It’s out, folks! The last Just KNIME It! challenge of this season has just been posted!
Good customer service is very important for any company, and in this final challenge we will explore how natural language processing and classification techniques can be leveraged to provide customers with more effective service.
Here is the challenge. We are once again closing a Just KNIME It! season with an open ended problem. It allows for a lot of creativity and we will not post a solution next Tuesday.
Attention! If you want your solution to count for this season’s leaderboard, upload it to KNIME Community Hub with tag JKISeason3-30 until Tuesday, 12/17, at 11:59PM EST.
Need help with tags? To add tag JKISeason3-30 to your workflow, go to the description panel in KNIME Analytics Platform, click the pencil to edit it, and you will see the option for adding tags right there. Let us know if you have any problems!
Thanks to everybody who participated so far! It means a lot to us!
At this stage I’m ready to make this a swarm-intelligence problem .
Been experimenting in a fair few directions and can confirm that this is a tough challenge :-).
Let me maybe share some of the angles that I have taken:
tried to engineer features out of the question pairs to then use the duplicate/non-duplicate as label
I did a fair bit of preprocessing - in the end I tried to compute the distance between the resulting vectors at which point I found it might be pointless to train a model that requires to create the same features after pairing the input question with all questions in the data set - in the end I thought it will boil down to the some sort of distance measure anyways so why try to train a classifier in the first place?
I then immediately thought about embedding models / RAG approaches and pursued an approach to try and process all unique questions through an embedding model, to then place in a vector store and then use an input question to search in that vector store
I ended up being to cheap for this approach as I did not want to process the 400k questions through a paid API - I was considering alternatives to try and leverage local Ollama embeddings models (nomic-embed-text), but as Ollama API is not compatible with OpenAI Api for embeddings I either had to run a proxy server to convert from OpenAI API to Ollama format or to try and implement this as a node in my AI extension. Either option was a little to far away from a low-code approach (@roberto_cadili thank you anyways for your very comprehensive response for my friend )
Leverage text processing with similarity search
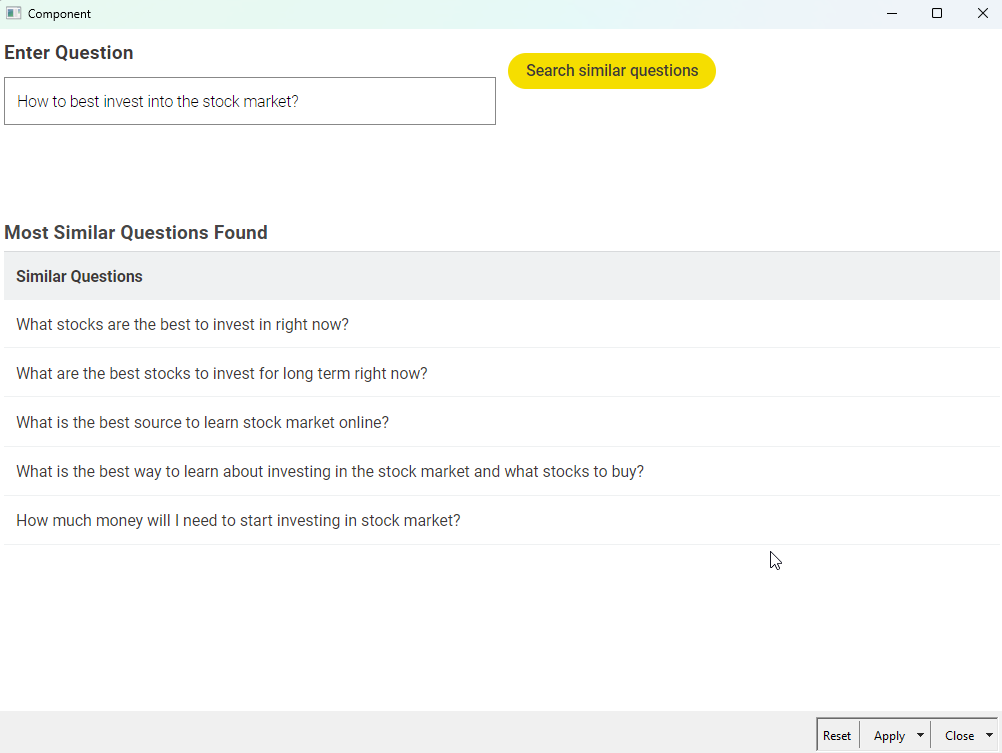
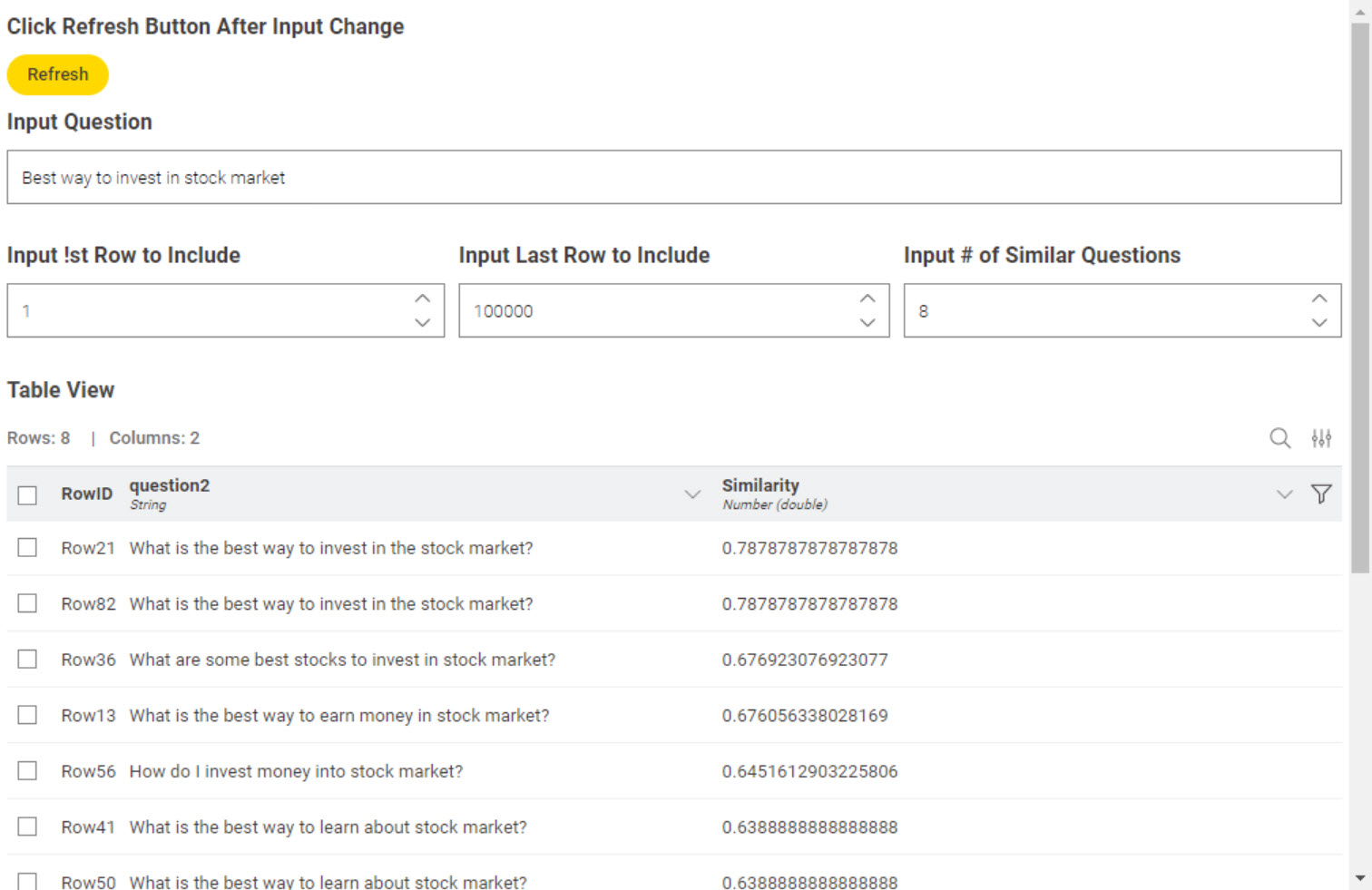
so this is actually what I have implemented in the WF below. After combining questions 1 and 2 and removing duplicates, I pre-process the documents and then use Document Vector Hashing to create a standardised Vector. Same preprocessing is performed on the input question and the same vector model is used to turn this into a vector. For this vector then a similarity search is performed in the main dataset and the 5 most similar results are output
This seems to work reasonably well, but it is really, really, really, really slow if ran on the full data set - I actually was not able to save the WF with full data set due to size limit being exceeded so saved the first 10k rows in table format for my WF below.
Right now there are two components: Yellow for preprocessing the main data set - if you swap out the limited data set with the full one you can configure a number of rows to be kept after deduplication. Blue for entering a question that is then searched (Data app). The tests I ran thus far resulted in reasonable outcomes
Whereas my solution sort of works it is very Computational expensive (even with my 32gb RAM Knime has available on my machine) and very slow - so still have the feeling there might be ways towards classification that may speed things up, but have not yet found the right approach.
I know this challenge is super hard hehe. For those who have less powerful machines, feel free to work with a sample of the dataset! Also, we’re not expecting perfect results – just keep going as far as you can! <3
Hi all,
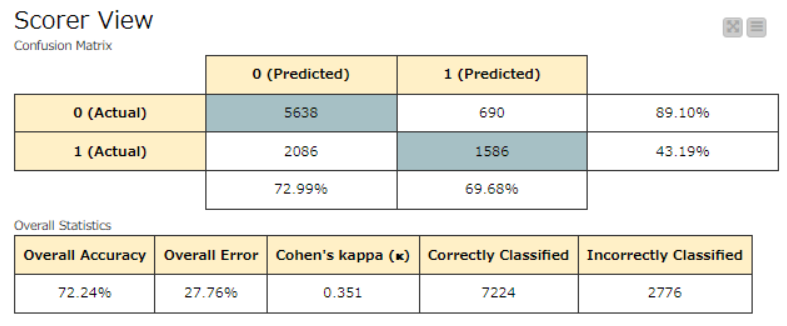
Here is my solution. Due to the specifications of my PC, I limited the number of training and test data to 10,000 each. I can achieve an accuracy rate of approximately 70% for the given question pairs. If I could train on all the data, the prediction accuracy should improve.
Hi all,
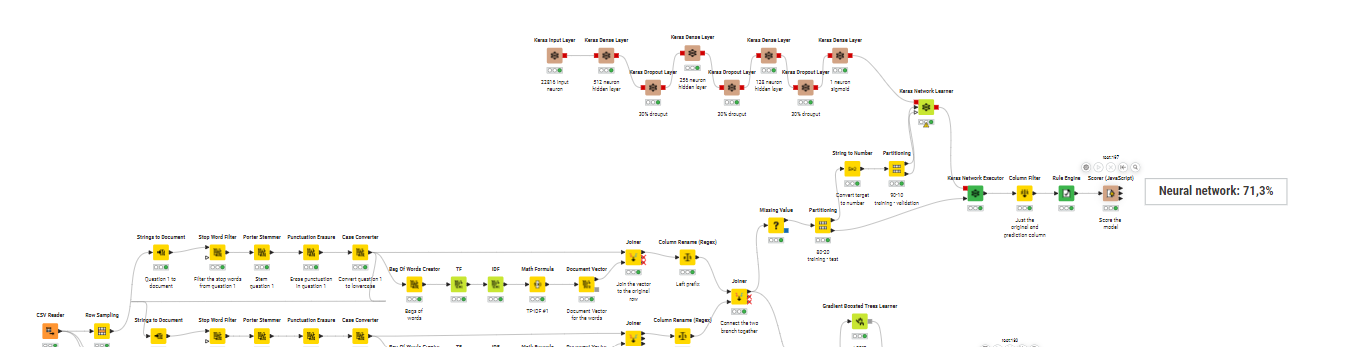
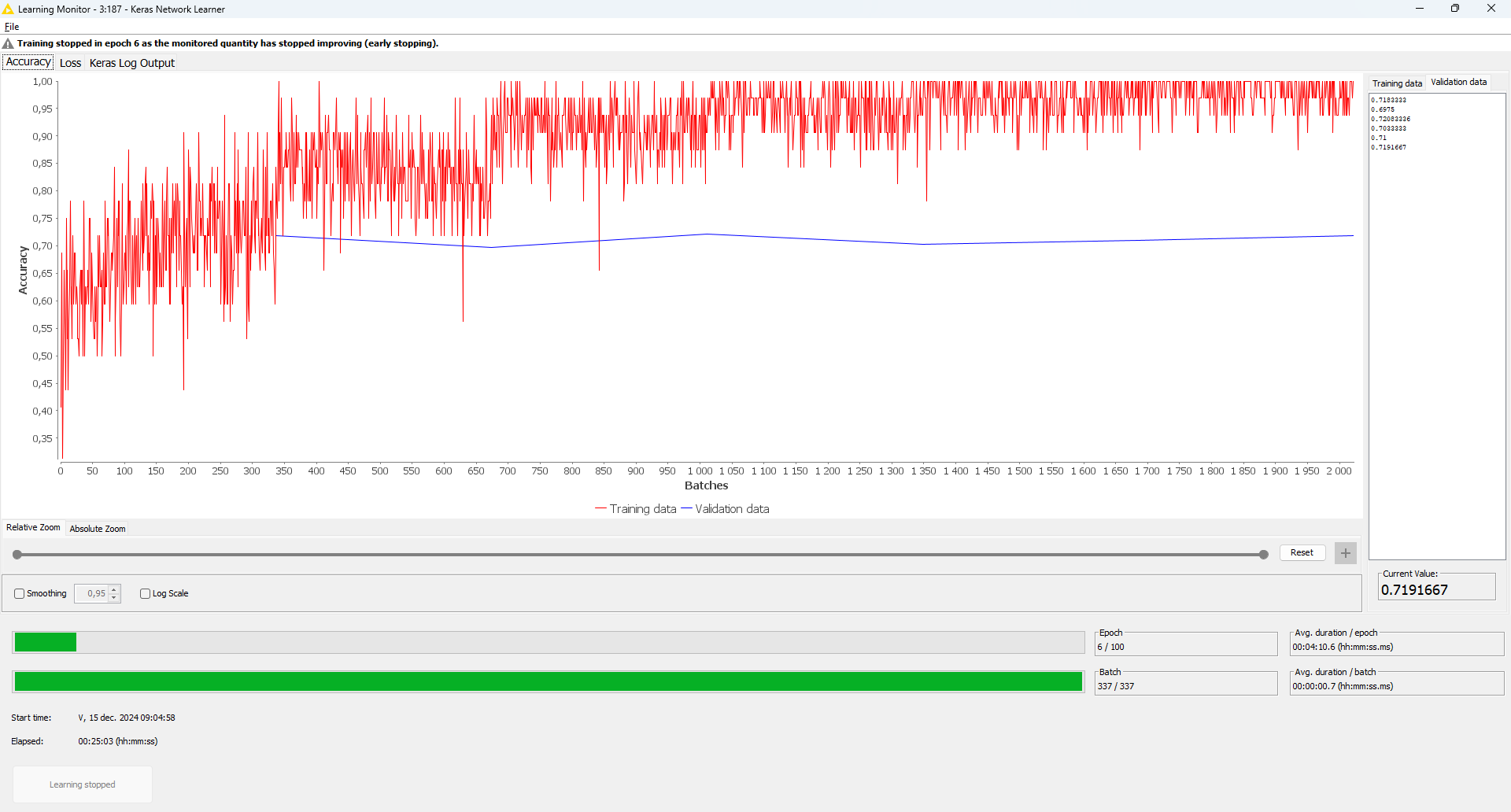
Here is my solution. I created the workflow by arranging LSTM for sentiment analysis available on Community Hub. (Train an LSTM for Sentiment Analysis – KNIME Community Hub). Since I am not familiar with deep learning, I did not really done any optimization. The training was stopped when the loss threshold was reached due to the early stopping setting. As the level suggested, this challenge was very hard for me , but I learned a lot. Thank you.
Huhh. This challenge was hard, and computationally intensive… Because the training is done on my machine I sampled 15000 rows (and I had to reset the workflow before uploading, as it was too big)
I’ve created three approaches:
No classifier, just similarity check (3-gram, Levenstein)
Traditional ML: Gradient Boosted Tree
Deep learning: Neural Network
Similarity check approach:
Simplest (only four nodes each)
The accuracy is not too good (67,8% for 3-gram, 65,7% for Levenstein)
After posting the solution I realized that I didn’t upload pictures of the confusion matrices, and I resetted the workflow… The numbers I got were not so high that I would have lied about them
Well, that was hard, but learned lot.
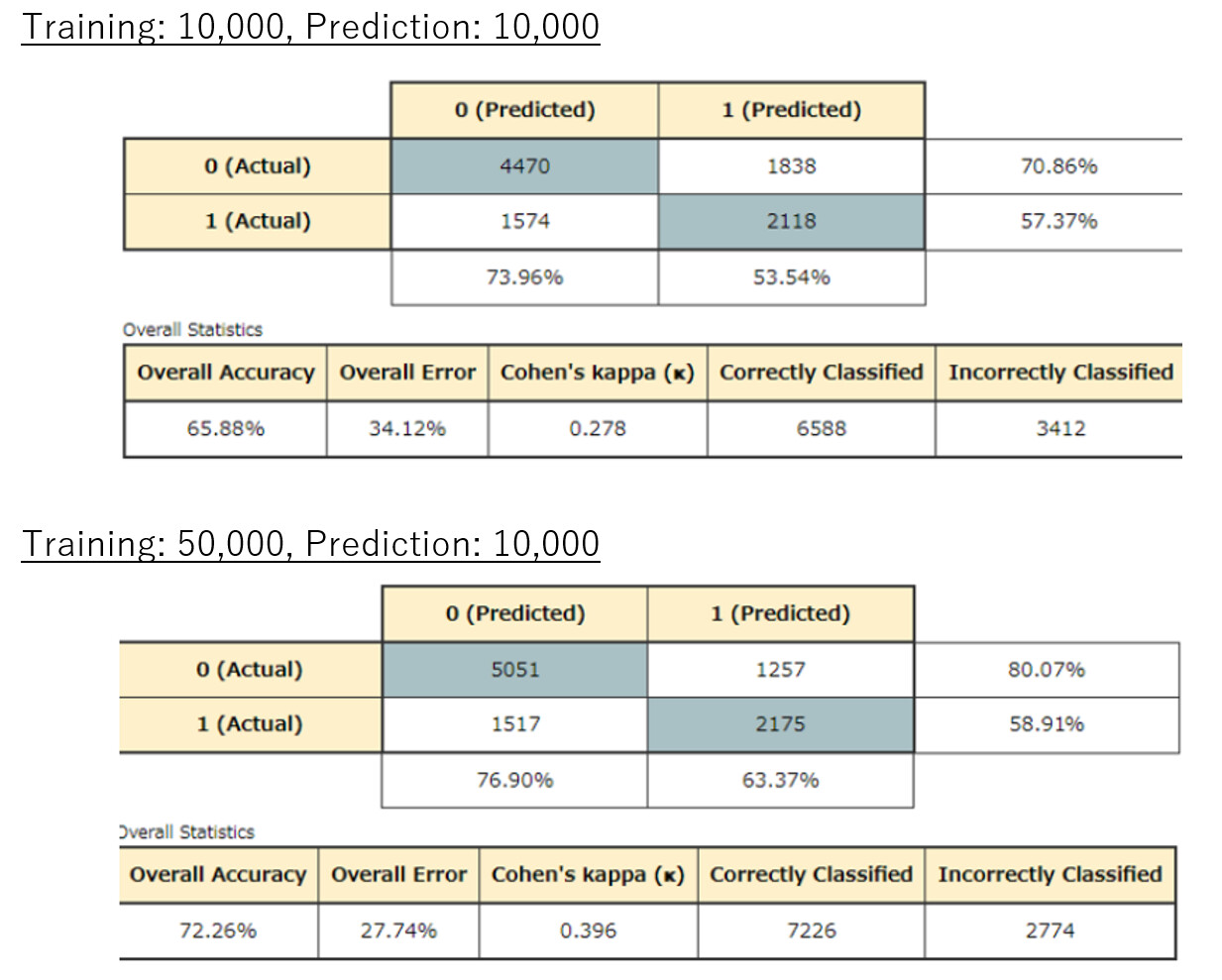
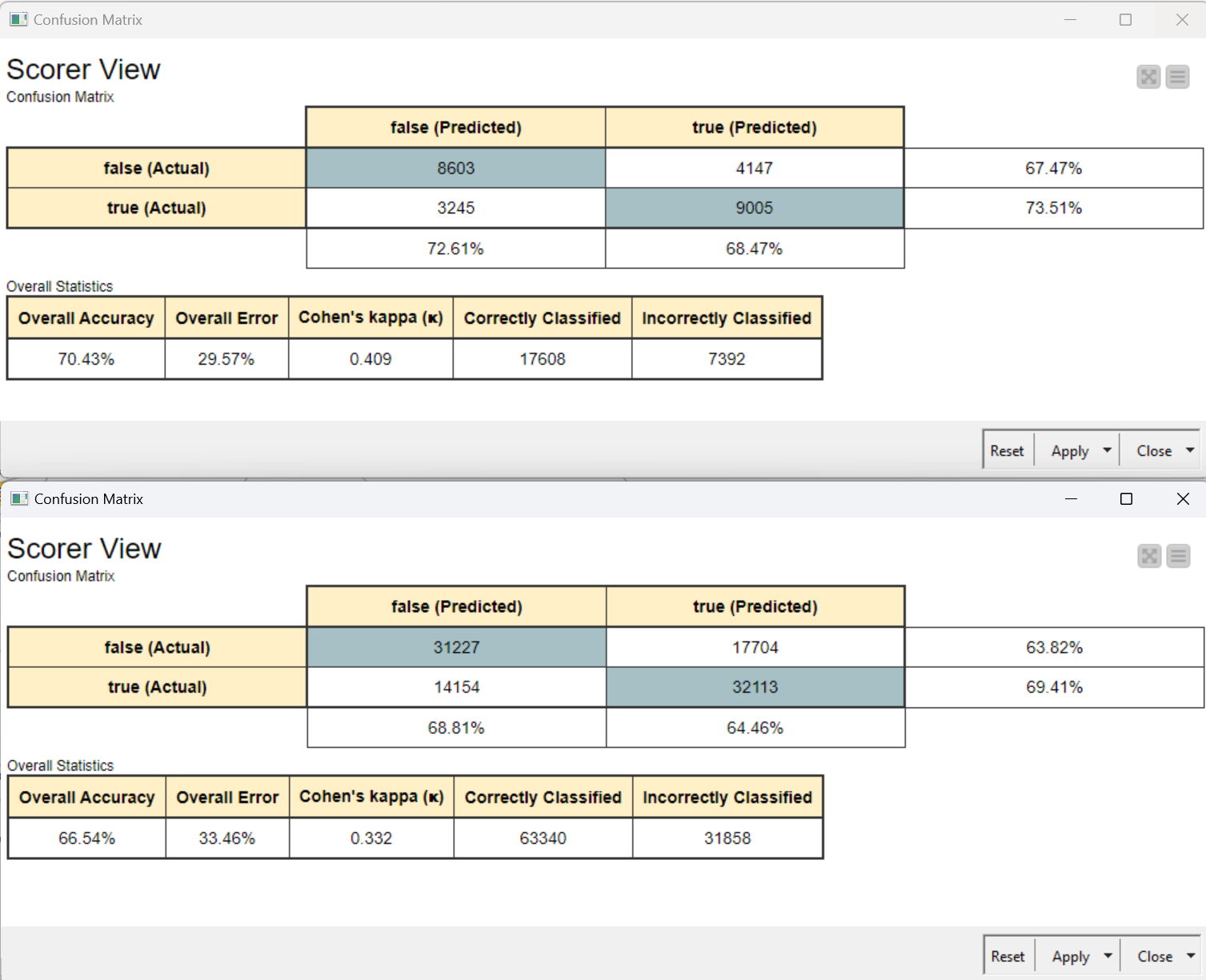
Cleaned up the dataset by correcting contractions, selected a balanced number duplicate / nonduplicates for training. Removed terms that were too short or too long & selected terms for training that were overrepresented in either the duplicate or non duplicate set.
Top confusion matrix is the validation set.
Lower confusion matrix is the test set.
After all that work, I don’t think I would use this model to make any decisions!
You folks are truly amazing for tackling this challenge head on. It was definitely the hardest one I remember posting!! I too learned a lot elaborating it.
Here are my tries for a solution.
I tried String Matcher and different learners but results are not very satisfactioning.
I also set up a gpt4all connection to a local llm with data import as vector store but responds does not fit. So there is also the need to find a better prompt for the model.
I’m not finished yet but this is the status.
Thanks for this Just KNIME it Season, I really enjoyed it and learned a lot!
Hi all, here is my solution.
This challenge is far above my ability and I just tried to learn the concept from the great KNinjas.
Thanks to the KNIME team and KNinjas for the learning opportunity!