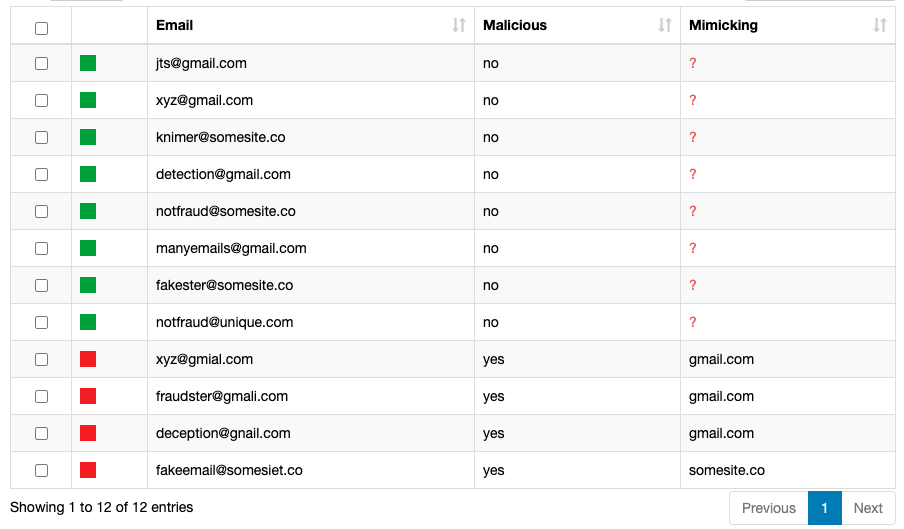
An important task in cybersecurity analytics has to do with detecting (likely) fraudulent email domains. This week you should dive into this problem exploring string similarity or pattern matching techniques. We can’t wait to see what you’ll come up with!
Here is the challenge. Let’s use this thread to post our solutions to it, which should be uploaded to your public KNIME Hub spaces with tag JKISeason2-24.
Need help with tags? To add tag JKISeason2-24 to your workflow, go to the description panel in KNIME Analytics Platform, click the pencil to edit it, and you will see the option for adding tags right there. Let us know if you have any problems!
The instructions weren’t 100% clear to me. I wasn’t certain whether to tag only domains that mimic gmail or all domains which seem suspicious, e.g. domains ending in “co”. Consequently, i have two workflows. The first only tags domains which mimic gmail while rev 1 tags all suspicious domains. I used a combination of similarity scores and % of each domain to the mean total domain % to establish the fraud rules.
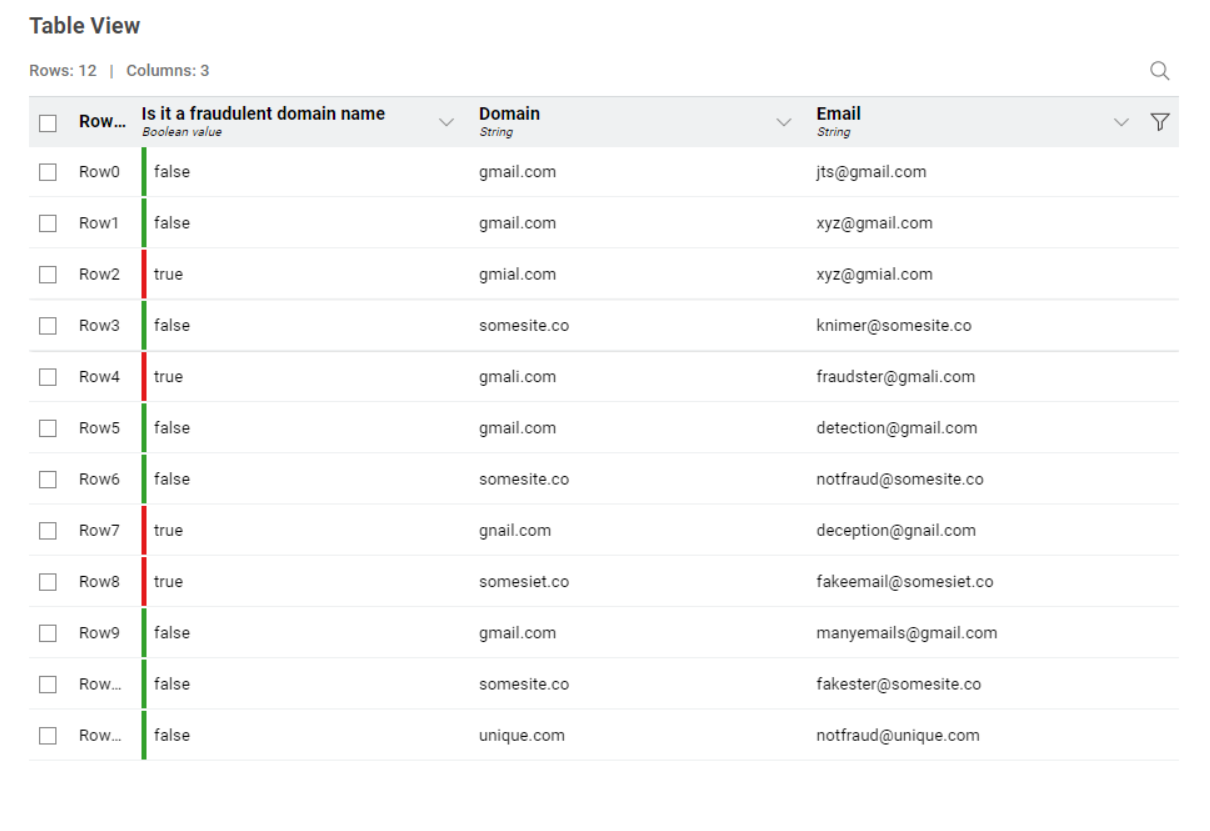
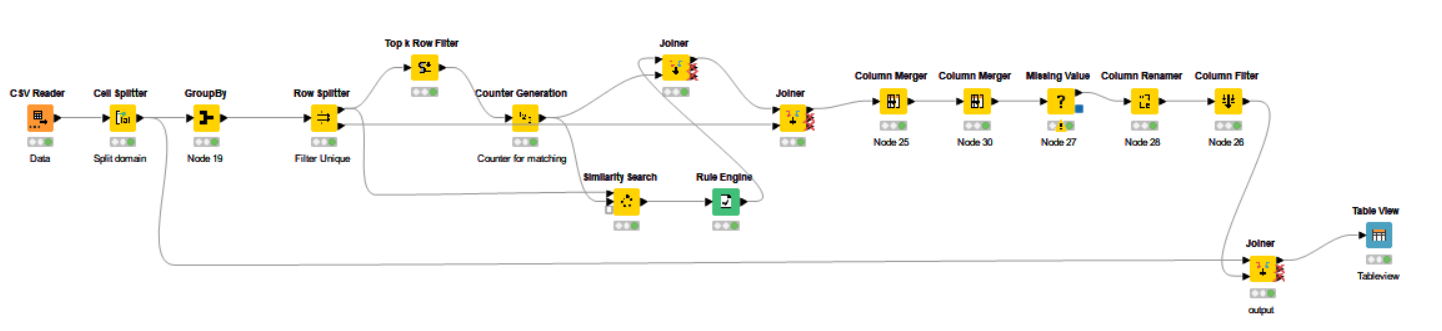
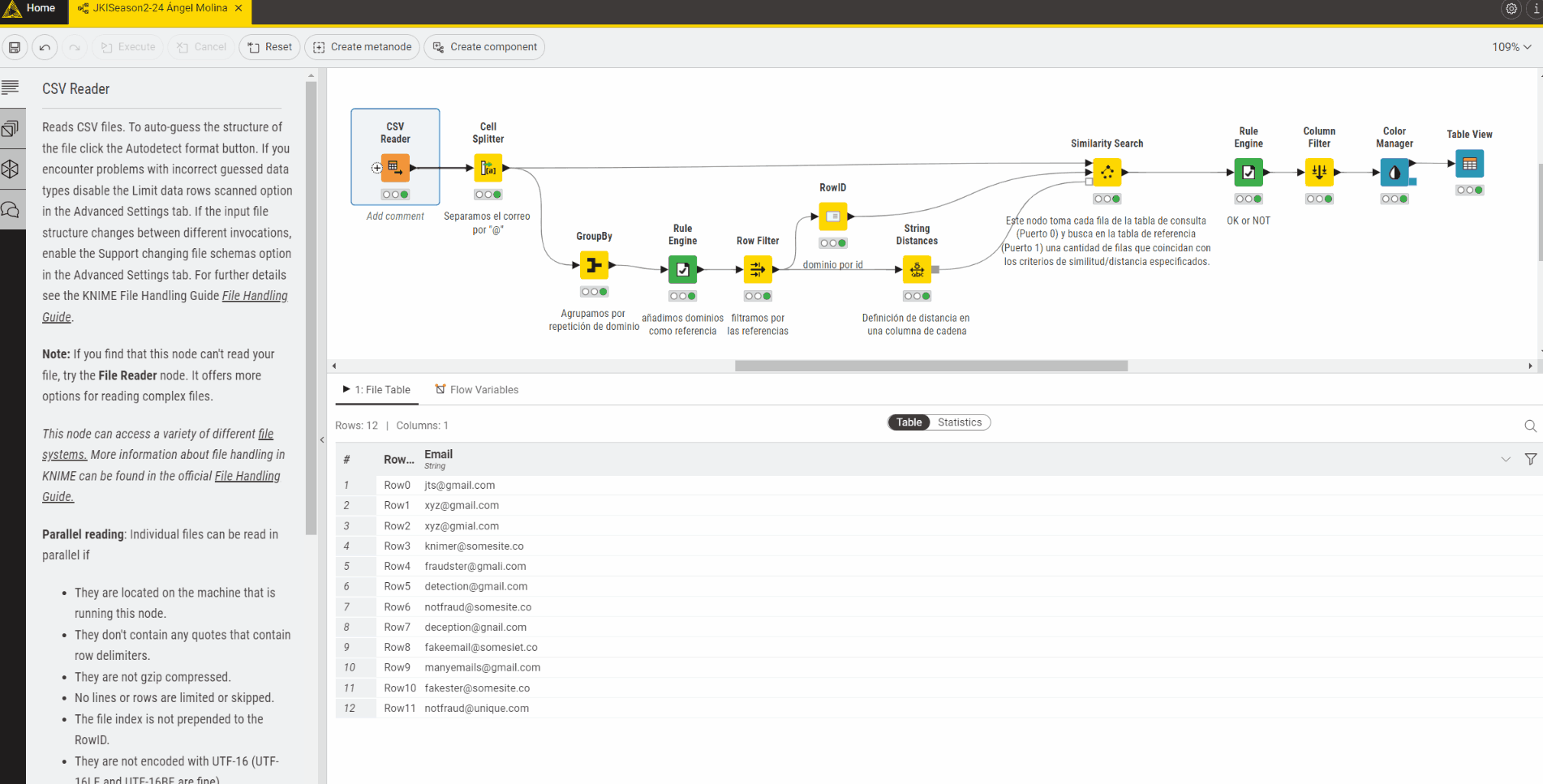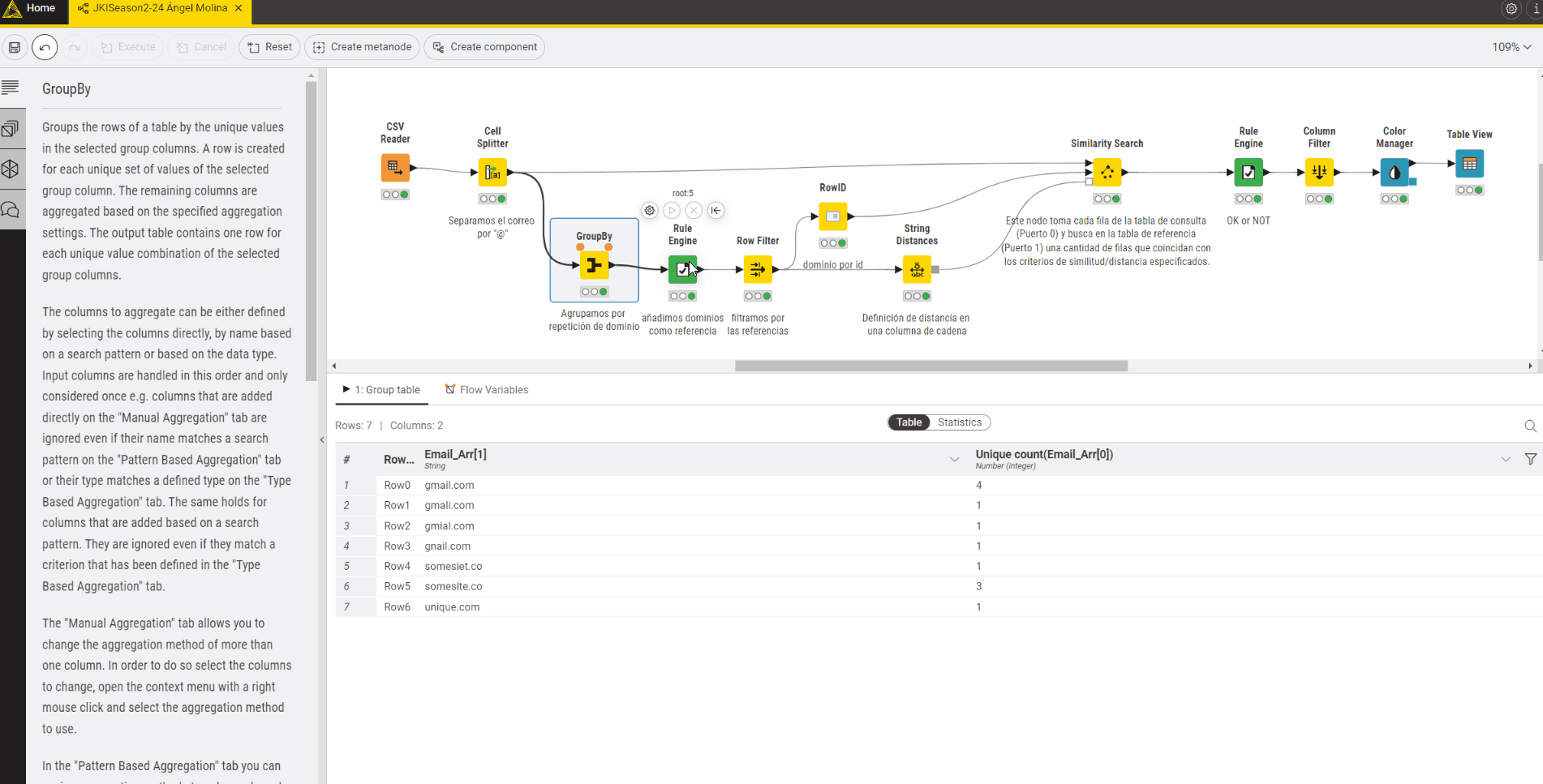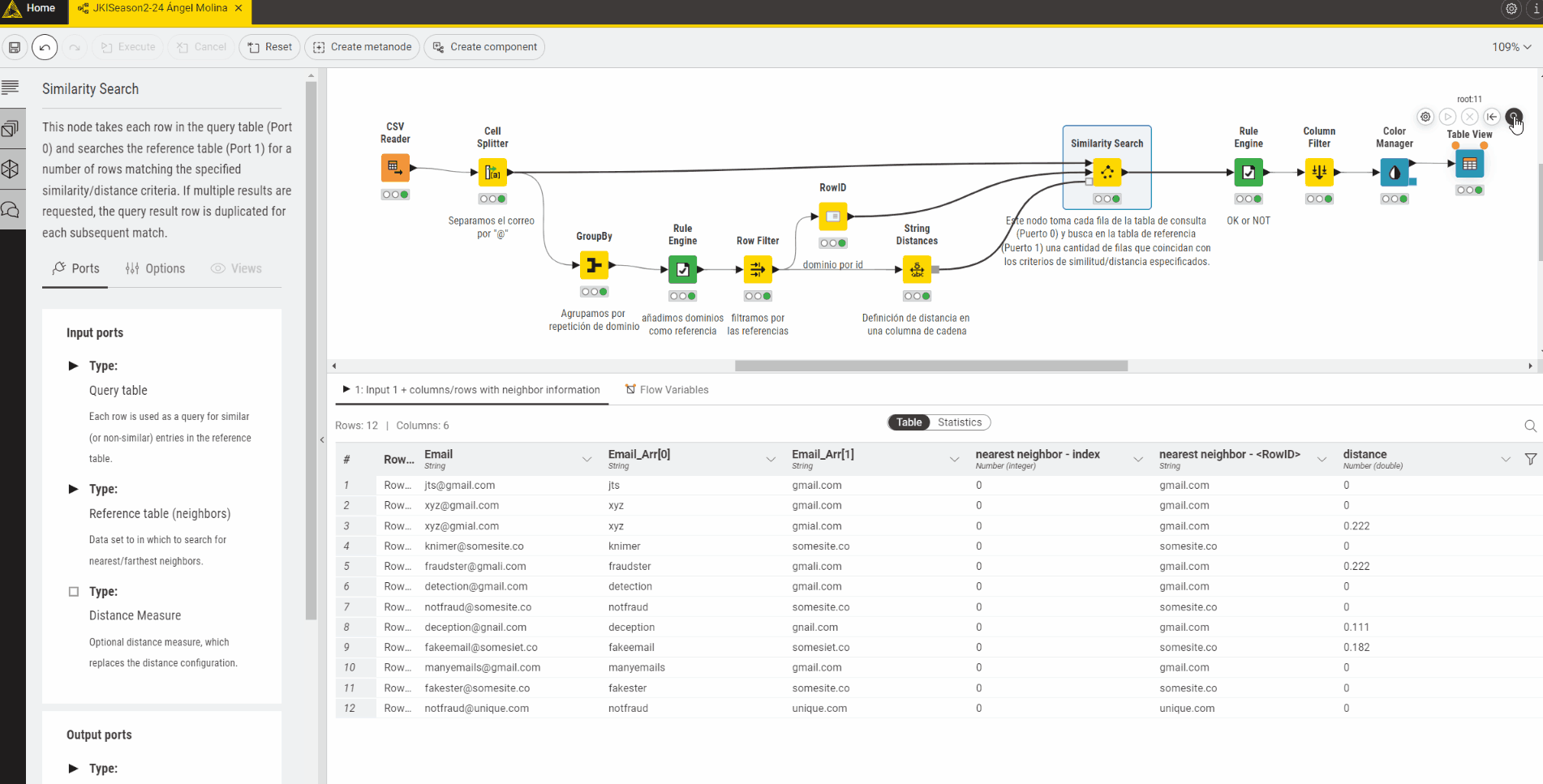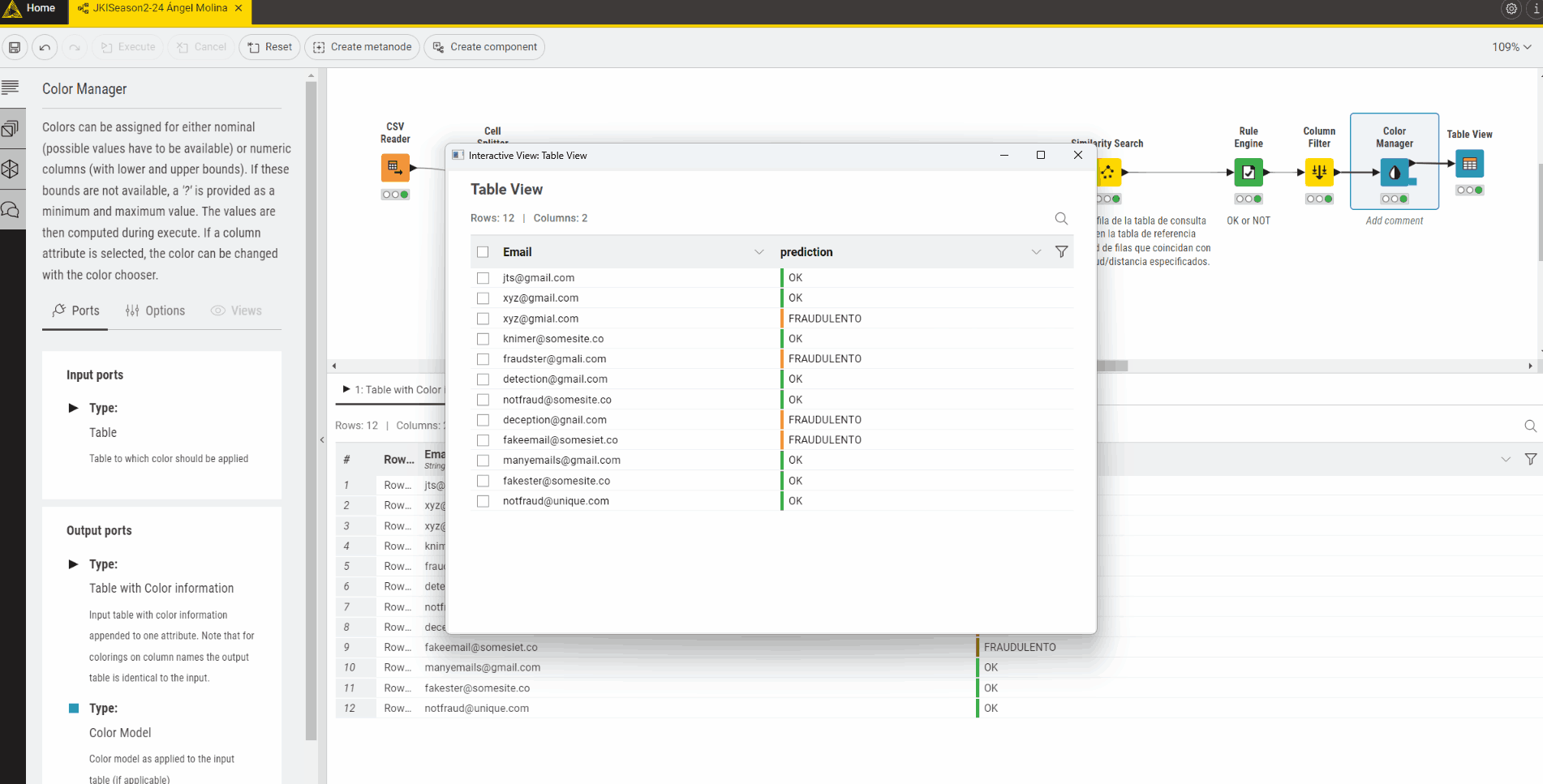
For this challenge I have separated the email domain from the rest of the email address and used the -GroupBy- node to count the number of times each domain is present in the table. I have then used the -Cross Joiner- node in order to join every email with every other email.
Using the -String Similarity- node, I have calculated the Levenshtein similarity between every domain and every other domain and have removed rows with similarity equal to 1.
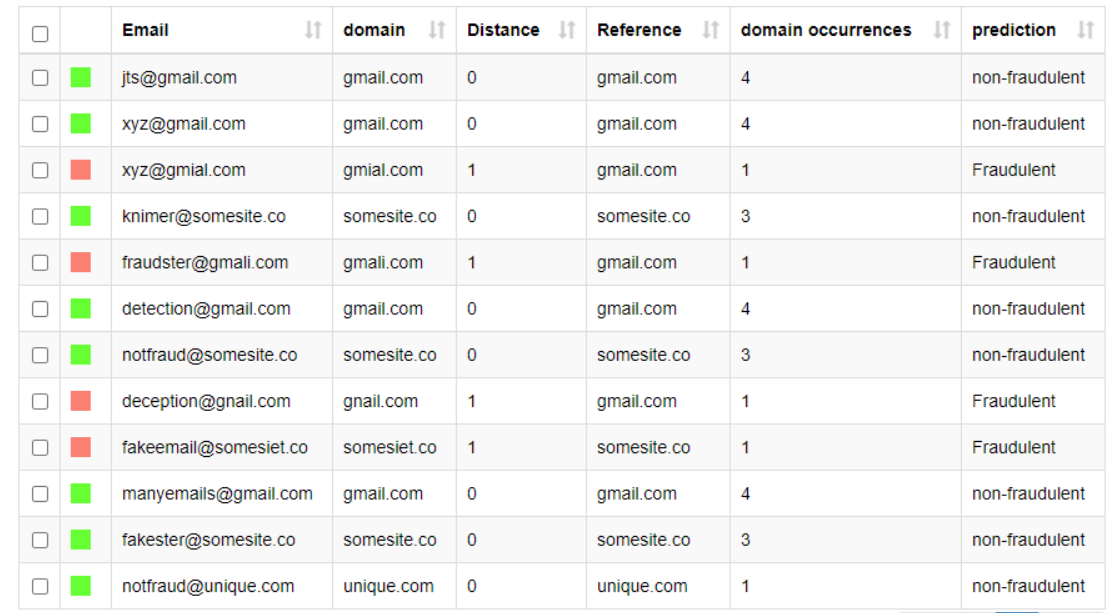
I have then used the -Rule Engine- node to tag the email address as FRAUDULENT or NOT FRAUDULENT based on the following rule:
If the similarity is > 0.7 AND the domain count of the email < the domain count of the comparison email then the email is FRAUDULENT. If not, the email is tagged as NOT FRAUDULENT
@rfeigel Thanks for your feedback on the challenge’s text. The idea was to tag all domains that seem suspicious, and their rarity in the dataset is a good indicator.
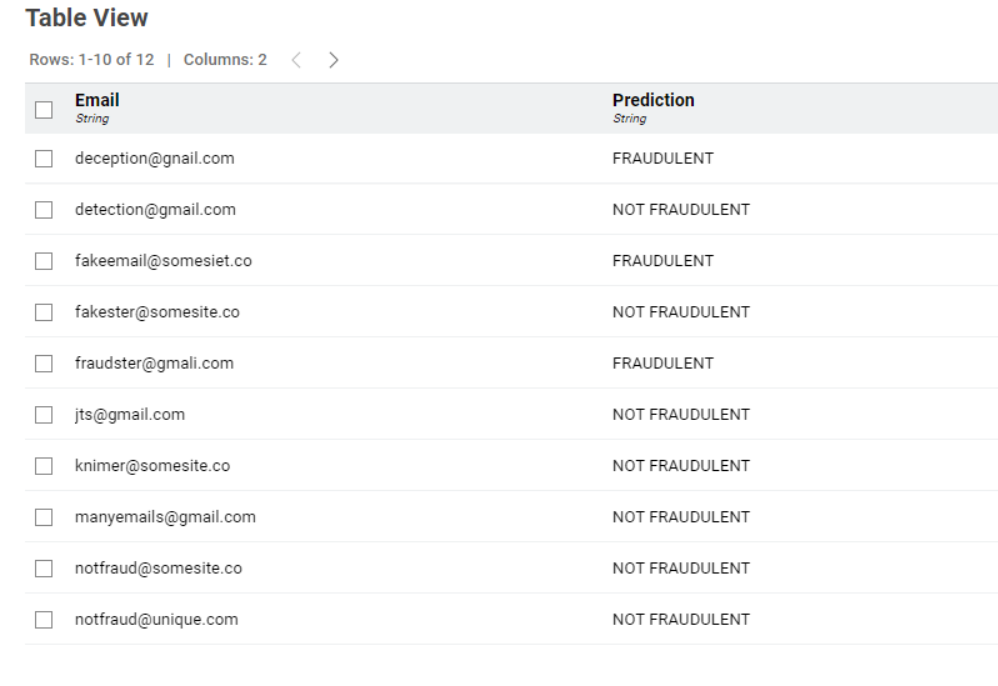
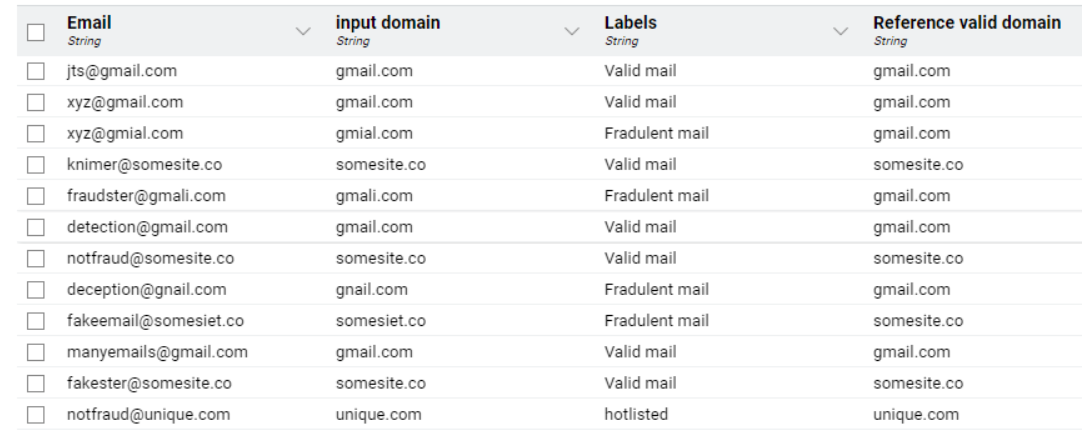
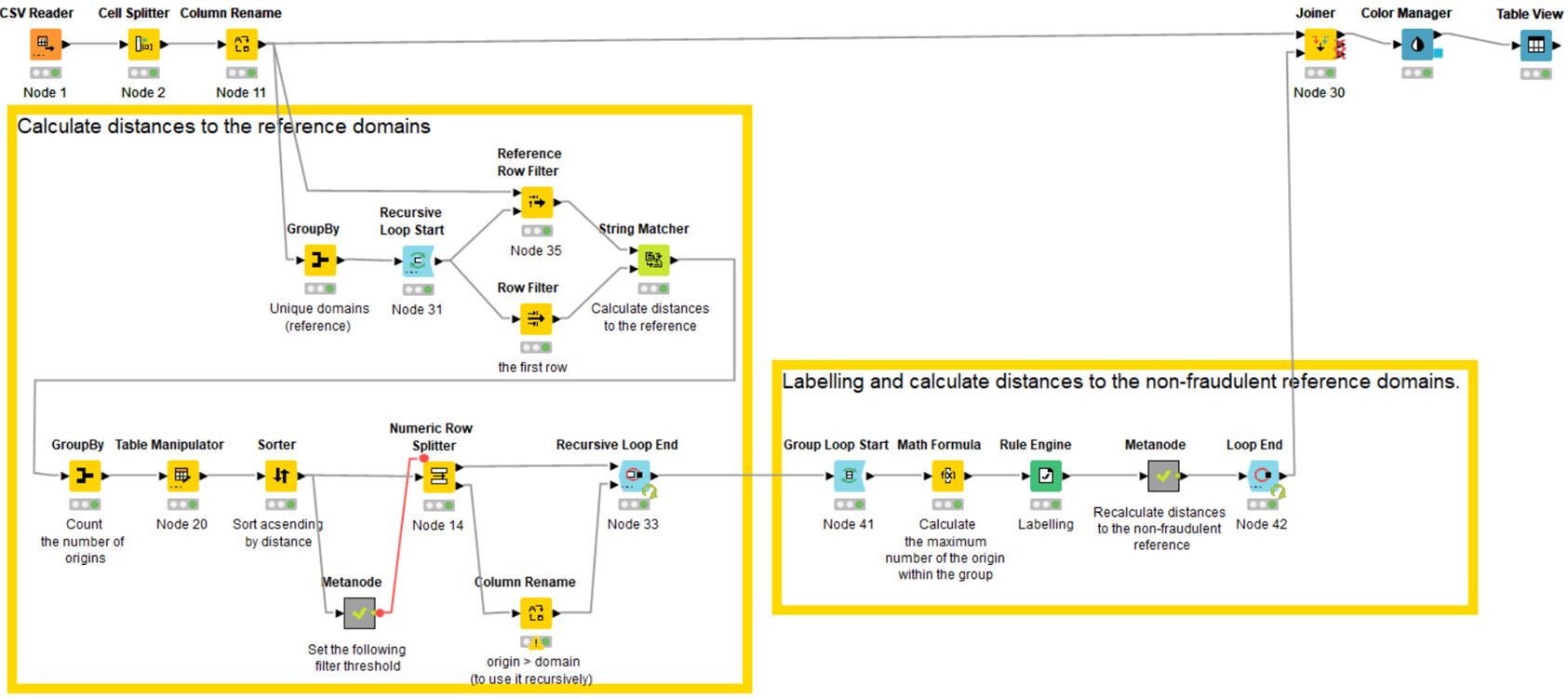
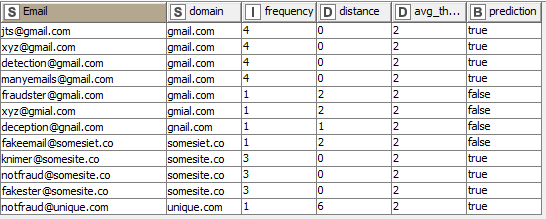
Here is my solution. As other participants I decided to use the low frequency as an indicator of fraudulent domain, and as it was required I marked “unique[.]com” as a non-fraudulent domain. I also believe that one can avoid doing joins and cross-joins since they might be extremely expensive for big data sets. So it possible to use the list of non-fraudulent domains straight away to apply string similarity.
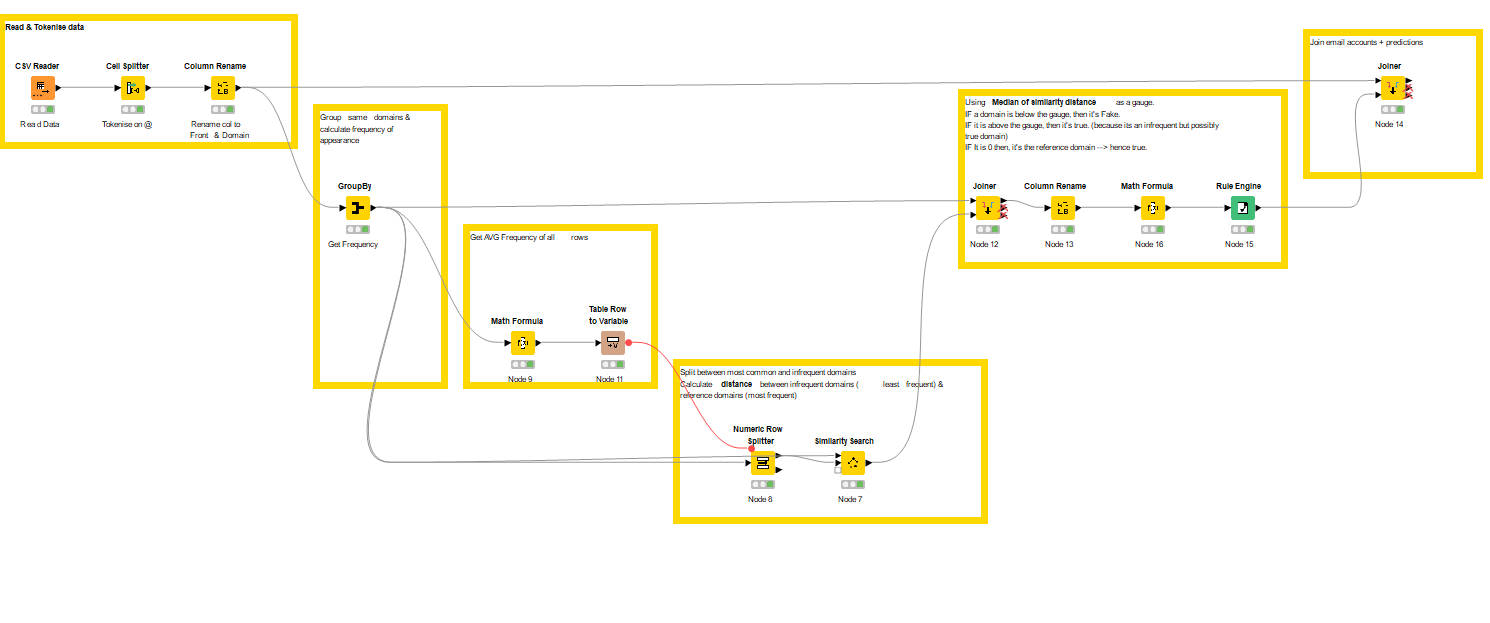
As always on Tuesdays, here’s our solution to last week’s Just KNIME It! challenge
Aside from the idea of using similarity search, which is a bit advanced, this solution is relatively simple! We use basic statistics (average and median) to first separate popular domains from rare ones, and then to determine whether a rare domain is “too similar” to a popular one (red flag! ) or not.
We really enjoyed your solutions and explanations to the findings. Good detective job!
Hi folks,
This is an interesting problem to solve – using similarity distances & averages to figure out if an email is fake or otherwise. It’s a very cool way to solve this question!