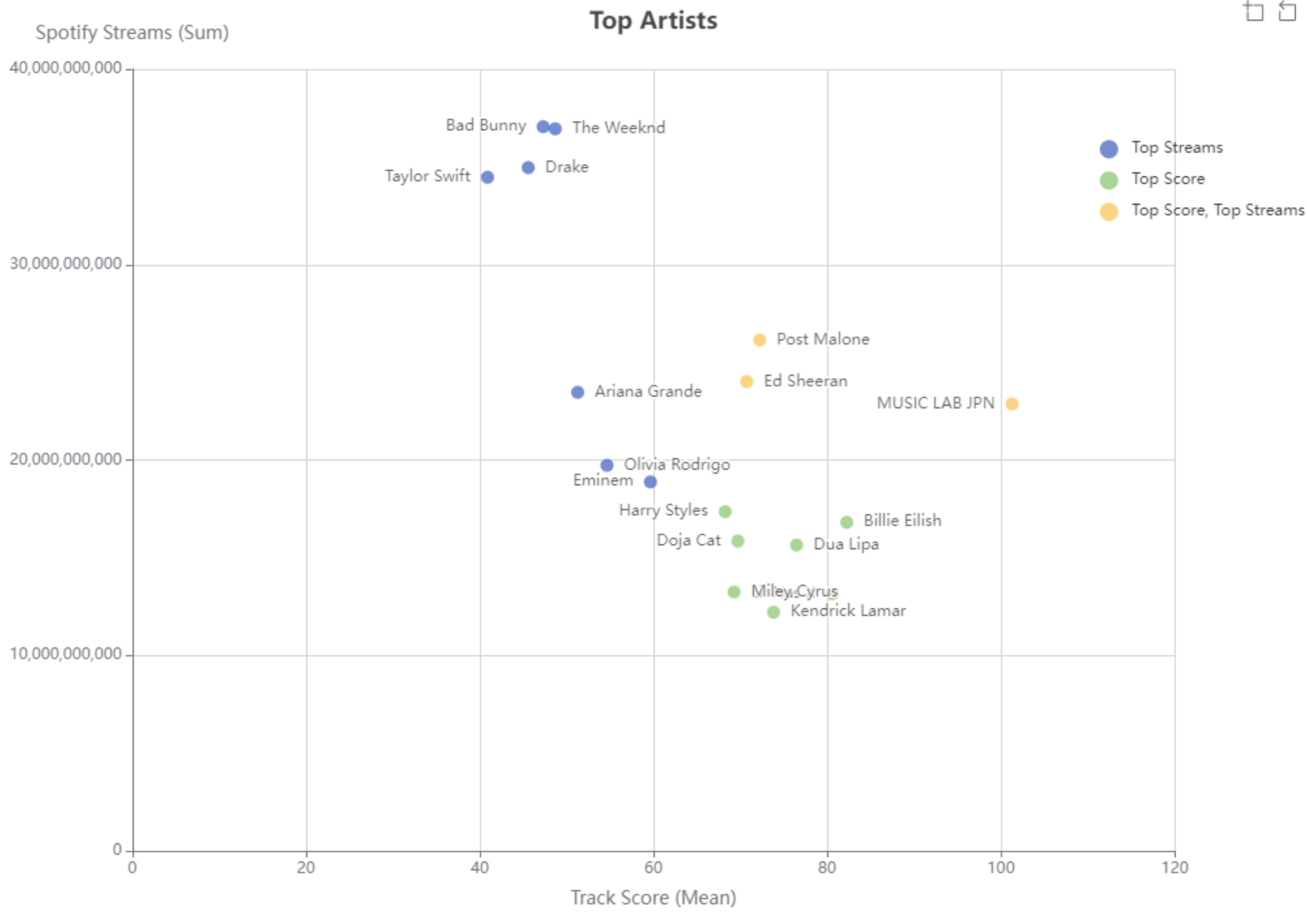
Get the TOP10 track score and TOP10 total streams and check if there is some overlap between the two lists
I started with the assumption with the minimum 10 tracks just refer to the track score (I understood from the task description like that) –> In that way, there was no overlap between the two lists
From that I thought that is not the right approach, so I applied the minimum ten tracks for both track score and total streams, and in that way, there was four overlaps (MUSIC LAB JPN, Lil Nas X, Ed Sheeran, Harry Styles)
As I’m not sure which is the correct approach I kept both in the workflow
I tried to keep the documentation of the workflow to the maximum I’m really interested which approach is the correct one. If there is no overlap, or there is four. I think there will be answer in the solution on Tuesday
I had a difficult time getting a dataset where both artists had highest mean track score and number of total streams and looked at @trj workflow to understand how to get artists in both data sets and sometimes the problems lies in understanding the question and order of operations. I misunderstood that the count of tracks needs to be considered when determining highest mean track score and streams for the first 10 tracks. When using the count function I was then able to get a combined dataset for specific artists with both highest mean track score and highest total streams.
Our solution to last week’s Just KNIME It! challenge is out!
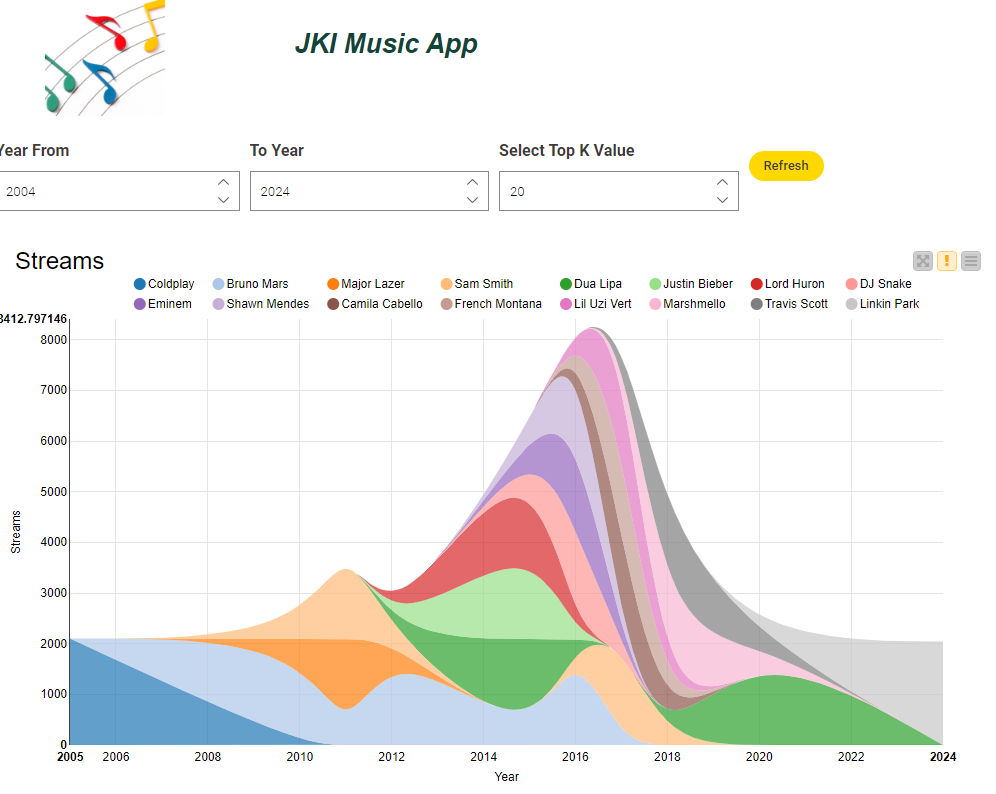
The last part of this challenge’s solution involved trend visualizations in streaming. We saw some incredible dashboards, and even creative custom visualizations!
Tomorrow we will focus on an important topic that we rarely explore: big data! Can you help the regional airport authority mine lots of data to predict flight delays with an accuracy above 80%?