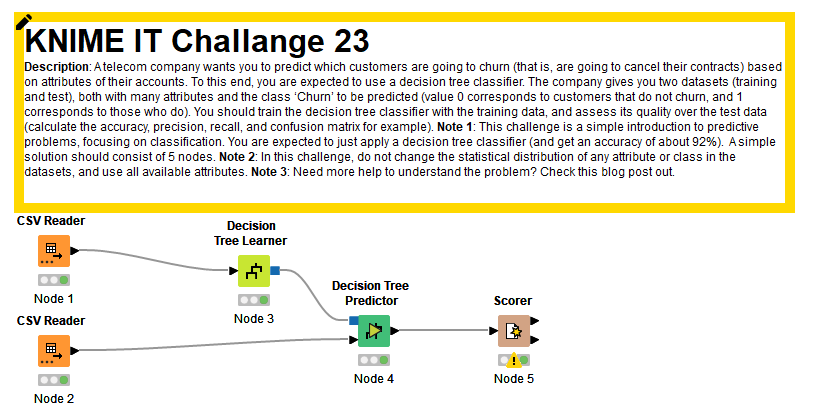
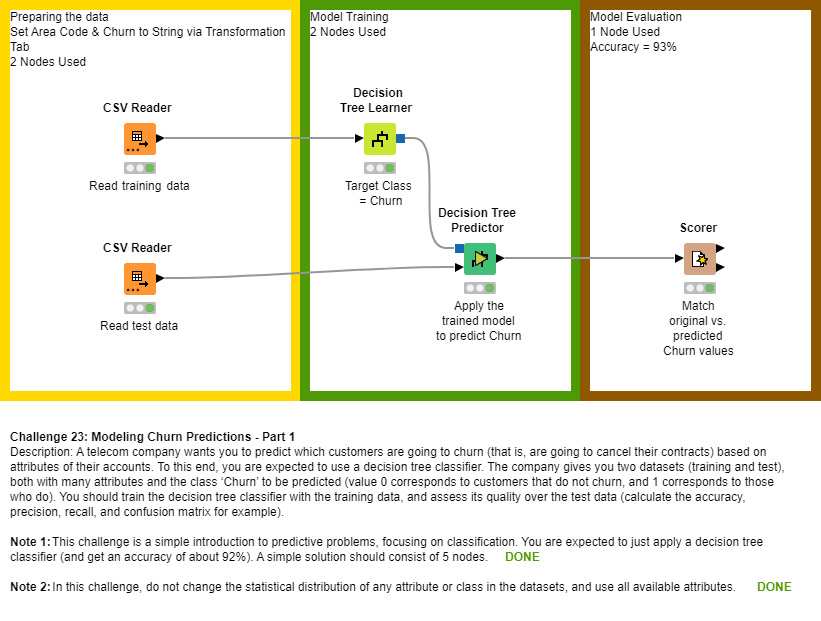
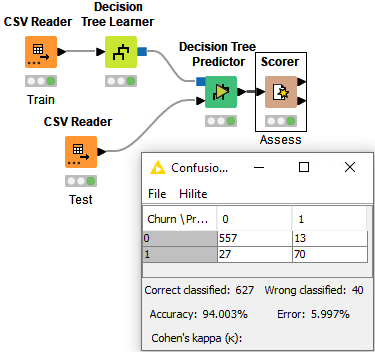
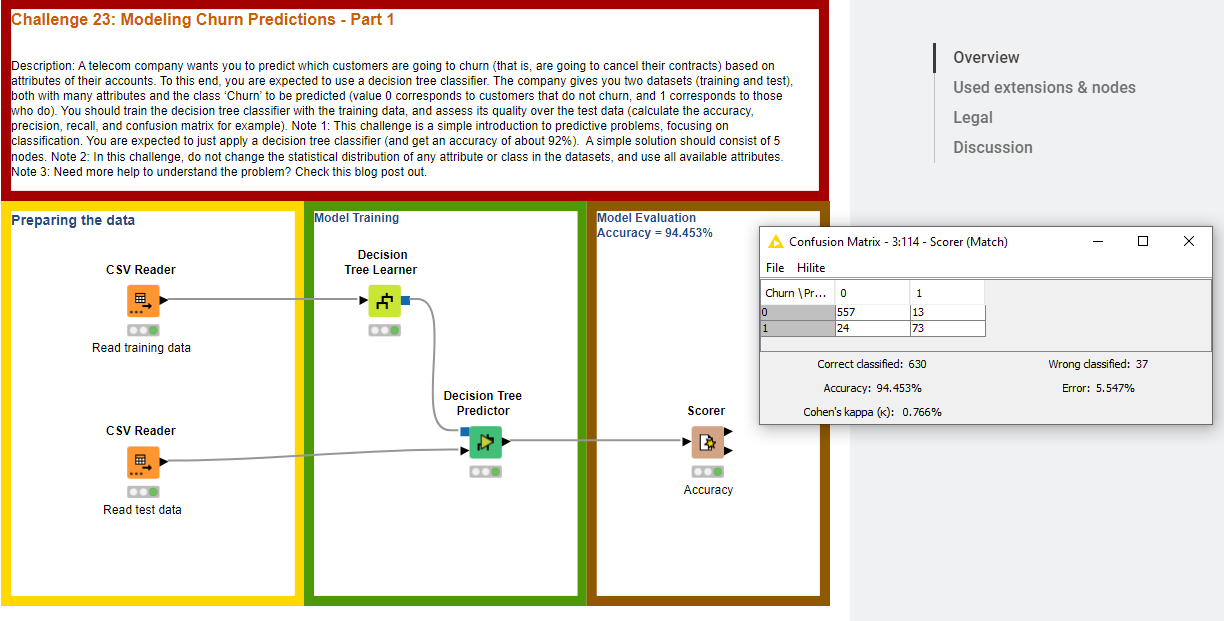
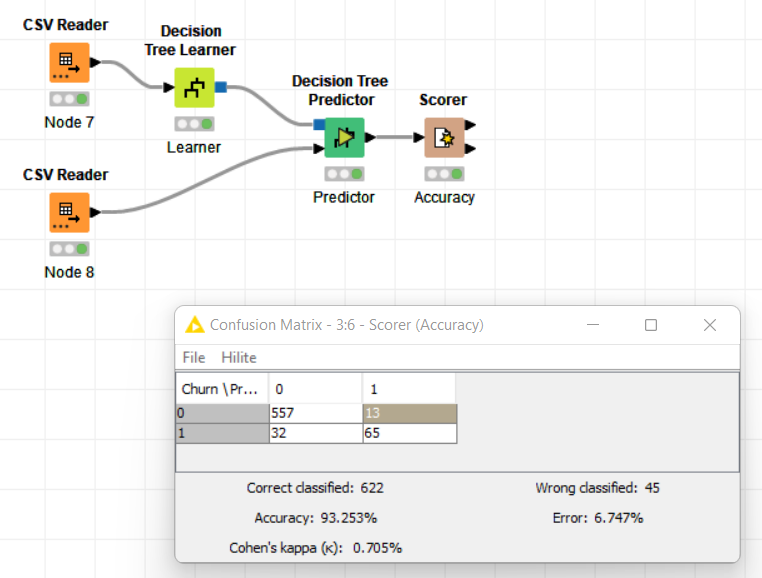
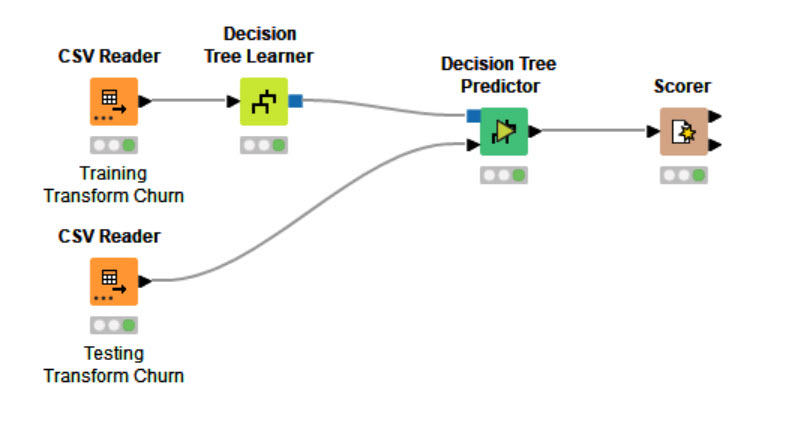
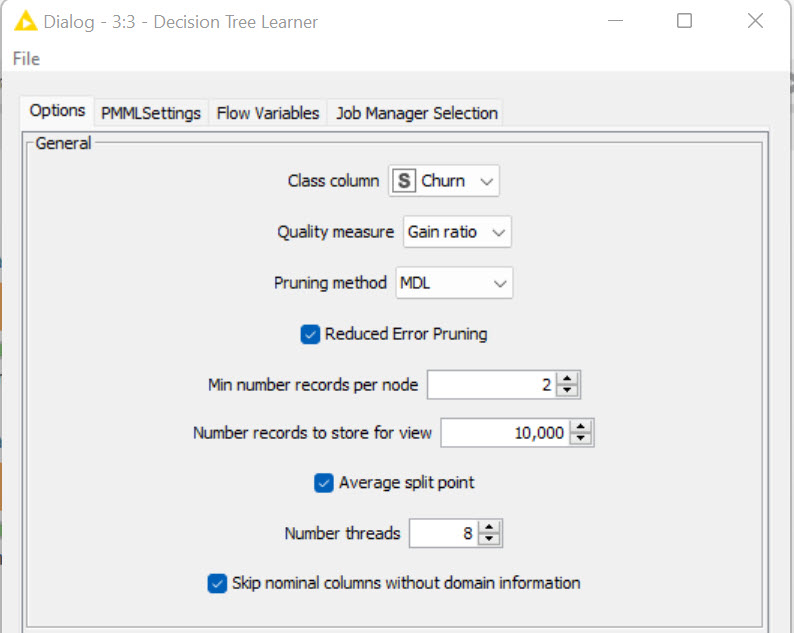
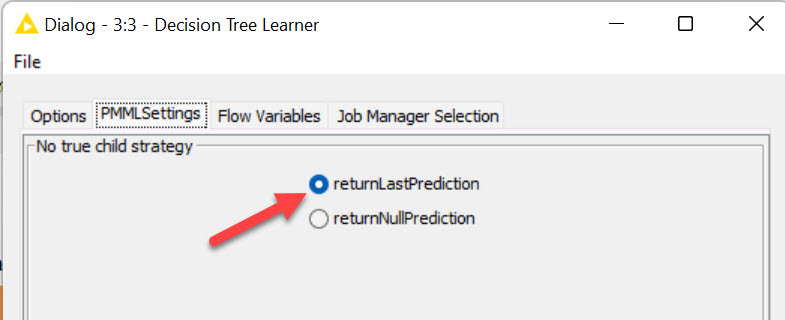
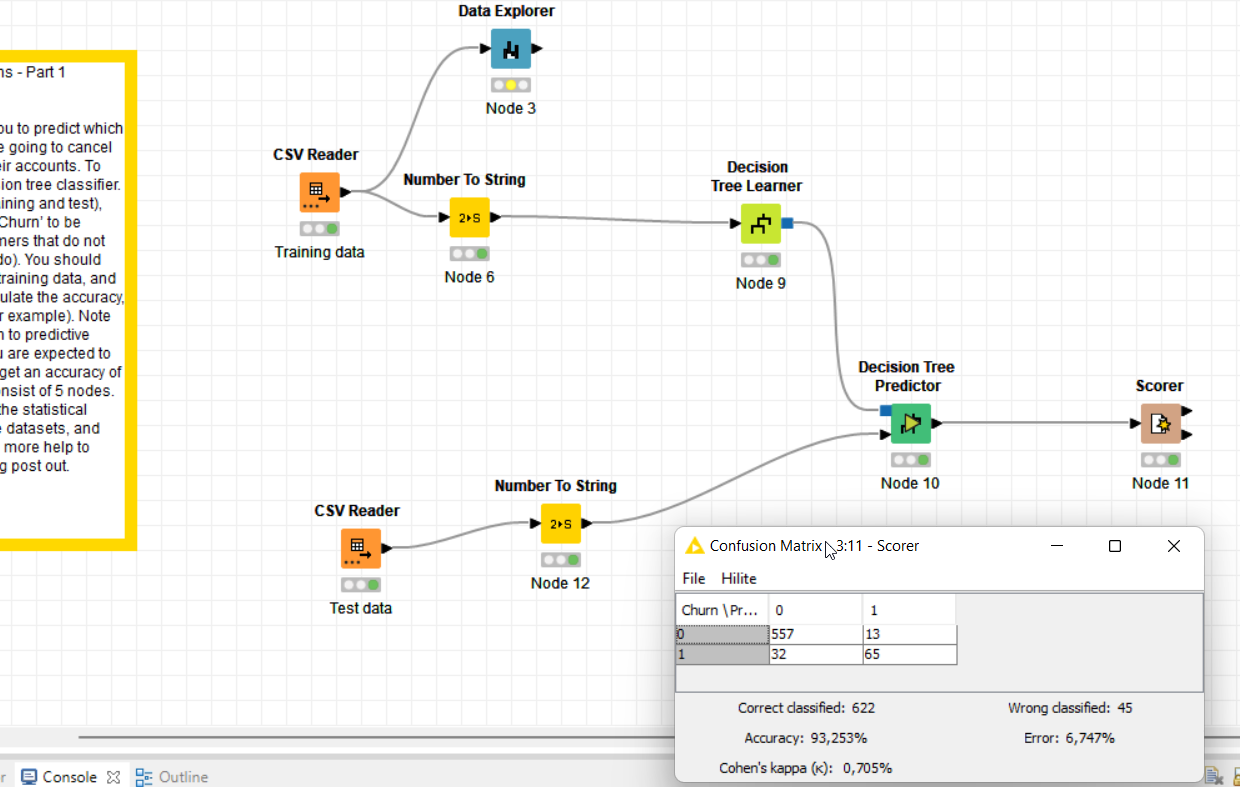
Hi! I did basically the same but tried to use rule engine just to make it easier to understand which row was representing a churn or not.
Also added the “Model Writer” node to make it easier for deployment.
This is my submission for the Churn prediction challenge.
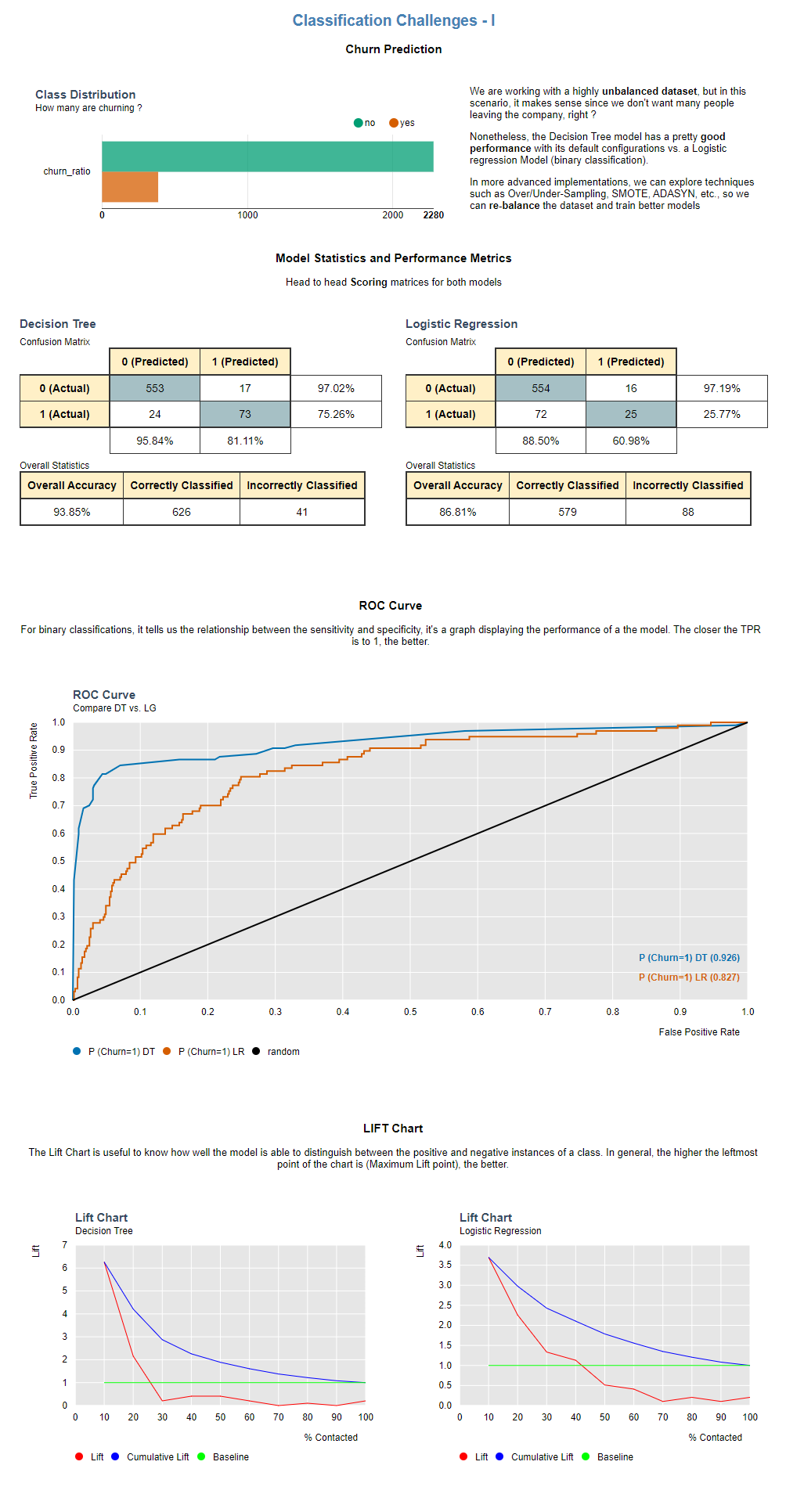
I added an ROC curve, as done by @MarioNasser before. I wrote my cross validated model to a file and used it on the test data to compare the non cross validated ROC vs the cross validated one. I got a marginally better result.
Notes:
The simple Regression Tree did not work and I don’t understand why.
I would have liked to see the scorer results from multiple scorers together but I don’t know how.
here’s my solution.
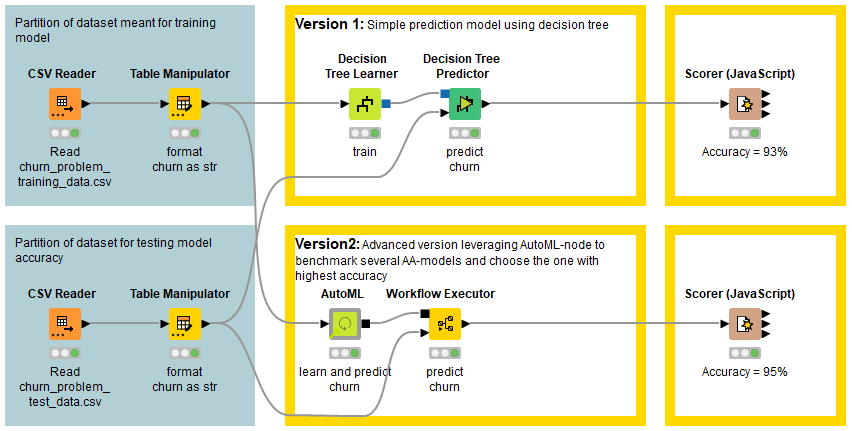
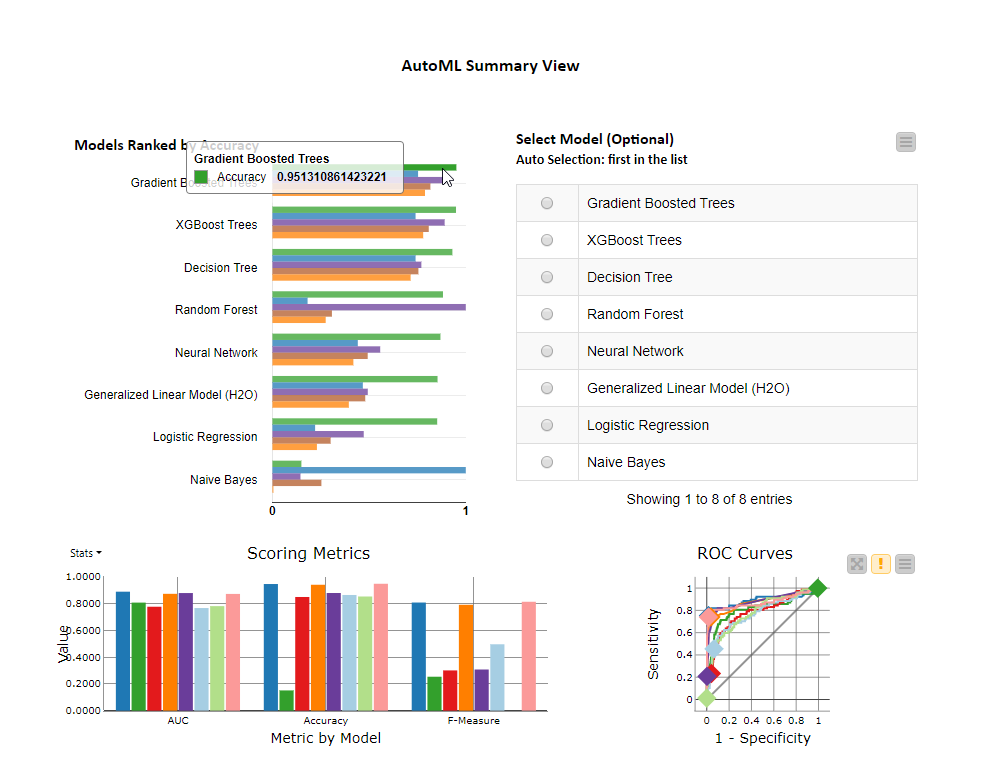
I did two versions of the challenge, 1) simple prediction model according to the challenge and 2) an advanced using AutoML-node to benchmark several models and choosing the one with highest accuracy. VERY COOL.
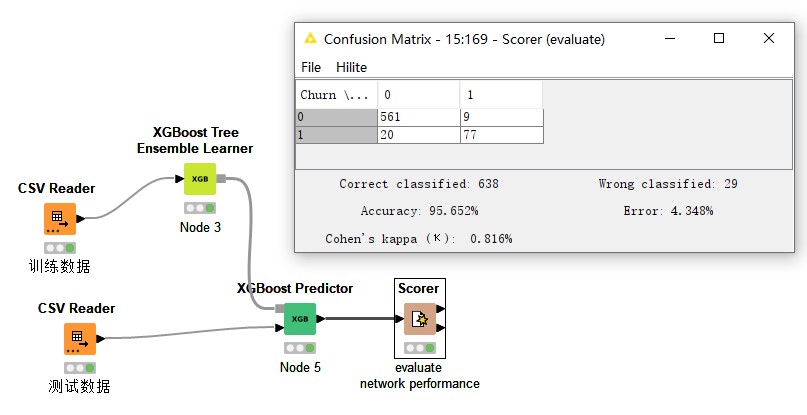
Since this topic is about classification with a strong hint about the use of tree methods, I decided to compare three tree-based approaches (I didn’t use XGBoost since some users already tested it):
Decision Tree,
Gradient Boosted Tree
Random Forest .
I tried to put the emphasis on model understanding/explainability, that’s why I added a decision tree view for the Decision Tree and the component “Global Feature Importance” for the Random Forest. I haven’t seen any view for Gradient Boosted Tree, so I’m open for any suggestions
The goal for the team might be to have good churn prediction performance, but also an understanding or insights about the model. For example in the random forest, “State” is the first important feature. That may lead the team to better know their customers and learn how to adapt their strategy in different states…