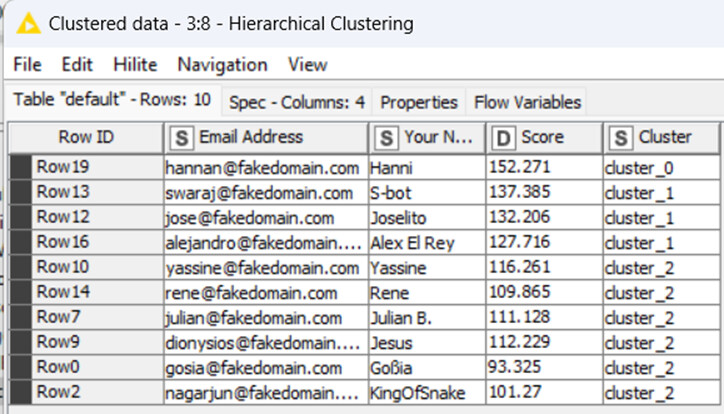
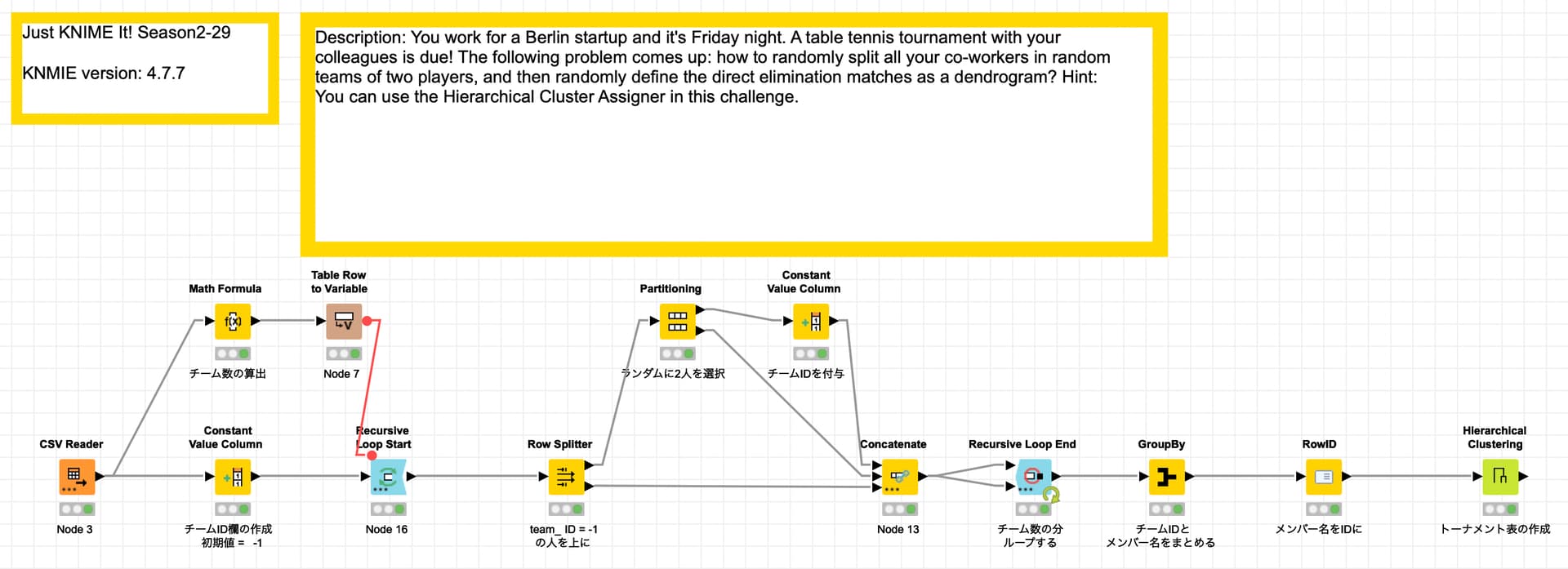
This week we shift our gears to something we love at KNIME: table tennis! Your goal is to randomly create teams with two players and then define elimination matches in a way that is easy to understand. Could a data app help here?
Here is the challenge. Let’s use this thread to post our solutions to it, which should be uploaded to your public KNIME Hub spaces with tag JKISeason2-29.
Need help with tags? To add tag JKISeason2-29 to your workflow, go to the description panel in KNIME Analytics Platform, click the pencil to edit it, and you will see the option for adding tags right there. Let us know if you have any problems!
This is an interesting problem. I couldn’t create the playoff brackets straight off without actually pairing up the players first.
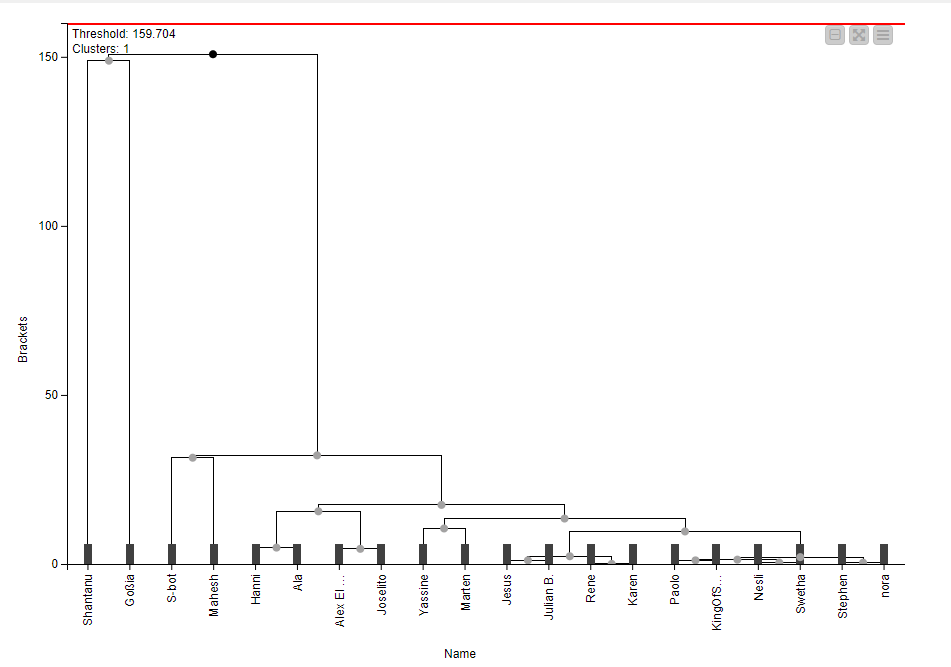
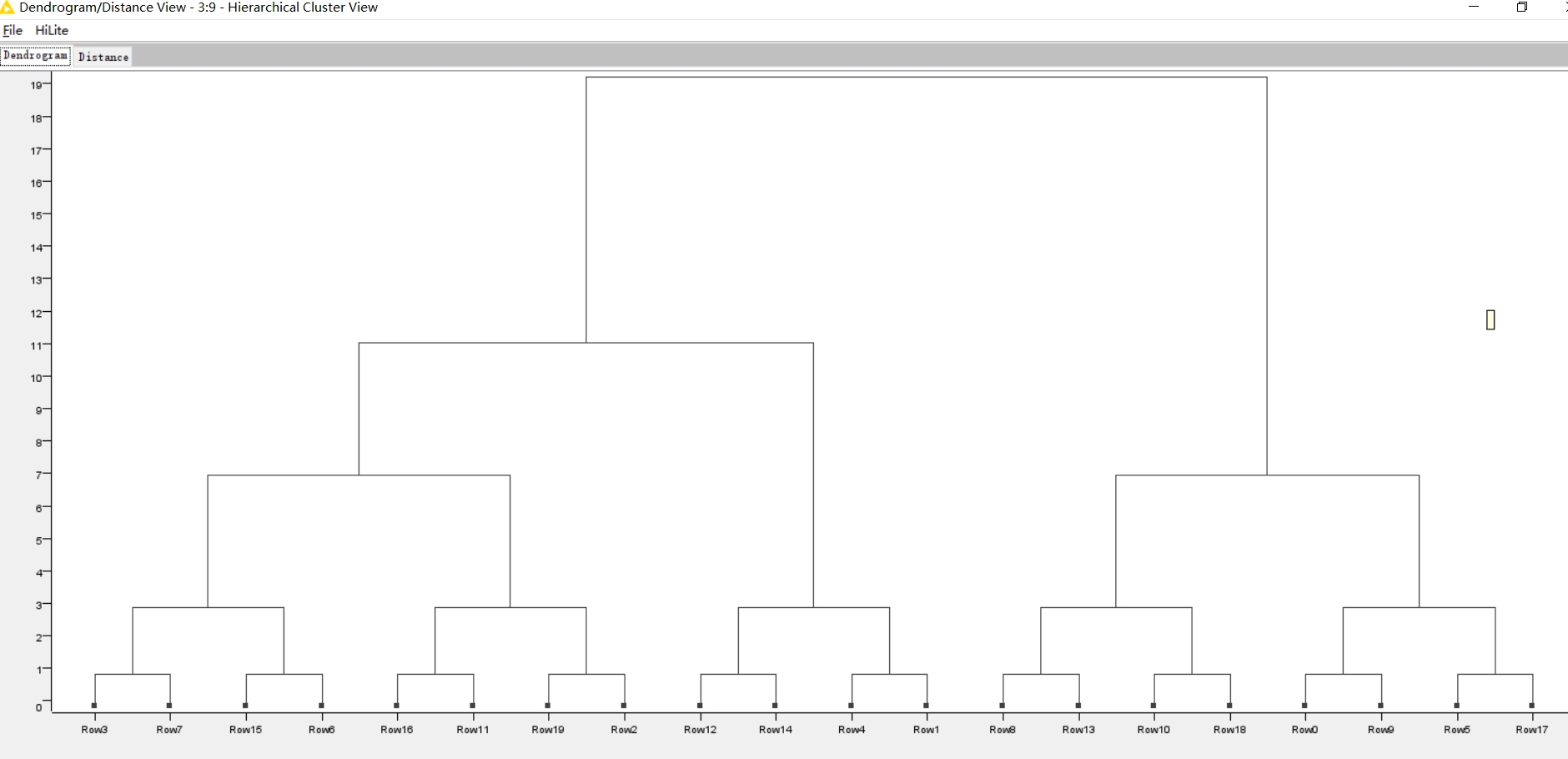
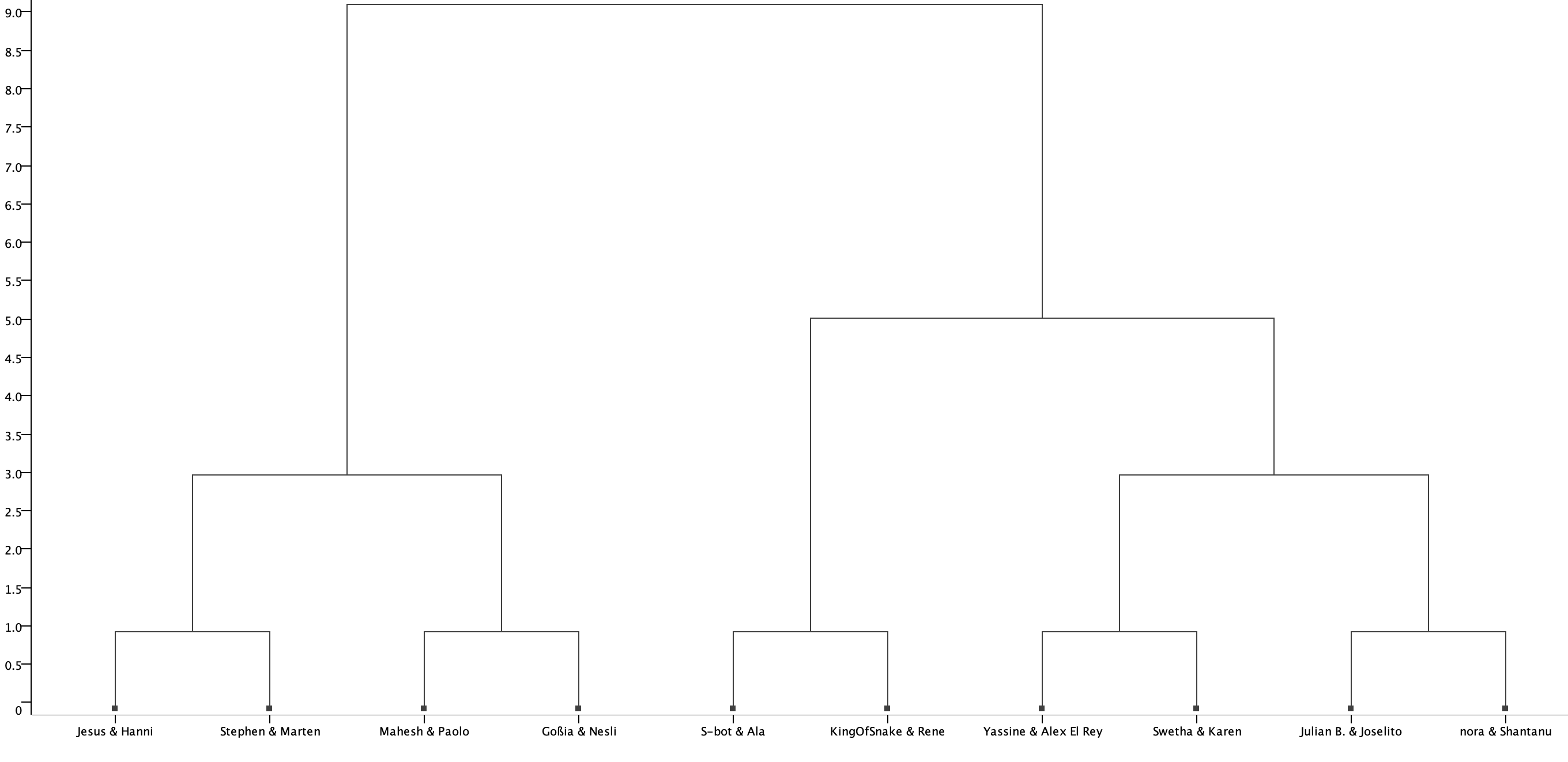
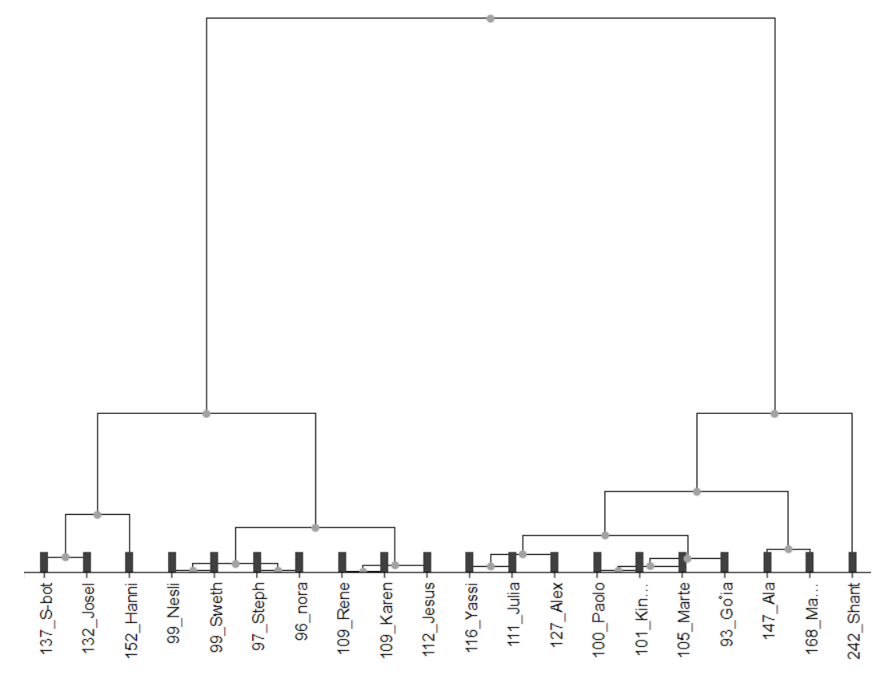
If we were to just do a h clustering on the dataset as is, it will result in a dendogram that’s not playoff bracket-like. Simply because there are 3 players or more who have similar scores, and 1 outlier who overshadows everyone. Hence, we’d have to figure which players should be matched to each other first; before creating the dendogram.
Approach
1. Find the strength difference between each player
This will give you many player pairs (approx 90) on a strength difference scale (0 to 60) 2. Sort the pairs by strength difference from lowest to highest. 3. Pick out the pairs that have low strength difference scores
Repeat until there are no more pairs to pick out 4. Generate the playoff brackets
NB: There isn’t much randomisation in this approach. One way to introduce randomness is to create “discrete buckets” in the list. Then draw a player pair randomly from each bucket and repeat 3.
Result analysis:
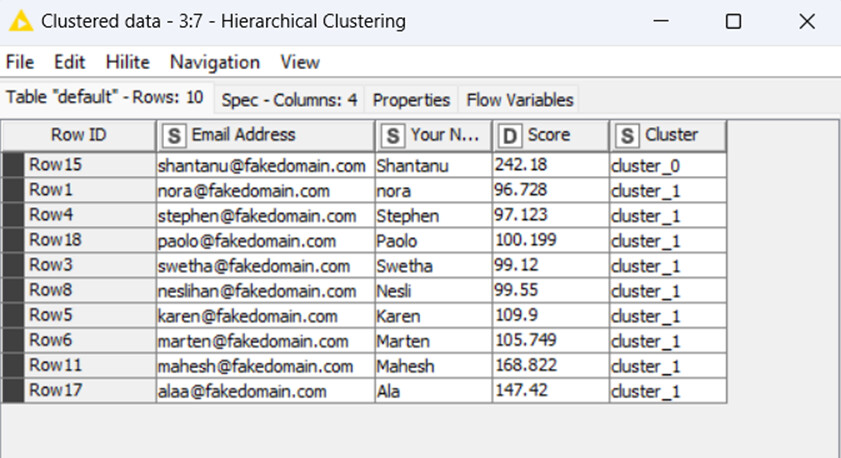
1.Employees with similar ratings will be given priority in the competition.
2.The employee with the highest score (Row15) directly advanced to the finals.
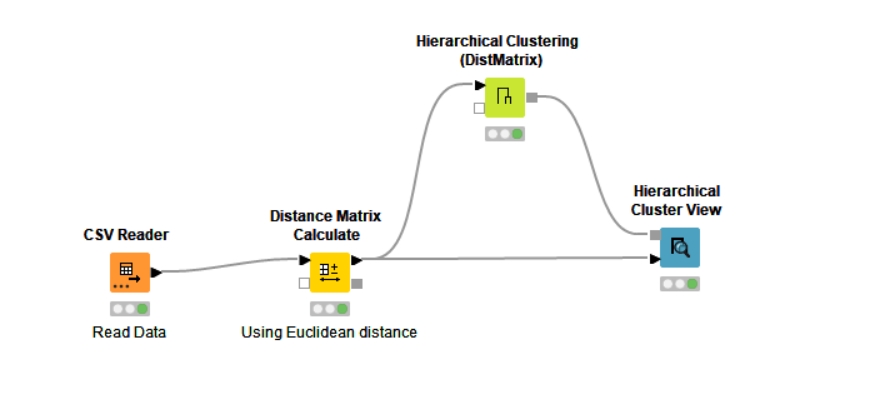
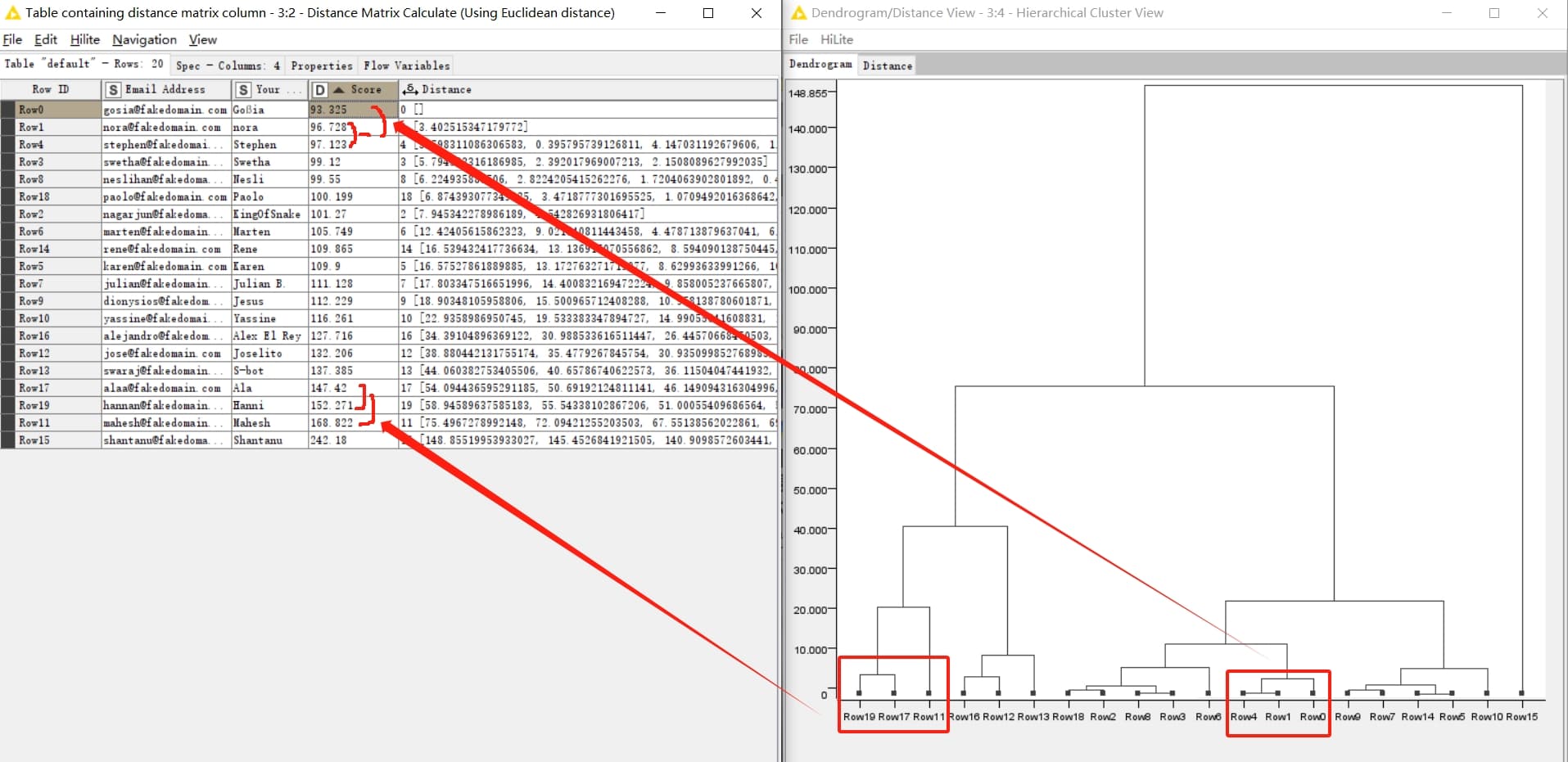
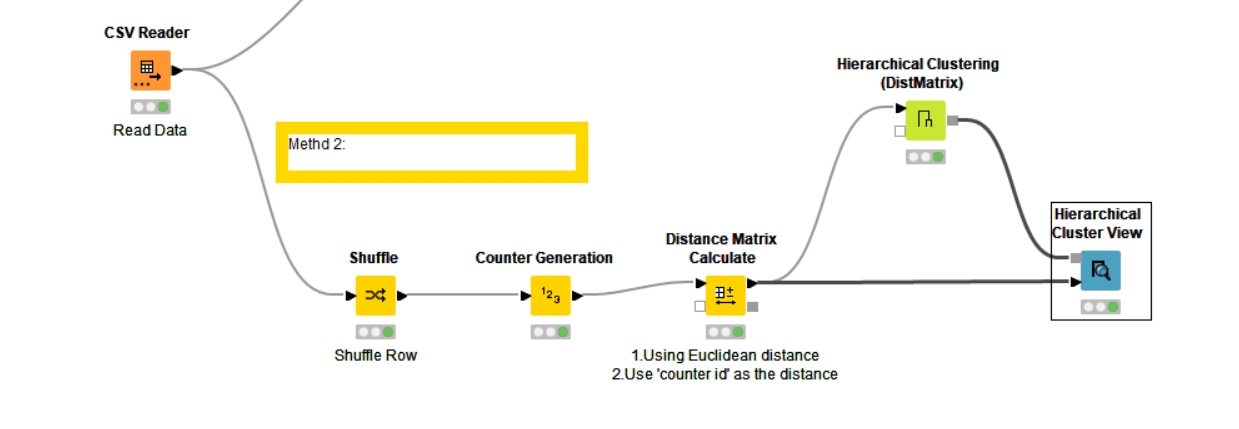
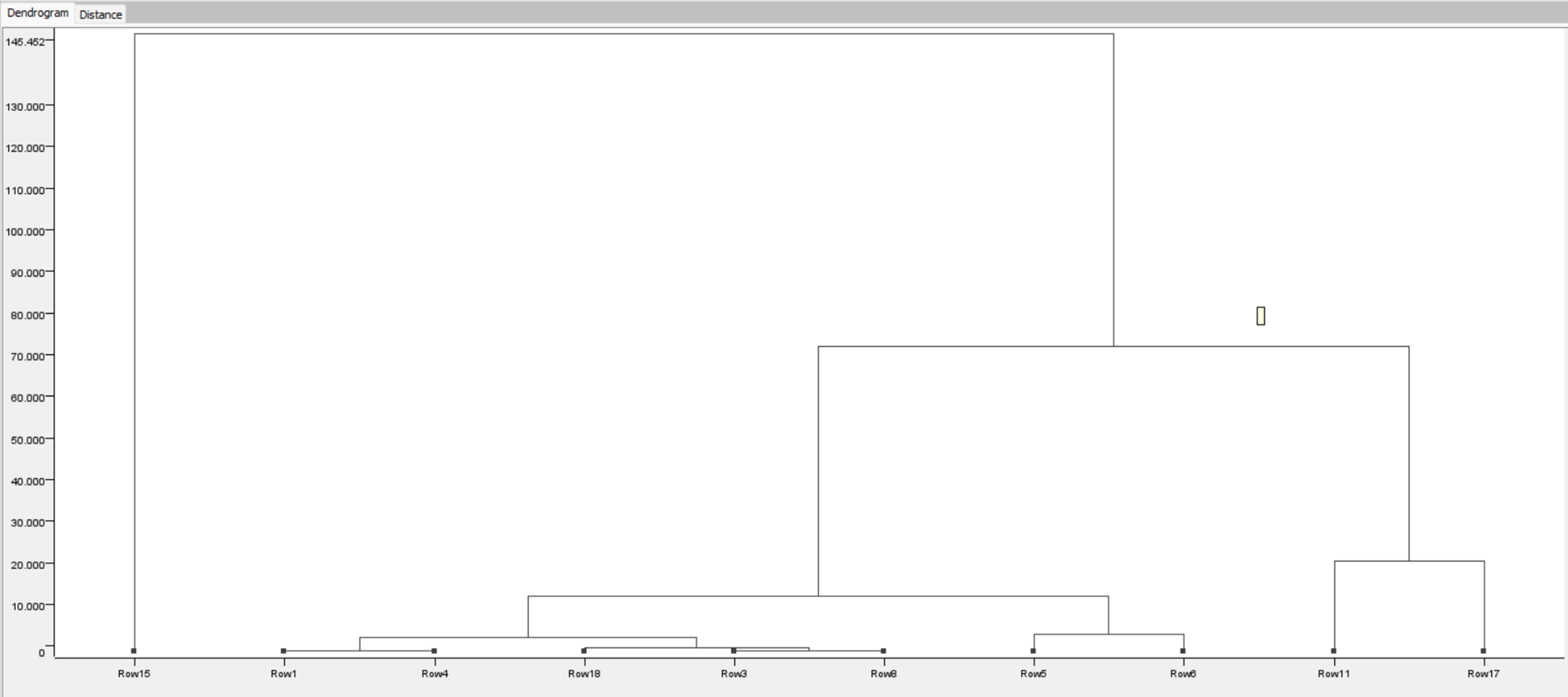
Here’s my solution. Tried using the scores to cluster. No luck, an outlier and some closely spaced scores seem to be the problem. Also played around with Random Number node which also didn’t work. Settled on Counter Generation which allowed me to create 10 clusters with 2 members each. Randomizing is a little suspect, but it works.
The entire set is randomly split into two groups. Within each group, the pairing is done randomly to decide who plays whom . The winner from group one plays the winner from group 2 to become the ultimate winner.
This is my solution.
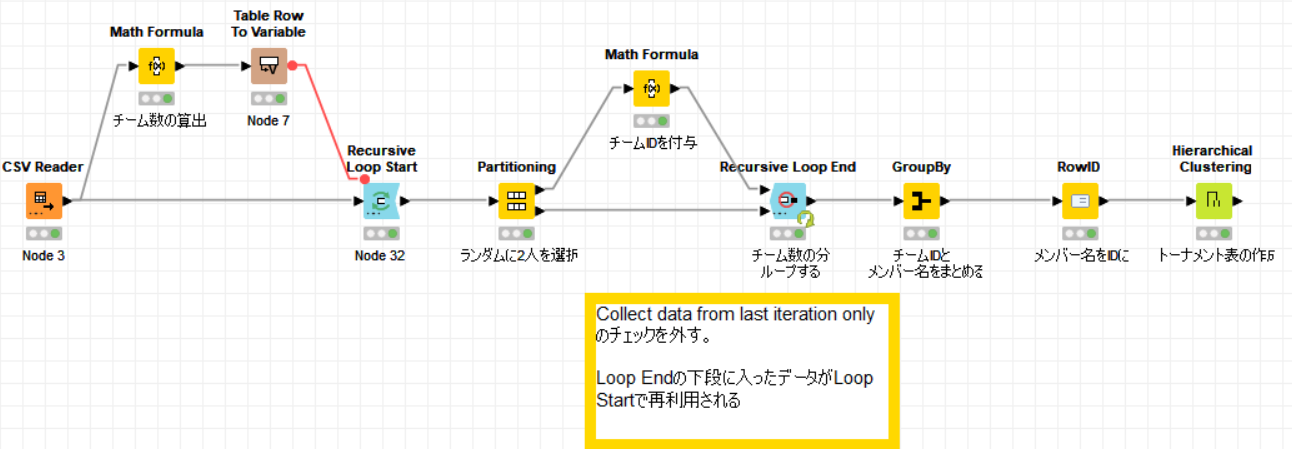
In this time, I focused in particular on how to determine team assignments to make a very simple workflow.
I think the Recursive Loop Start / End nodes worked very well
Here is my solution. I managed to solve this problem without hierarchical clustering, however I used the score as a metric for matching the players with the help of Similarity Search node. The most difficult part was to find the proper pairs of distinct players: some of the candidates have very high or low score.
Looking at the other participants solutions I realized that I managed to implement something similar to @skybe077’s solution, it was interesting to compare our solutions.
Learning from everyone’s solutions, I improved a bit more.
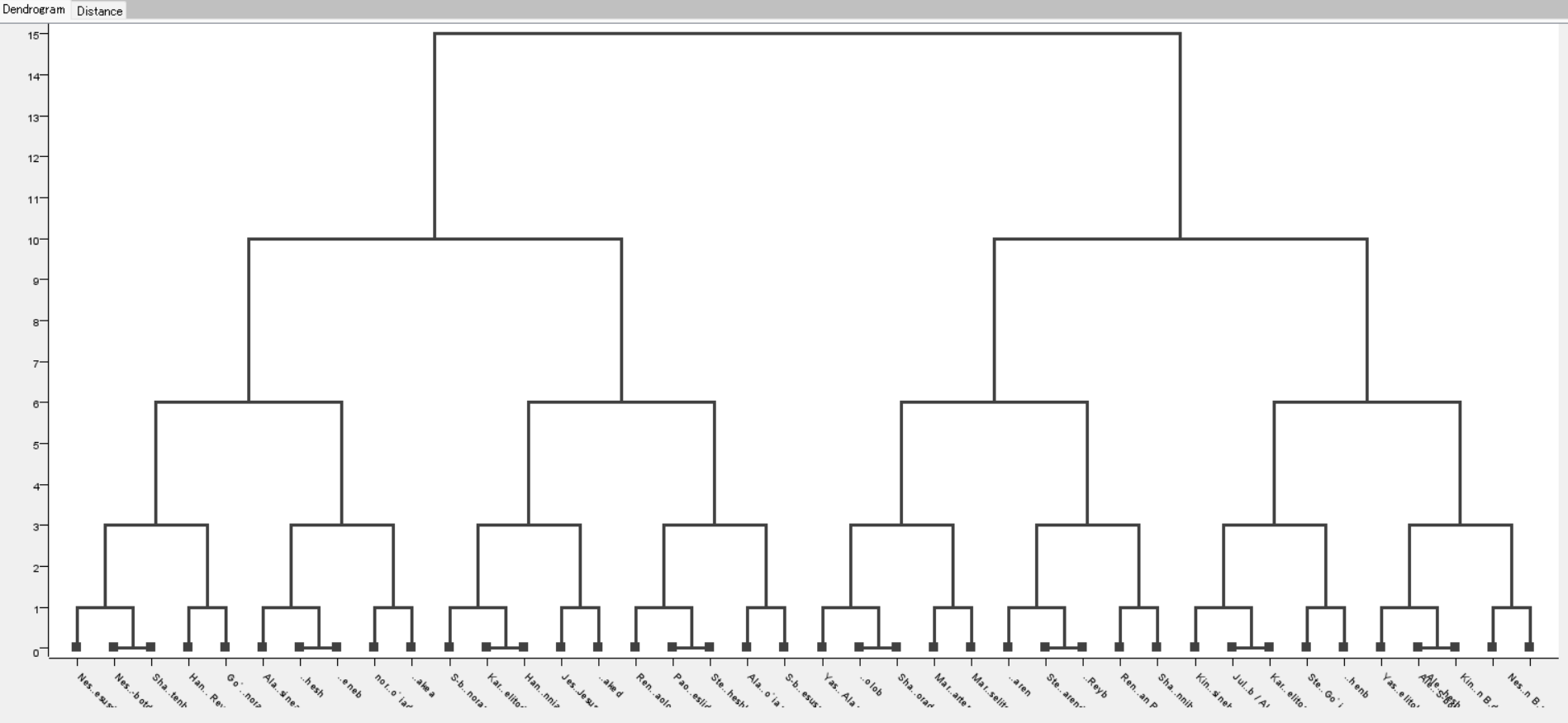
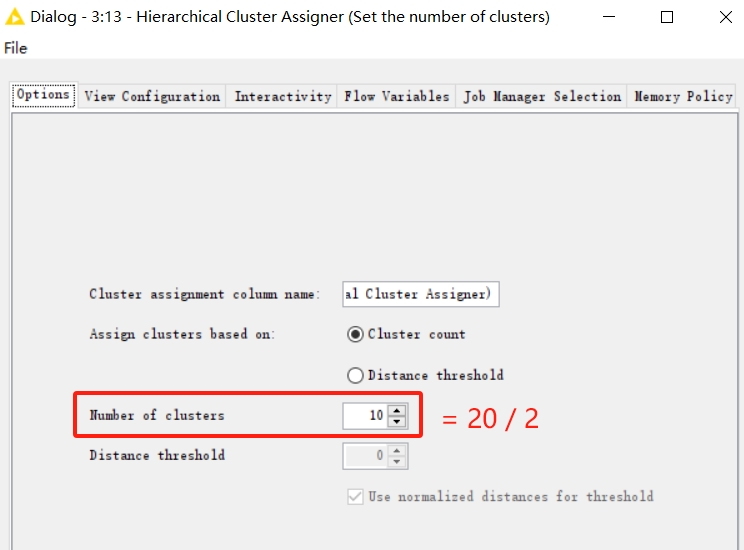
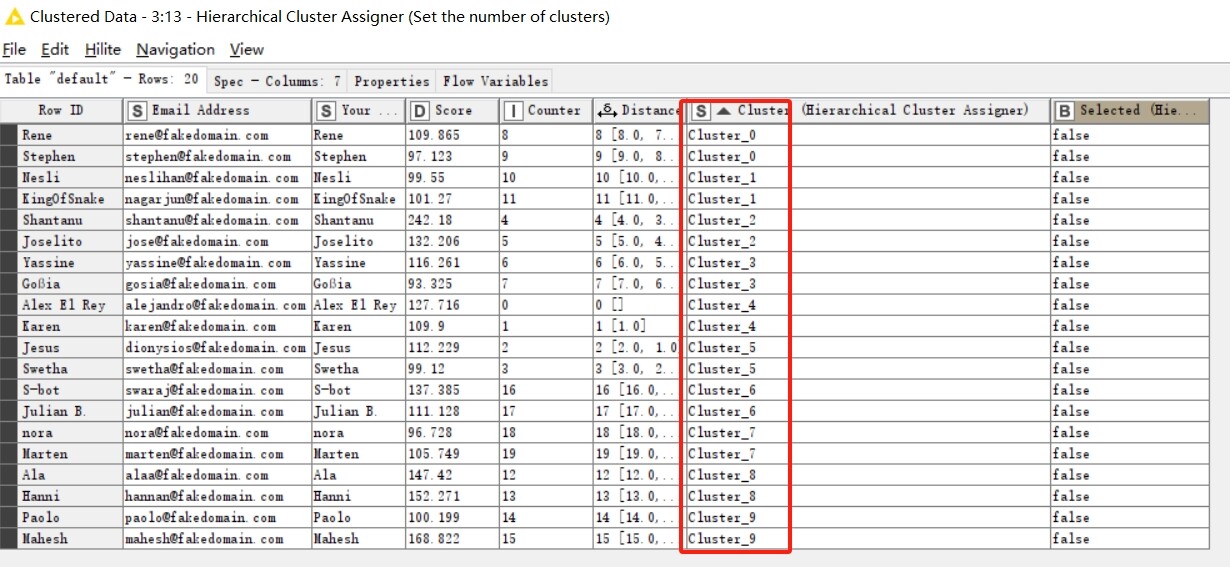
The ‘Hierarchical Cluster Assignor’ node can set the number of clusters according to requirements. For example, if we need to know the competition table for the first round, we can set the number of clusters to 10.
This question is interesting because it reflects the complexity of a real-world problem. Although the data is simple, analyzing and managing it is not.
We can use hierarchical clustering to group individuals based on their performance and match players with similar competitive levels against each other. This ensures that individuals with average levels compete against each other, while those with higher levels face off, promoting fairness.
However, this seemingly fair rule gives rise to other fairness issues. For instance, in a single elimination tournament like some football Cup, if Argentina and France face each other in the first round, one team will be eliminated right away, which is undesirable. Ideally, we want to see the strongest teams in the final.
In other words, while we use historical achievements to group individuals fairly within the same level, we neglect fairness towards those at higher levels. It took them more time and effort to get there.
In real world, we have ample data at our disposal, and our decision-making heavily relies on it. However, the choice of which data to use and which to disregard directly impacts our final result. In this case, we won’t consider the “Score” data and instead group individuals randomly.
Of course, using random methods is an easier approach, but we can go further. For example, if there are initially 10 groups of two individuals each, we can place the person with the highest score in Group 1 and the second-place individual in Group 10. This way, the first and second-place finishers may meet at a later stage. Real tournaments generate complex or simple tournament graphs based on different objectives and constraints, such as financial or time limitations. You can see examples of this complexity on the Tournament Management website challonge.
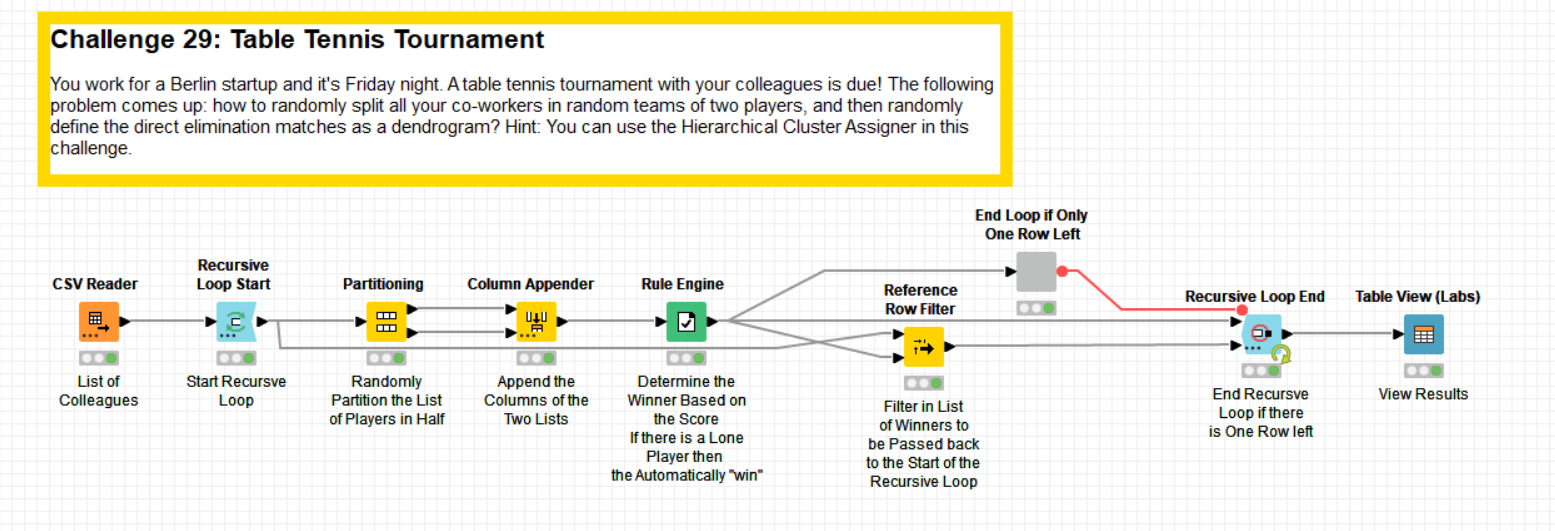
This week I have used a recursive loop to loop through the different rounds of the tournament rather than using a Dendogram.
Inside the loop, the players are randomly paired together and then the score is used to determine which of the players wins. In the case where the number of players is an odd number, if a player hasn’t been paired with anyone, they automatically go through to the next round. The overall winner is always the player with the highest score in the table.
The recursive loop ends when there is only one row left in the table (the last game has been played).
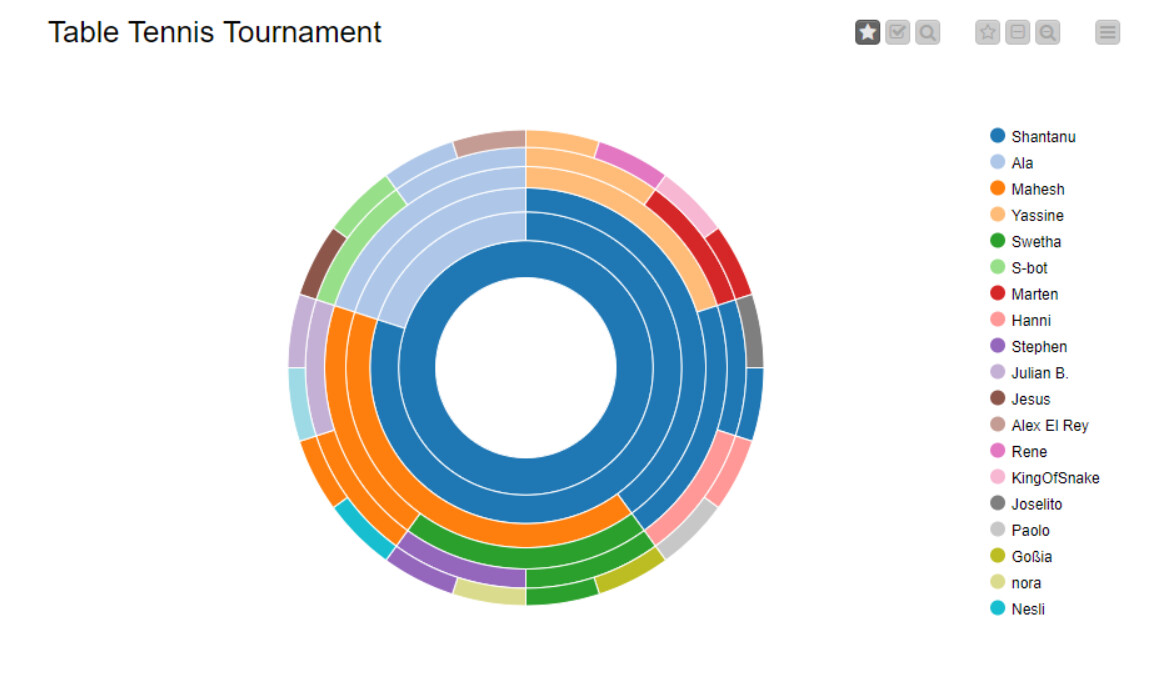
I have just updated the solution to add a Sunburst Chart at the end of workflow. This Sunburst Chart shows the rounds of the competition, moving inwards towards the centre of the circle where the final winner of the tournament is shown:
As always on Tuesdays, here’s our solution to last week’s Just KNIME It! challenge
Our solution is somewhat simple and only takes into account one possible combination of matches. It’s cool to see that many of you took this challenge one step further and implemented ways of seeing other combinations. Very cool and, as this season comes to an end, we are impressed at the progress you all have made!
Tomorrow is our last challenge this season, and we can’t wait to see what you’ll prepare! See you soon.