This week we will once again dive into the digital healthcare realm to discuss an important topic in machine learning: hyperparameter optimization! How well can an XGBoost classifier perform in the detection of heart disease? It’s all in the parameter values!
Here is the challenge. Let’s use this thread to post our solutions to it, which should be uploaded to your public KNIME Hub spaces with tag JKISeason2-25.
Need help with tags? To add tag JKISeason2-25 to your workflow, go to the description panel in KNIME Analytics Platform, click the pencil to edit it, and you will see the option for adding tags right there. Let us know if you have any problems!
Uses a parameter optimisation loop on eta (i.e. learning rate), boosting rounds, max depth tree.
Search Strategy = Random Search. No early stopping becuase I wanted to see it’s better than early stopping.
F1 score (i.e. F-measure) was created as an average of F1 scores for class 0 & 1. i.e. Macro F-measure (source)
Explanation:
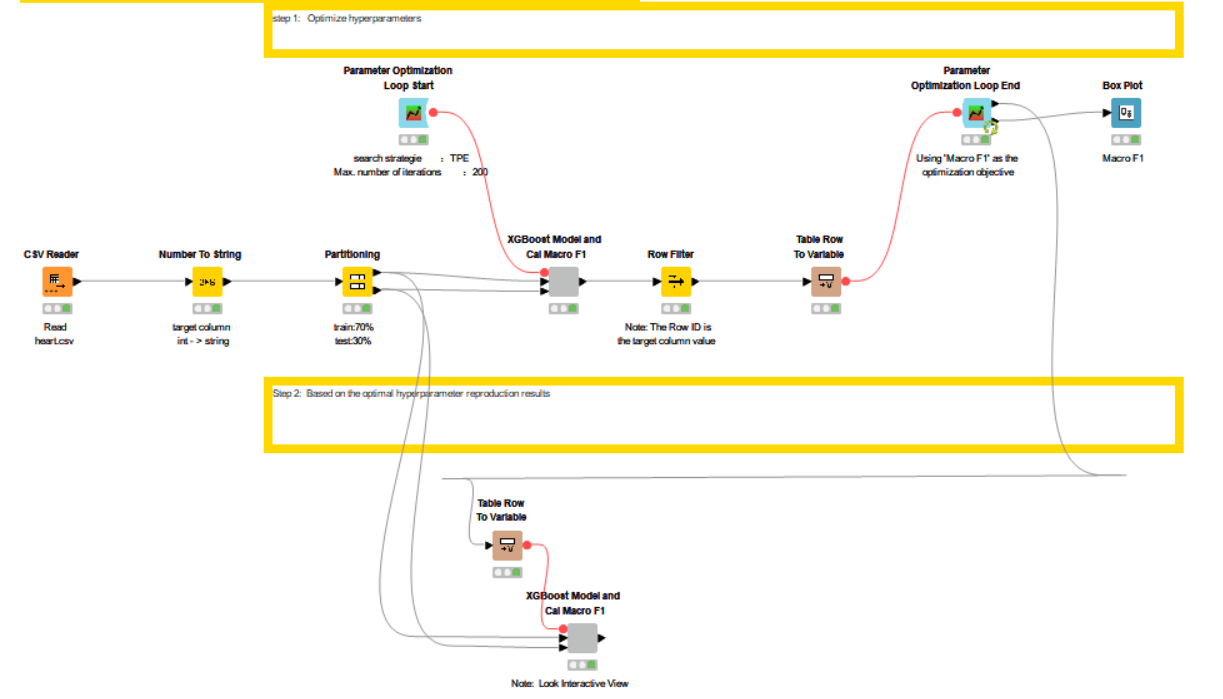
1.The overall structure is divided into two steps. The first step is hyperparameter search, and the second step is to apply the optimized parameters to the model.The model and score are packaged as a component, as this similar calculation was used in both the first and second steps.
2.The hyperparameter search strategy uses the TPE method, mainly to control the number of iterations. Additionally, it seems that this is currently a popular strategy.
3.The Object of hyperparameter optimization is also chosen for Macro F1.
Hello everyone,
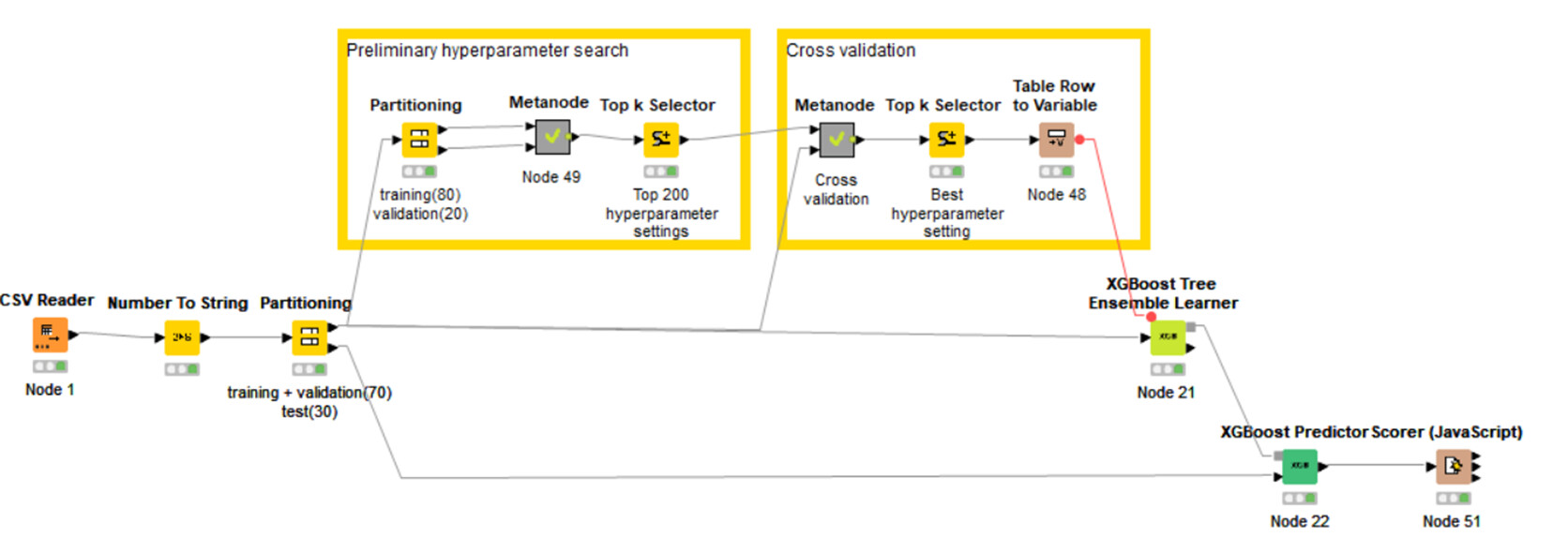
Here’s my solution. I wasn’t familiar with the typical range of hyperparameters, so I conducted a preliminary hyperperameter search over a wide range before cross validation. However this approach comes with a high computational cost. Thanks.
Here is my solution. Here I also used F1 macro score (thank you @tomljh for this hint). However I could find this score is not scattered that much, so it is easy to find a good combination of parameters without testing out big ranges of them.
So many different approaches to the problem this week! Very interesting… As you can see, our solution heavily relies on the Parameter Optimization (Table) component. Have you heard of it before?
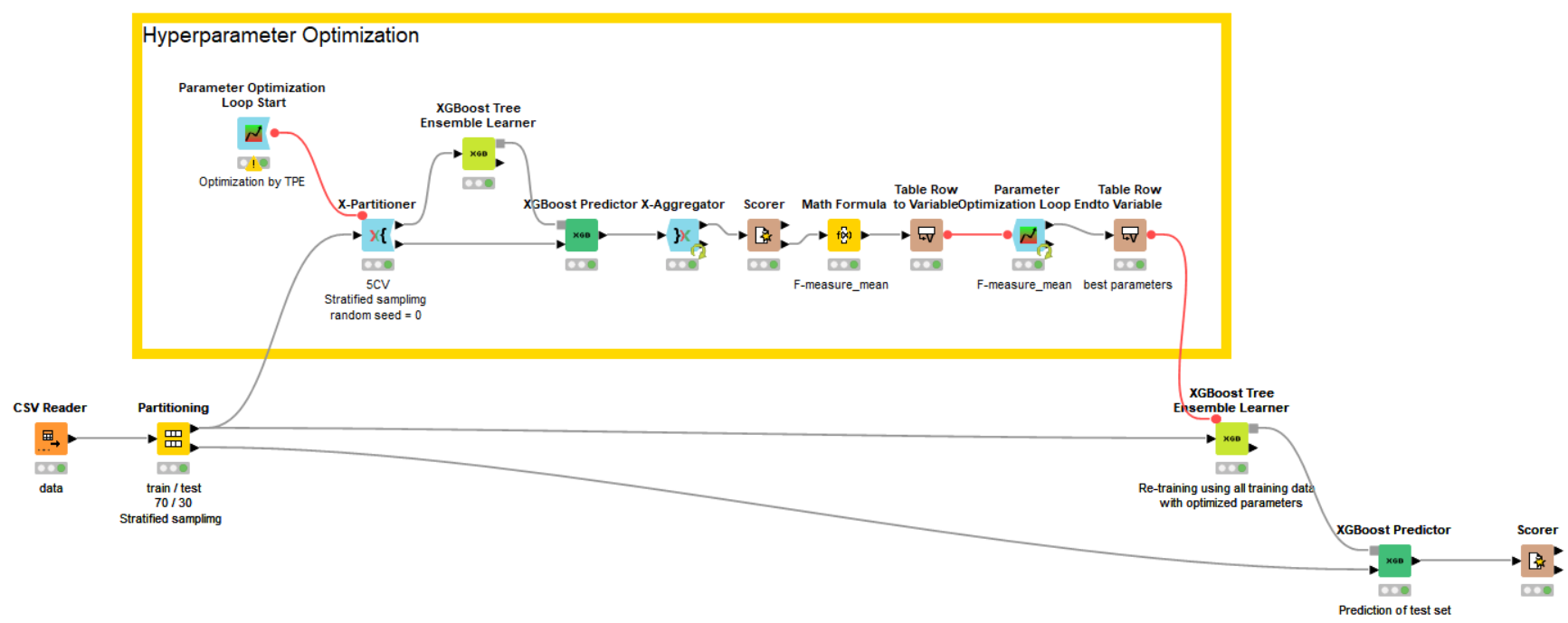
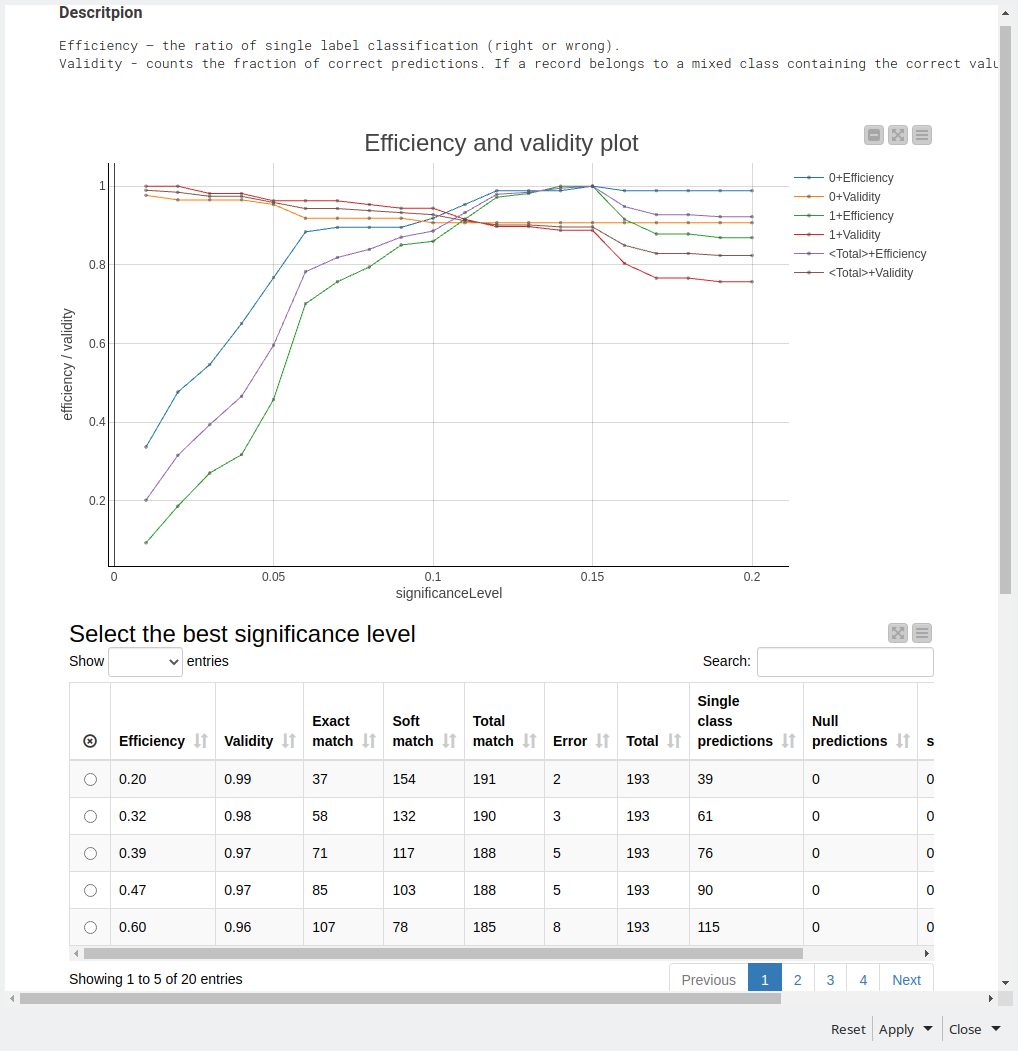
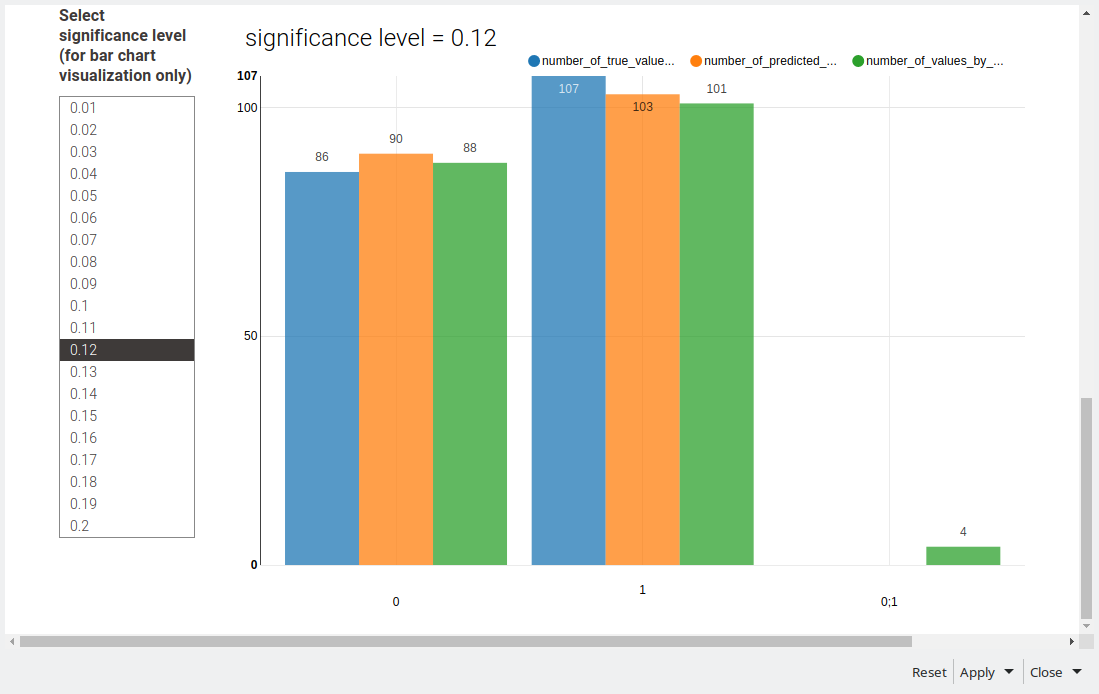
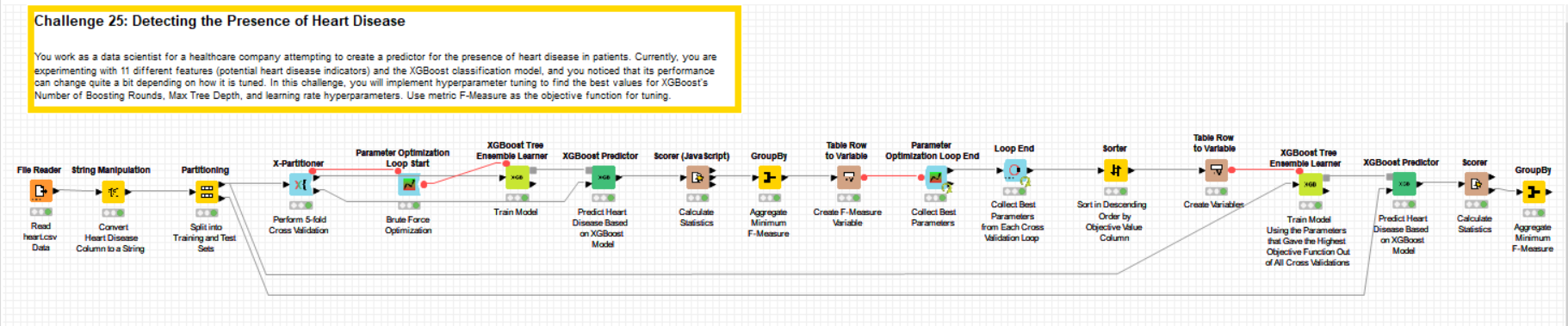
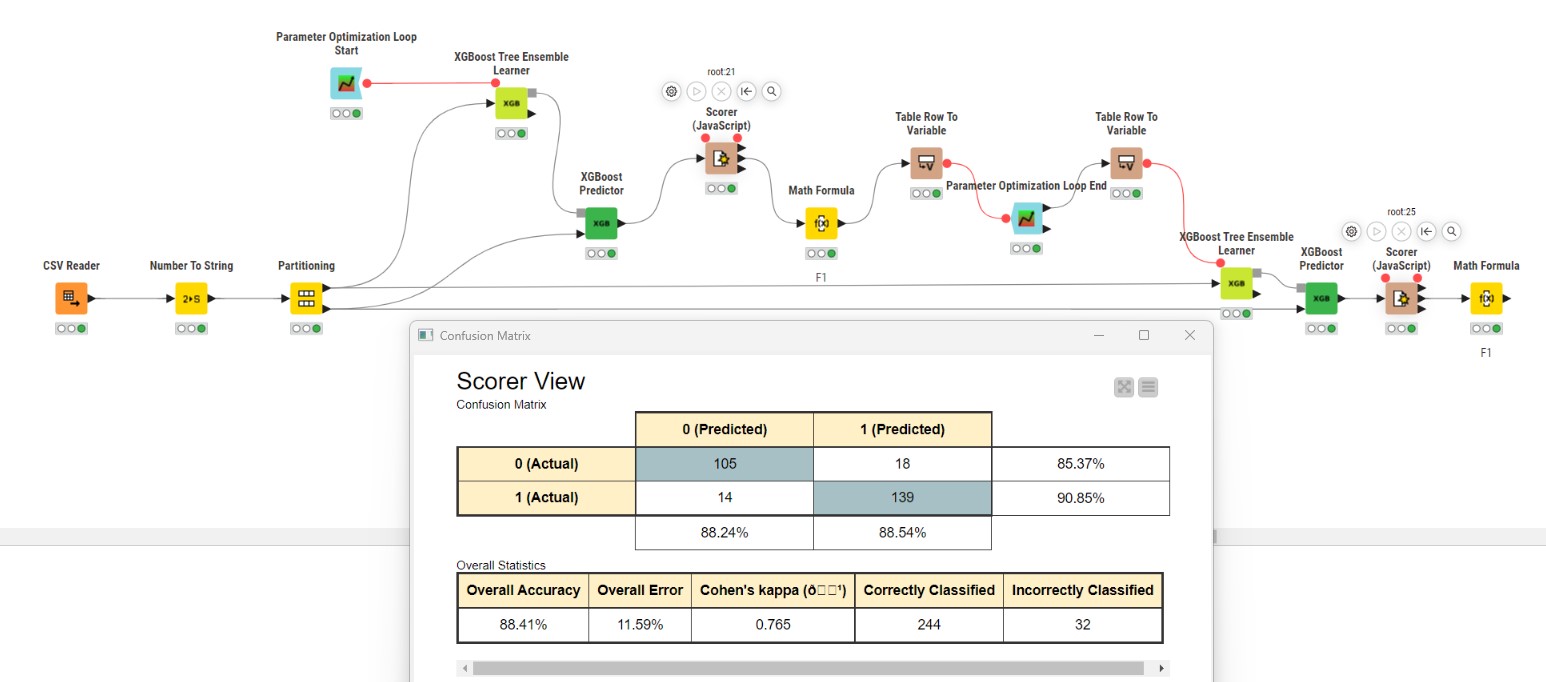
This week I have split the data into training (70%) and test (30%) sets and used the training set to perform a 5-fold cross validation using the -X-Partitioner- node. The -Parameter Optimization Loop- nodes have been used inside the cross validation loop to determine the optimal parameters (Number of Boosting Rounds, Max Tree Depth, and Learning Rate) for the -XGBoost Tree Ensemble Learner- node, with the Objective Function set as the F-Measure.
After obtaining the optimal parameters for each of the cross validations, the best set of parameters was selected to train a final XGBoost model on the full training set and the model was used to predict the test set.
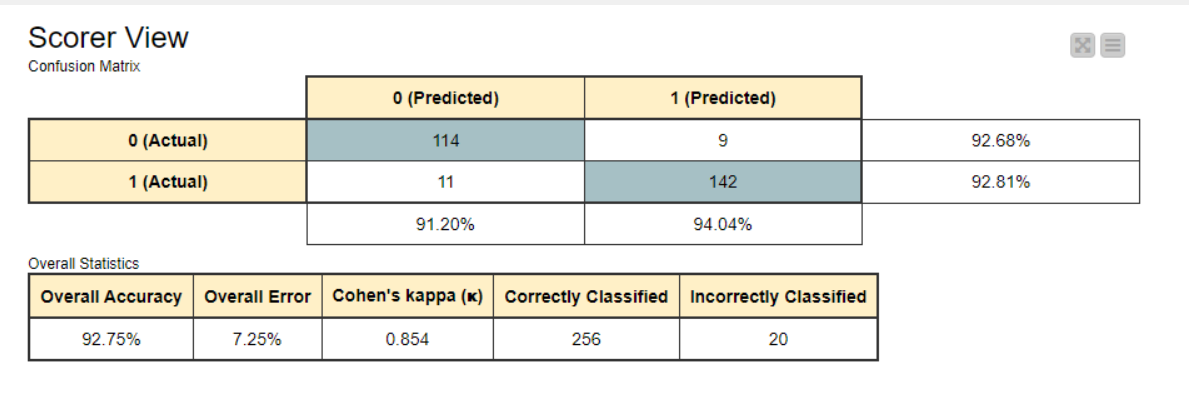
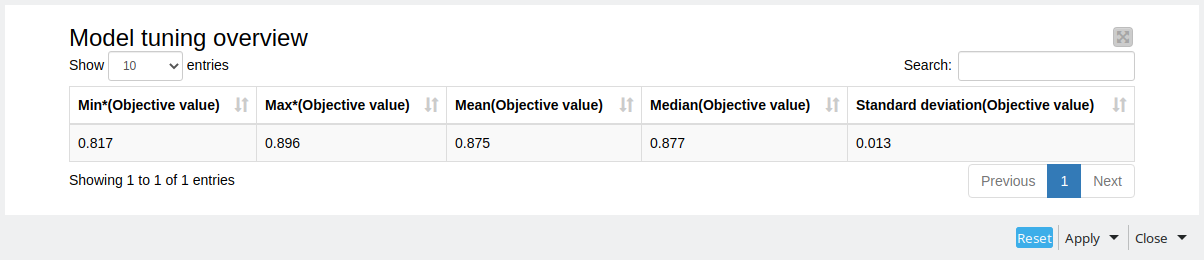
The average F-Measure for the prediction on the test set was 0.87, using the following parameters:
Number of Boosting Rounds = 21
Max Tree Depth = 3
Learning Rate = 0.2