Happy Wednesday, folks! As usual, a new Just KNIME It! challenge has just been posted.
Imagine that you want to investigate a few hypotheses in a population and need control data to assess your results. Often, you will have to create synthetic data to this end – which is your task this week with this statistical data puzzle!
Here is the challenge. Let’s use this thread to post our solutions to it, which should be uploaded to your public KNIME Hub spaces with tag JKISeason3-23 .
Need help with tags? To add tag JKISeason3-23 to your workflow, go to the description panel in KNIME Analytics Platform, click the pencil to edit it, and you will see the option for adding tags right there. Let us know if you have any problems!
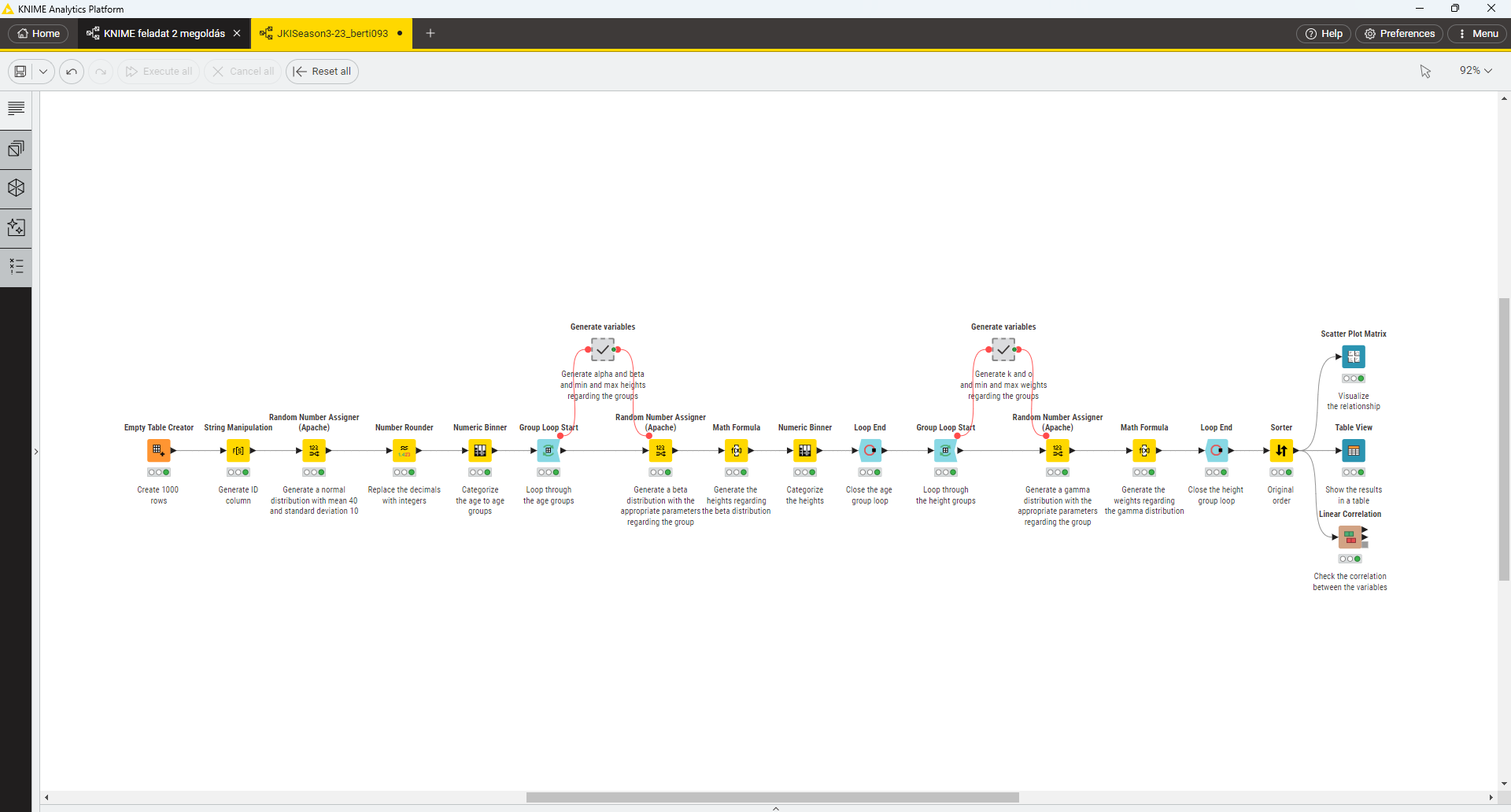
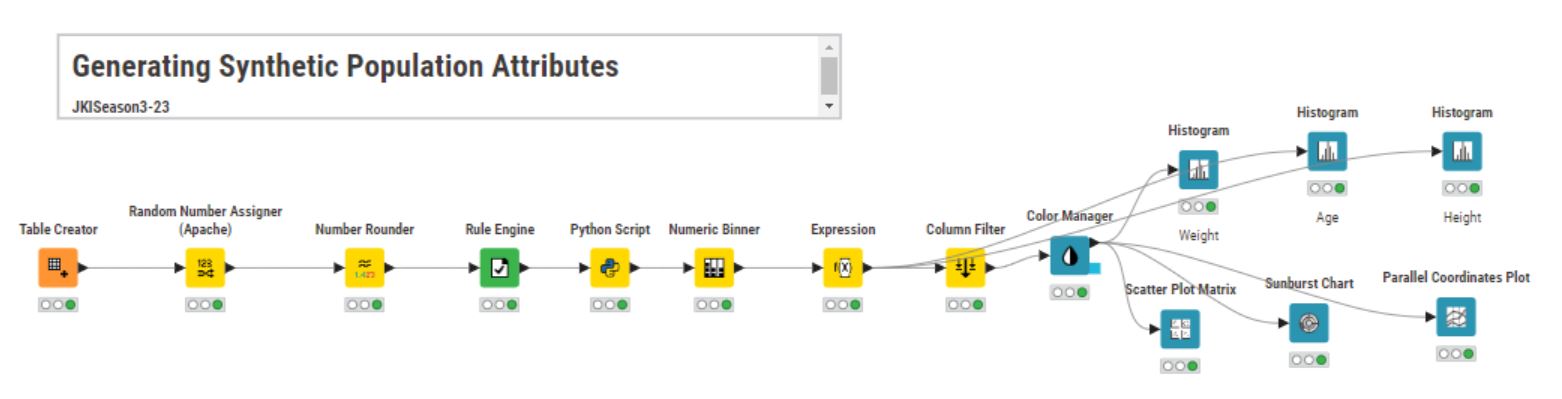
I heavily used the Random Number Assigner (Apache) node for the task as it has normal, beta and gamme distribution as well (I didn’t know about this node so far… I’m constantly amazed by how many KNIME nodes I haven’t explored yet!)
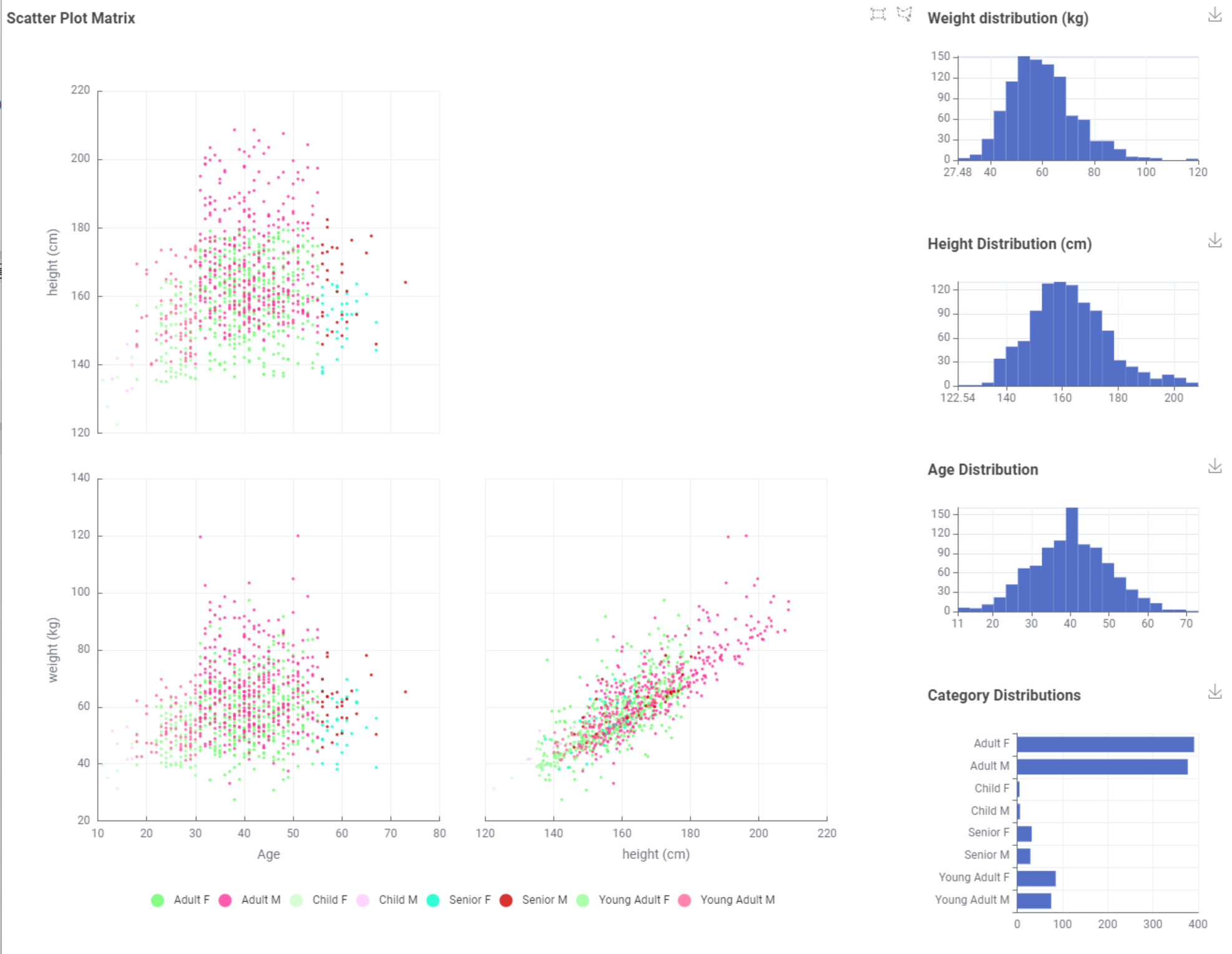
I generated ages using normal, heights using beta, and weights using gamma distributions. To be more realistic I have added some random noise (+/- 5 * rand()) to smooth out the categorical appearance in the data and introduce more natural variation.
While I’m sure one could create a more scientifically accurate population model, this is my initial attempt, and I’d love to hear your thoughts! I’m especially curious if there are ways to make my workflow more precise or if anyone has ideas for improving the realism of the data
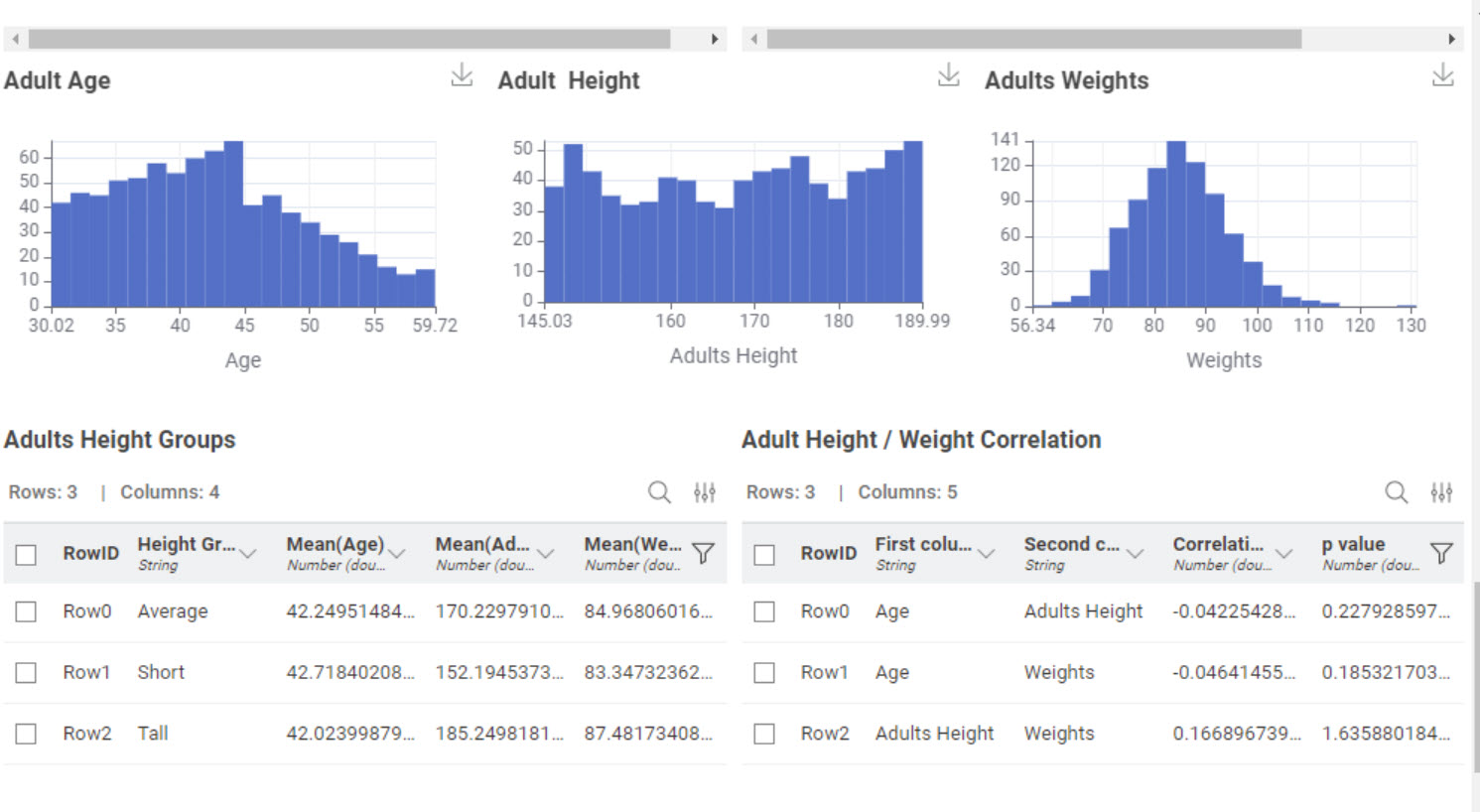
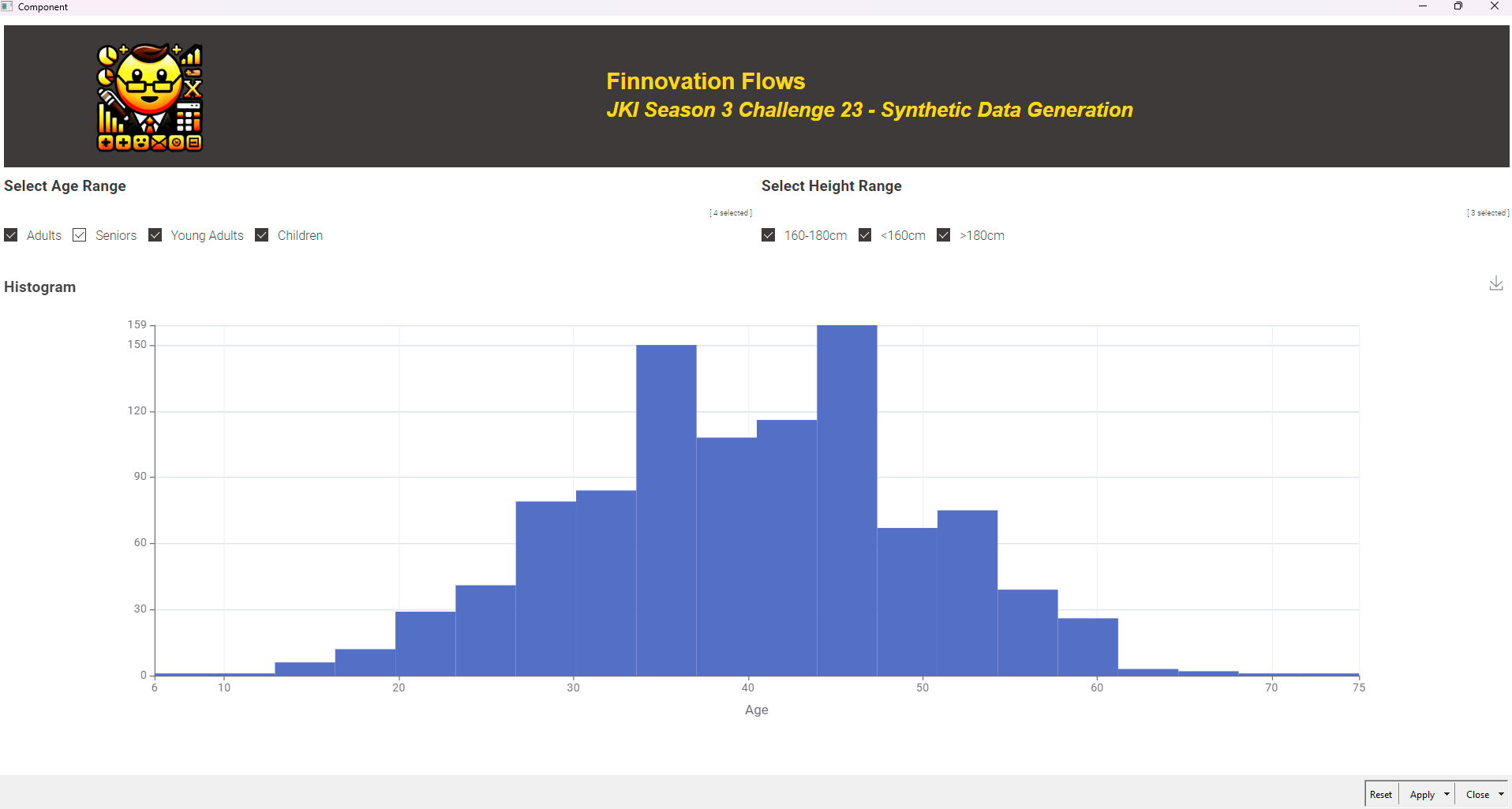
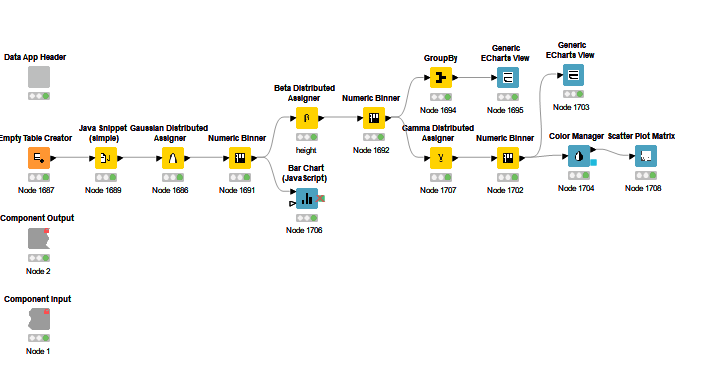
Here’s my solution. Component has a data panel for each of the age groups. “Adult” below as an example. Since the challenge didn’t specific a gender, I tried to develop height and weight data which includes both females and males.
I used the dedicated notes for the different distributions and that was quite a good experience.
I think someone may want to review the Description of the Gamma Distributed Assigner:
This sounded like e.g. if your Peak is 70 that the scaling should be e.g. 75 or 65… however this lead to weird results incl. the node ignoring the min/max boundaries. It seems that it works somewhat similar to the Beta Distributed Assigner (where p is ~1)…
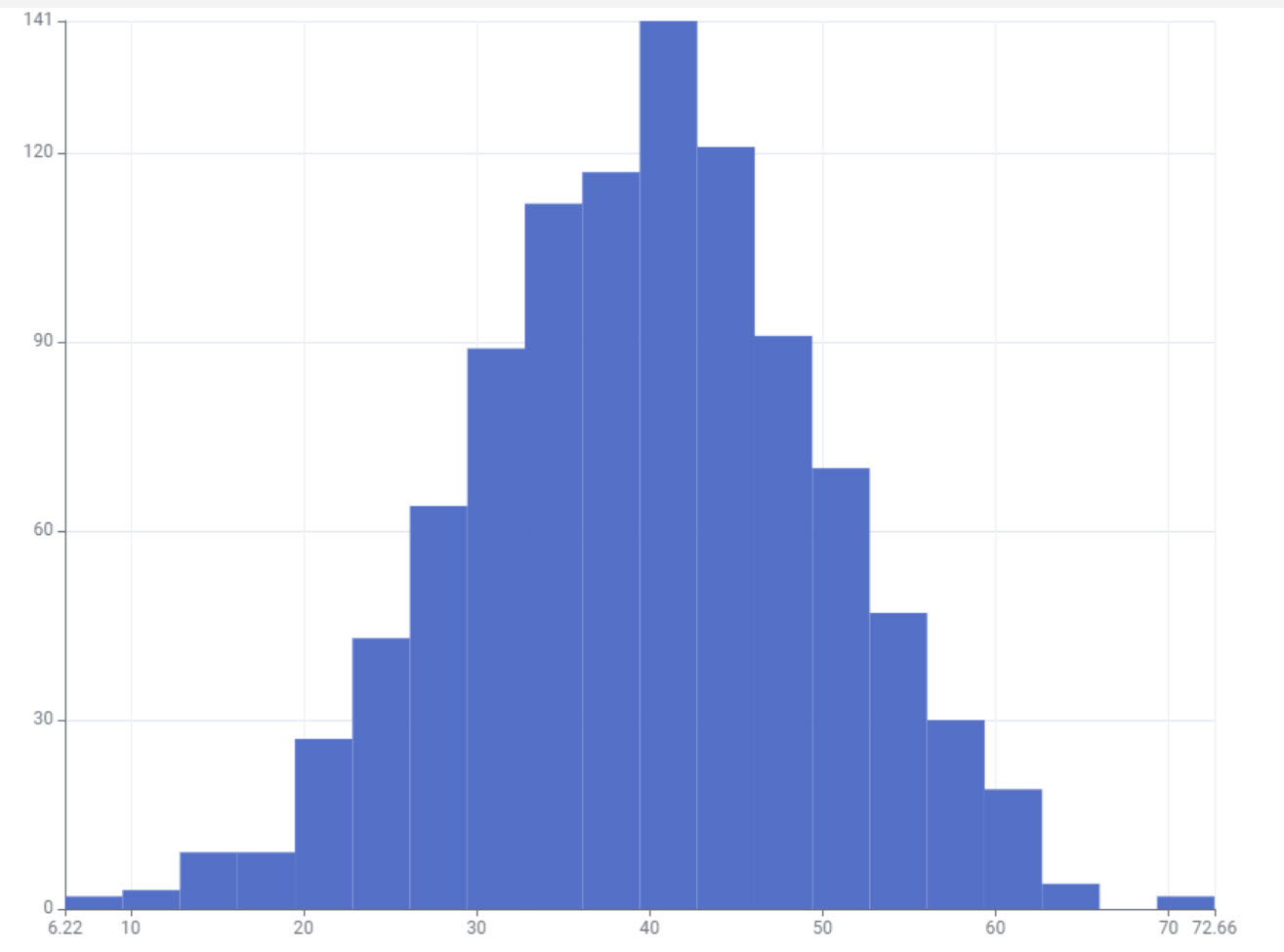
Anyways here’s what my component looks like - just a histogram that can be filtered by the “binned” age and height dimensions.
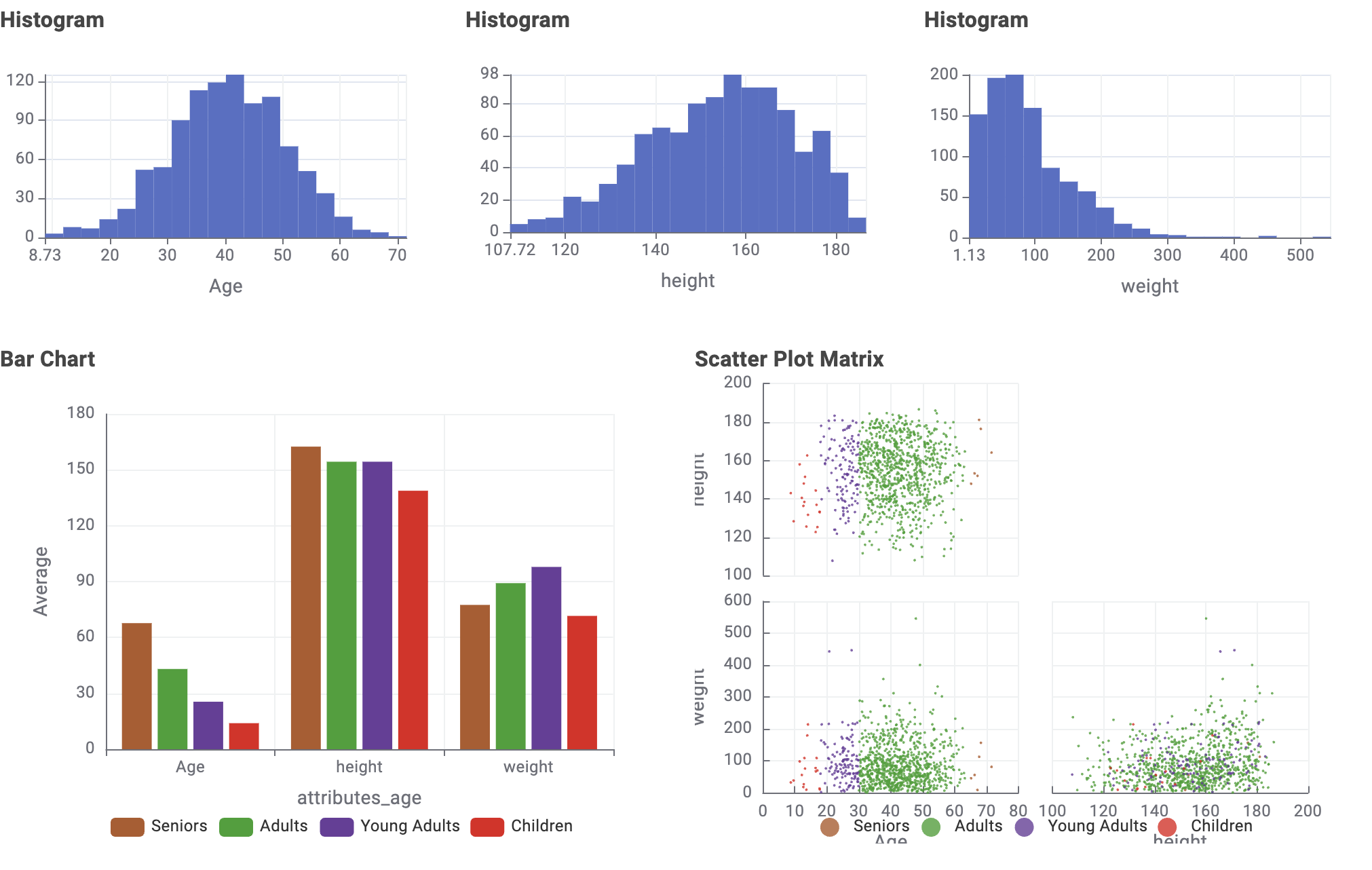
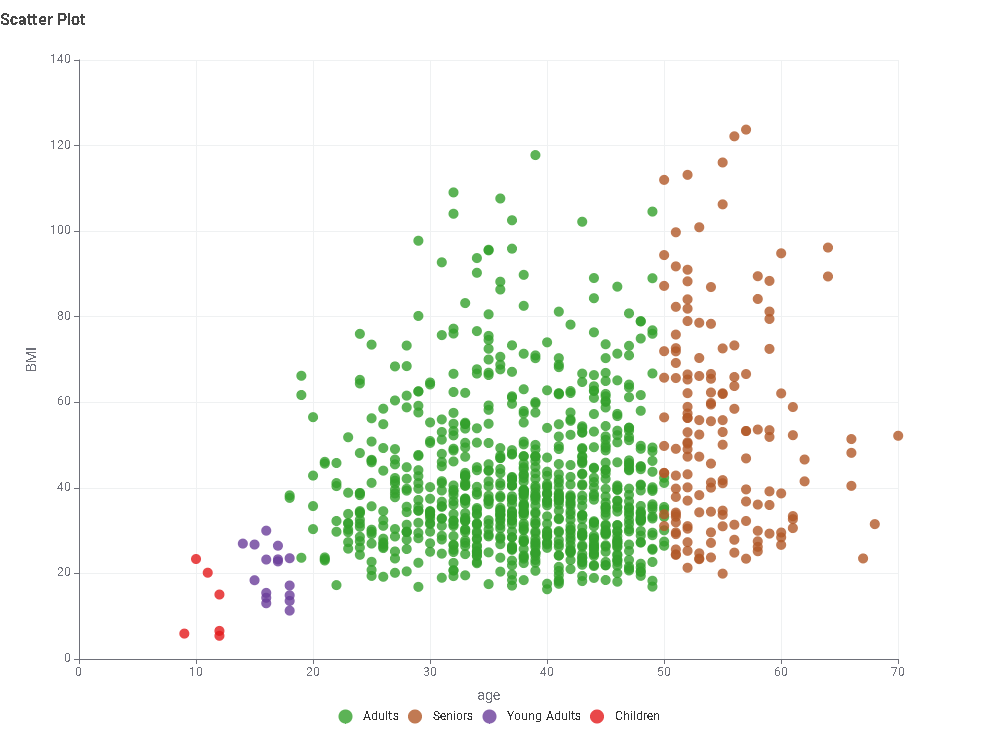
As @MartinDDDD said, the “Gamma Distributed Assigner” node did not work appropriately. In my case, I set max and min value for weight but both of them were not reflected.
So my workflow contains a person he has very high weight (more than 500kg… )
Hi all,
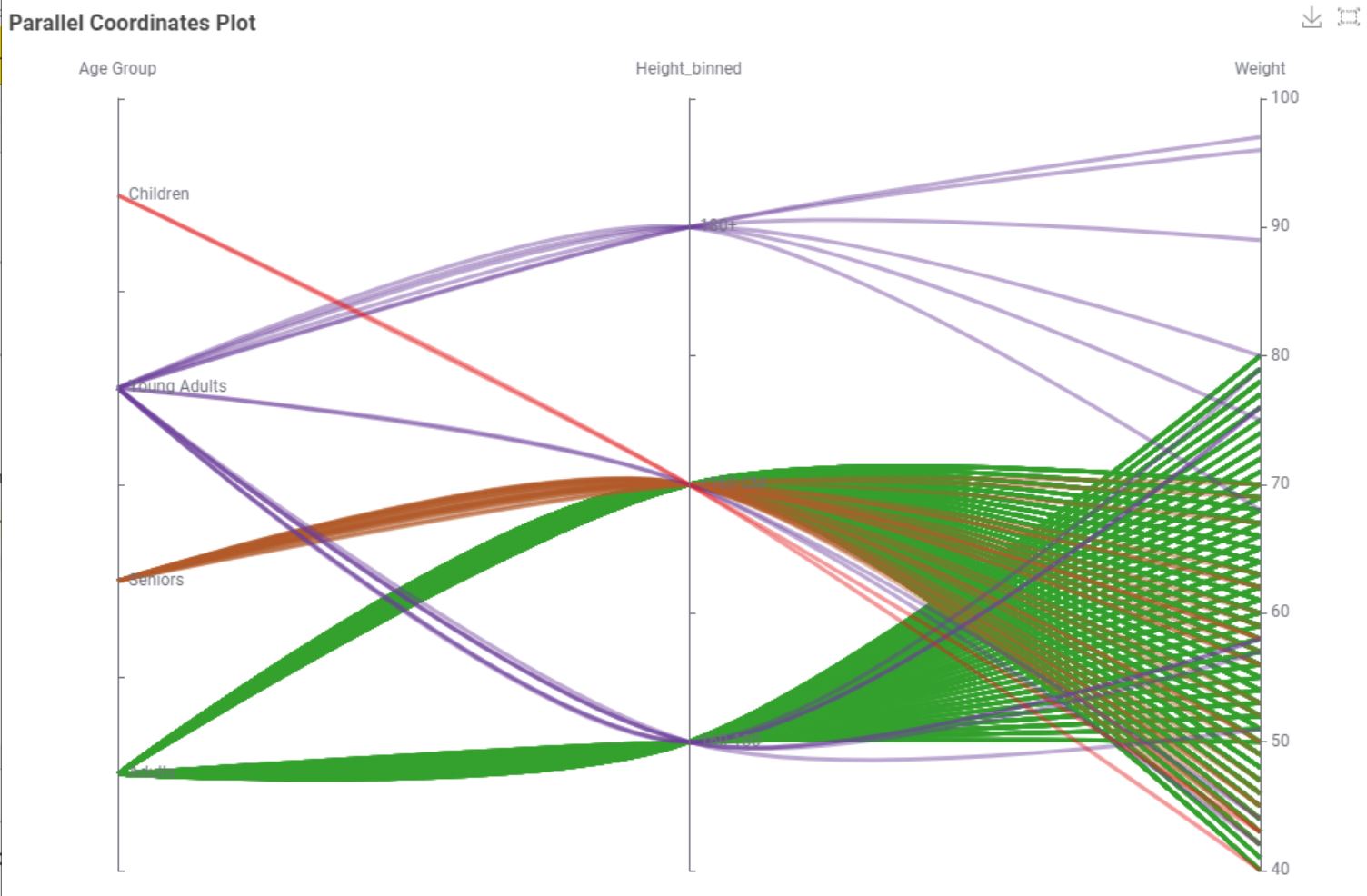
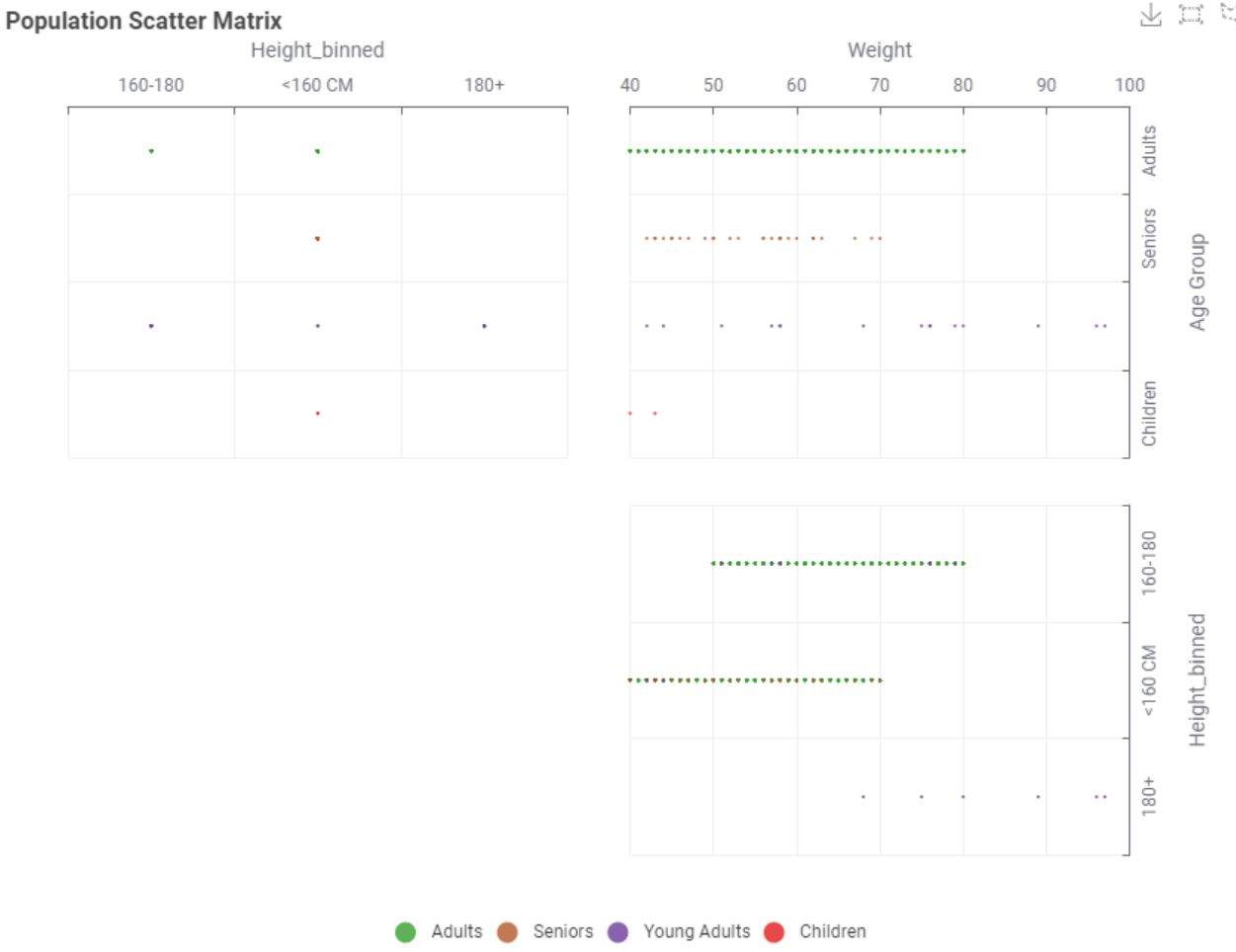
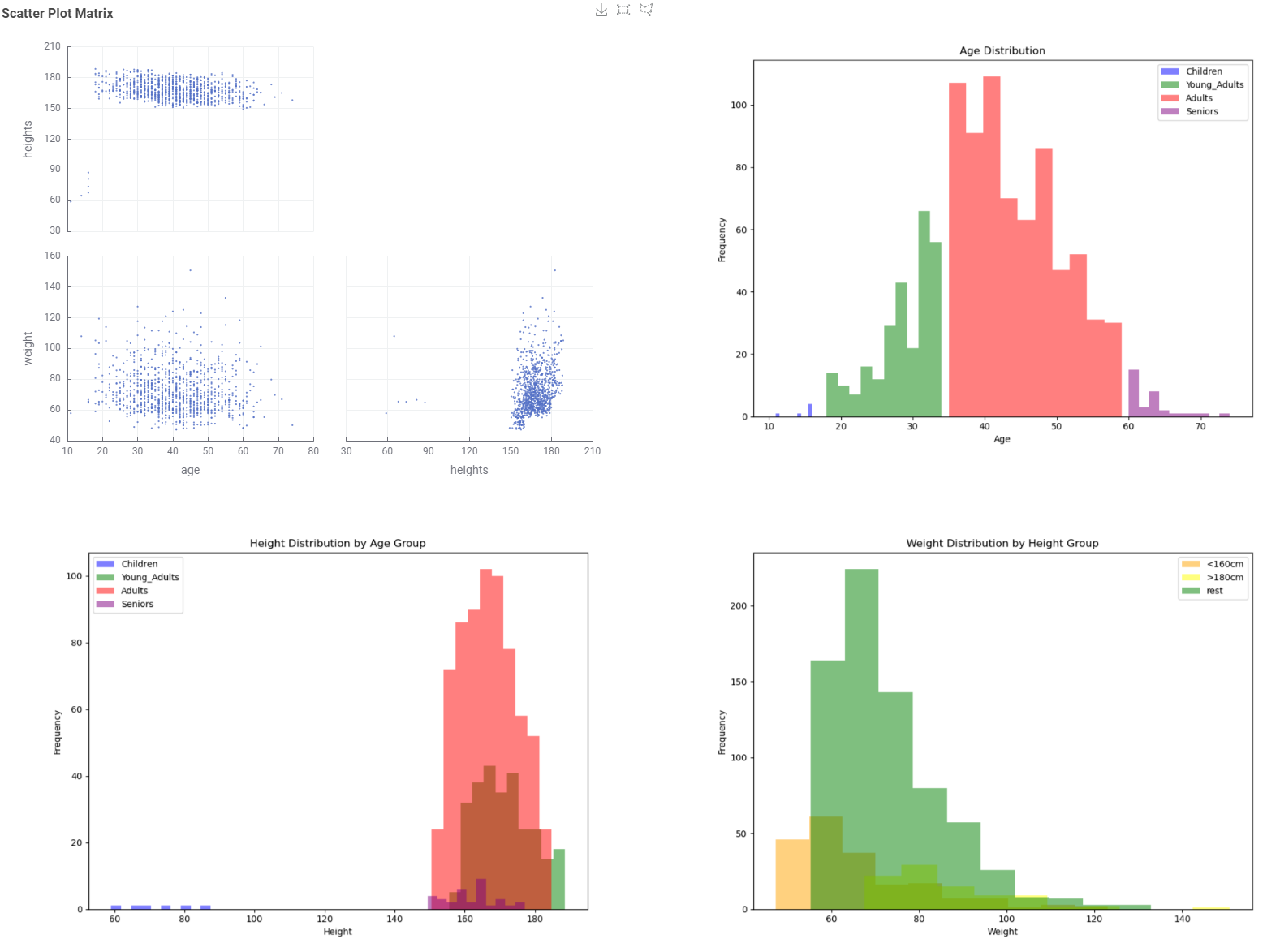
This is my solution. It was very difficult for me to create data for children effectively. As a last resort, I categorized the data further based on age and height
Added a gender categorization. Also had trouble with using the Gamma Distributed Assigner to generate the weights and just used it to generate a modifier for a weight calculation using BMI
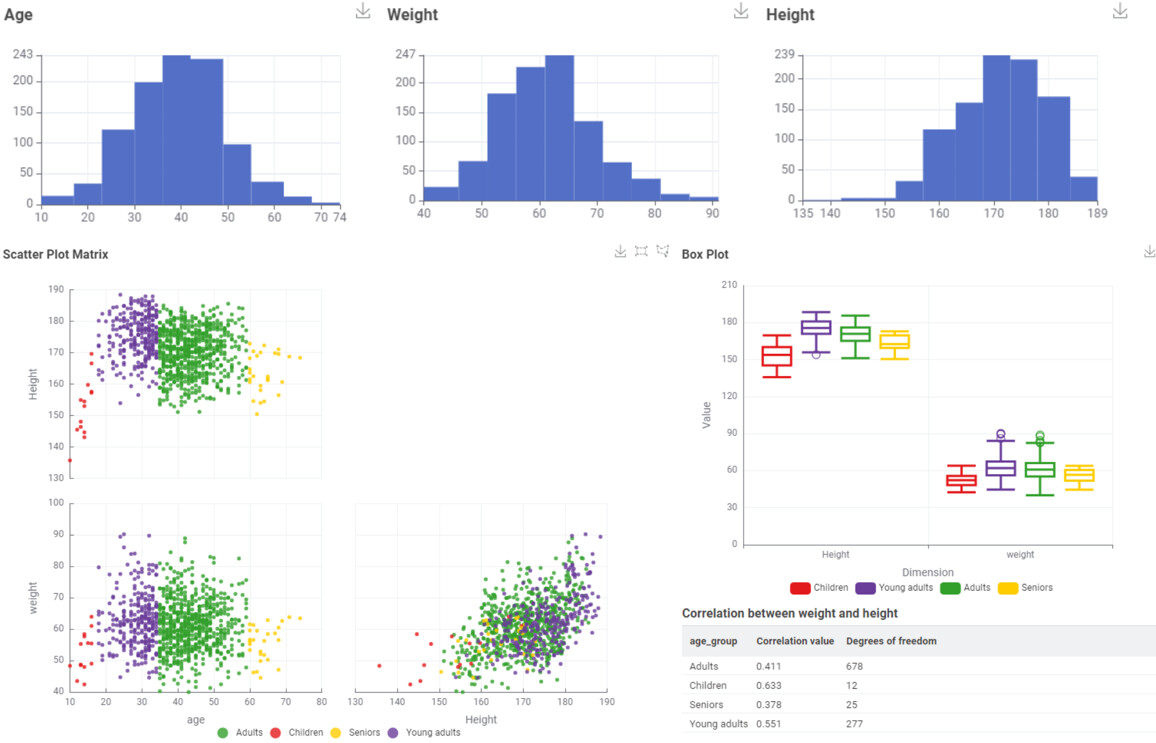
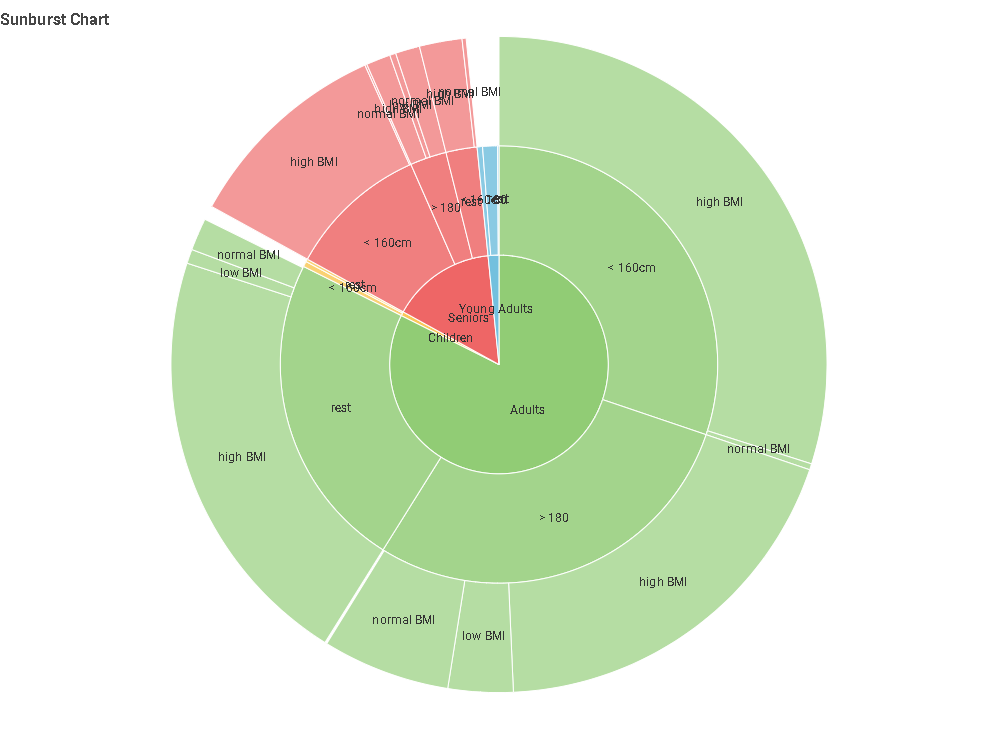
Here’s our solution to our data generation challenge.
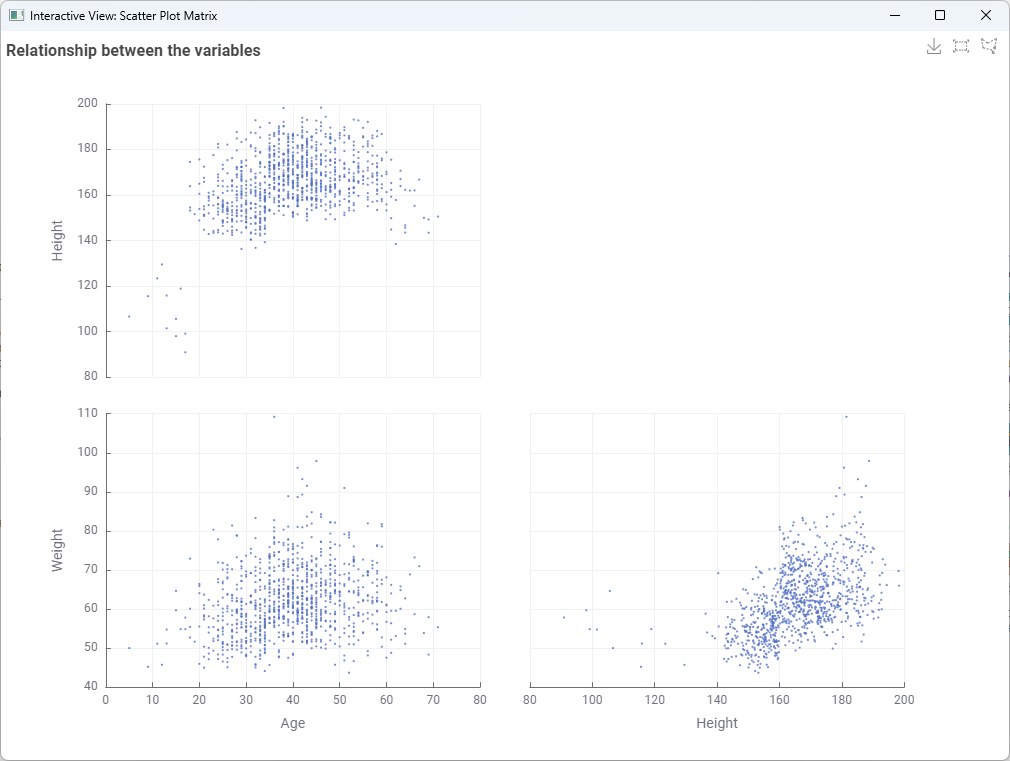
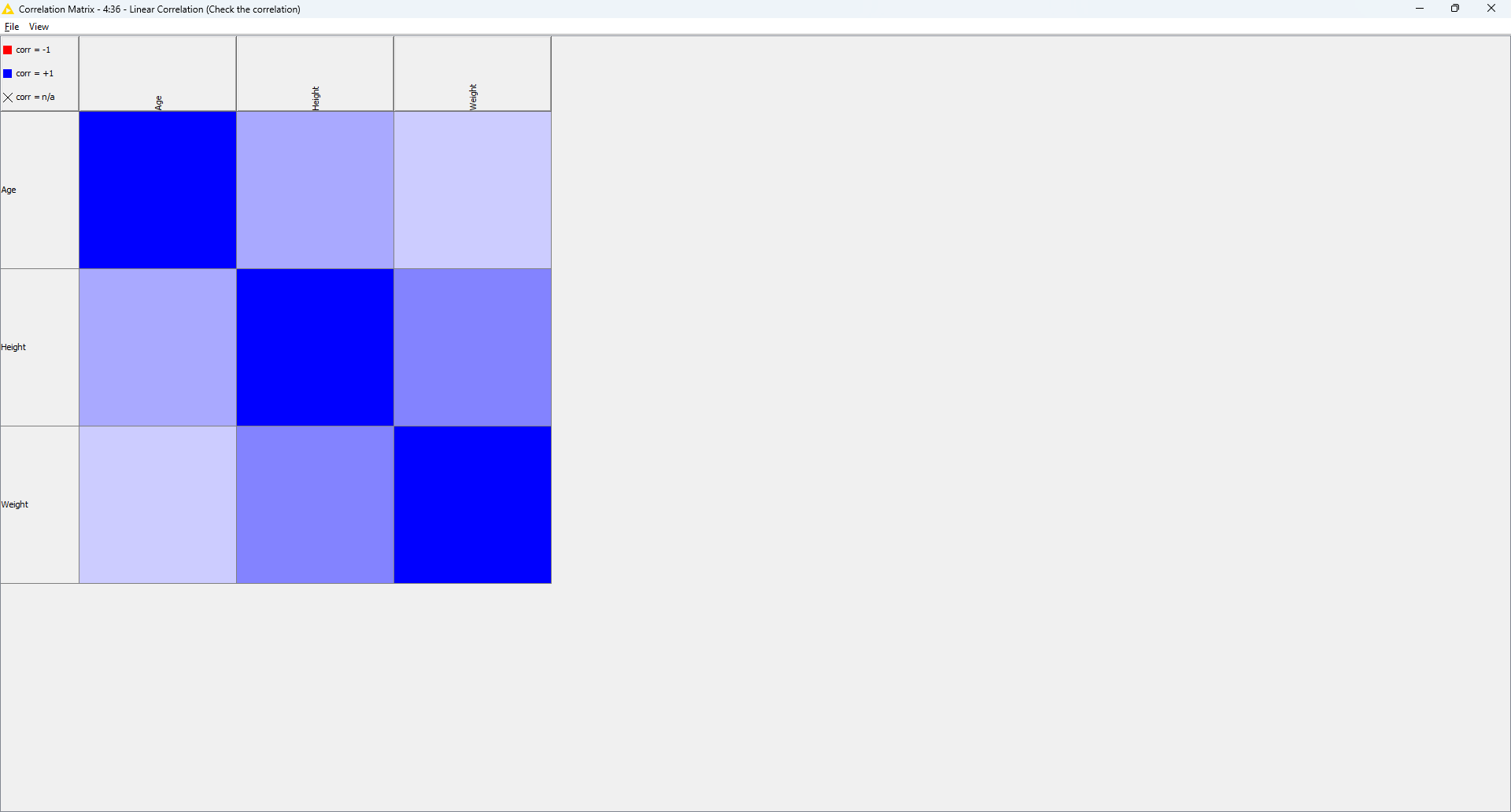
It’s very interesting to notice how different parameter values change the generated data, and even their correlations, substantially. Since in this challenge’s story this data will be used as control (baseline) for scientific experiments, this gives the scientists great control.
Thanks for your very nice contributions, even including other attributes!!, and see you all tomorrow for a new challenge on cohort analysis!
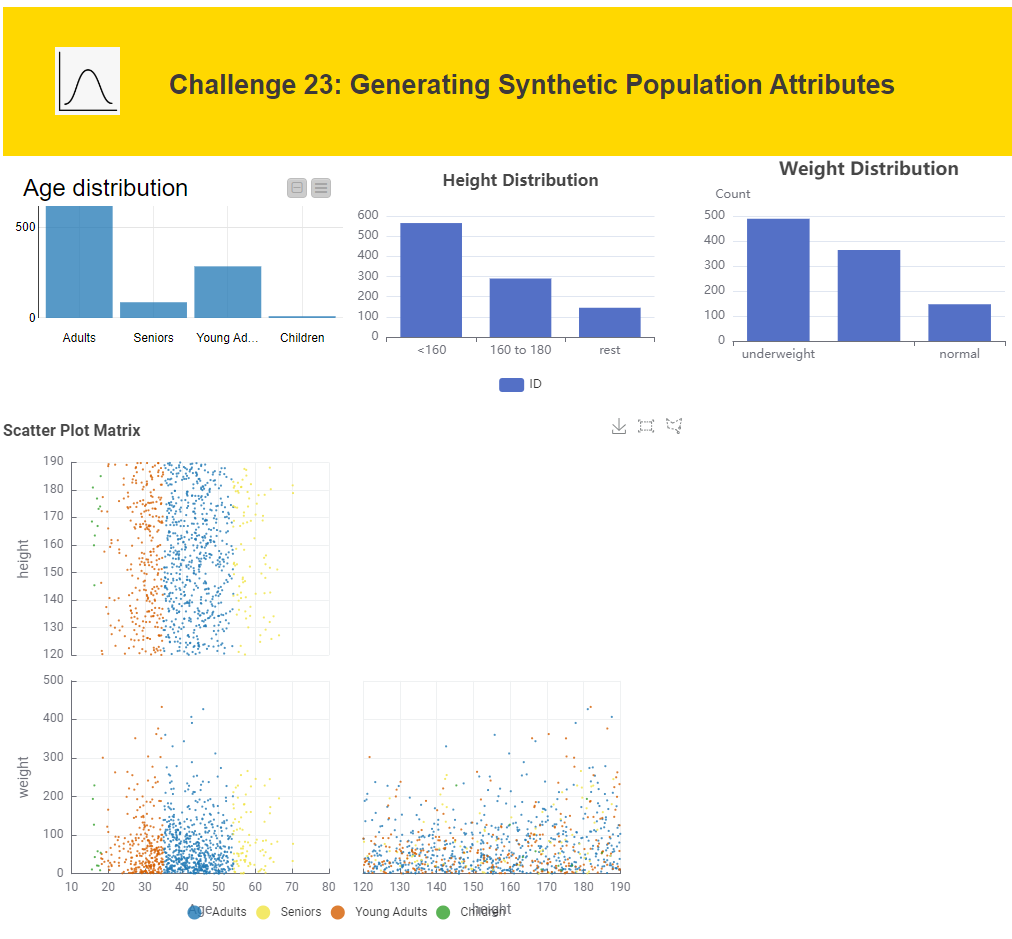
Hi All,
I am absolutely throwing in the towel on this one. I could not get the distribution nodes to generate distributions that made any sense to me… here is what my data app looked like maybe some one will spot my errors: