hi
here’s my solution.
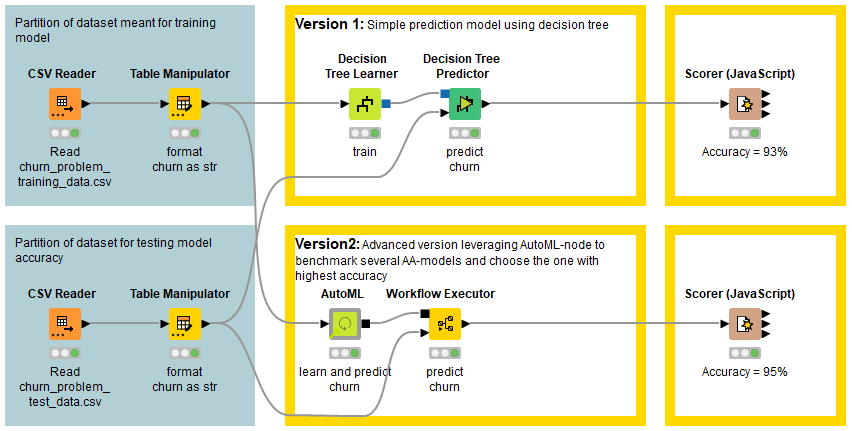
I did two versions of the challenge, 1) simple prediction model according to the challenge and 2) an advanced using AutoML-node to benchmark several models and choosing the one with highest accuracy. VERY COOL.
summary:
Decision tree: 93% accuracy
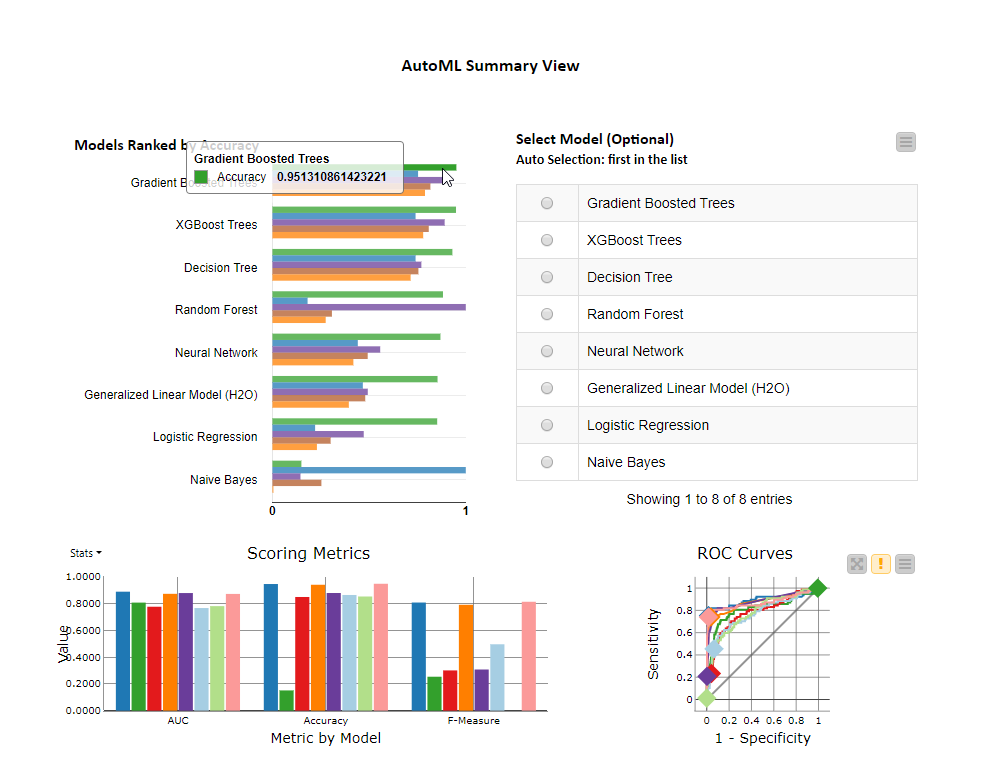
AutoML (Gradient Boosted Trees): 95%
/cheers