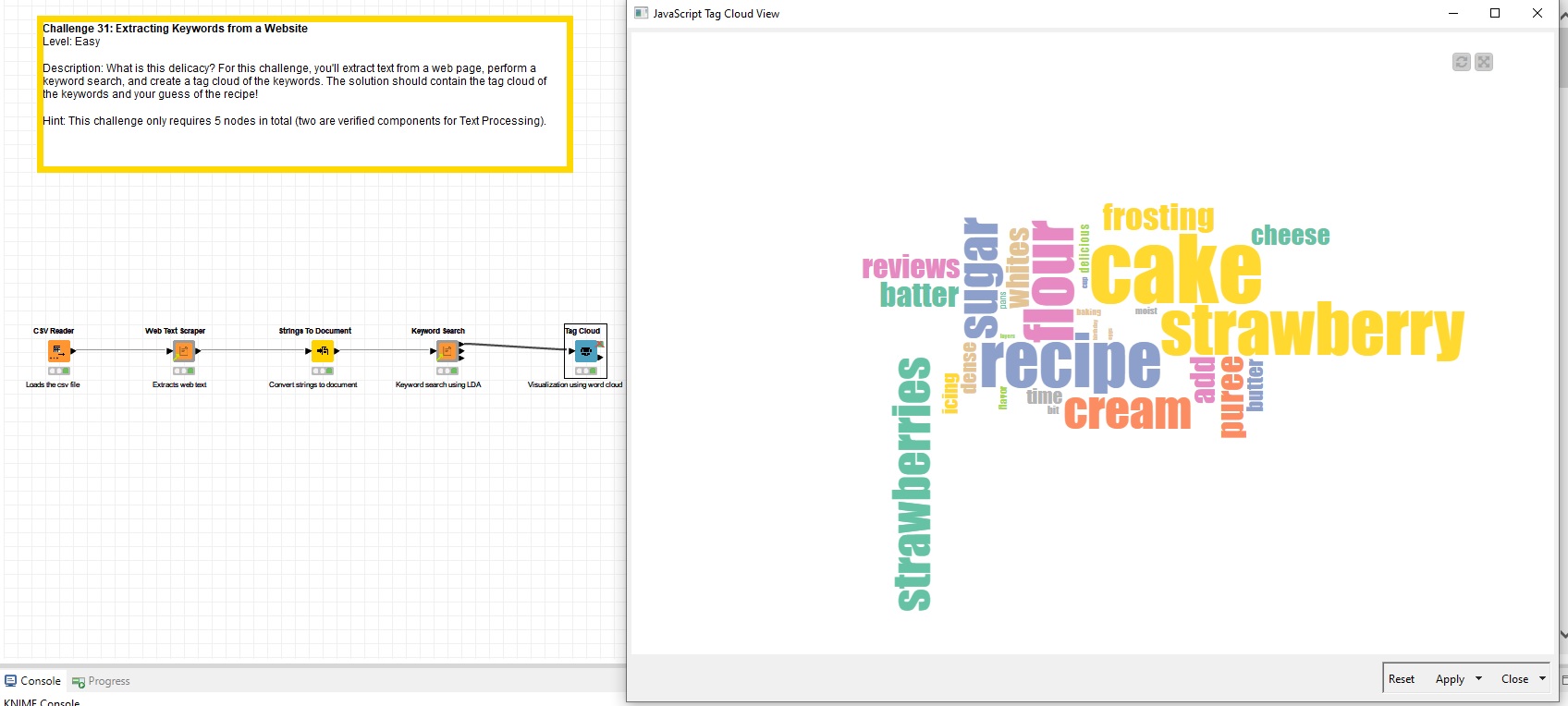
This thread is for posting solutions to “Just KNIME It!” Challenge 31. This week we have a culinary quiz: extract keywords from a recipe website. Can you guess the delicacy?
I decided to make a visual to compare the tag cloud of the strawberry cake and another dessert, tiramisù.
The main difference lies in the ingredients, as expected, but I also noticed some differences. The words “calories” and “diet” appear two and three times respectively only for tiramisù; strawberry cake must look more appealing, since the word “photo” appears five times on the webpage.
Have a nice evening (and don’t exaggerate with sugars ),
Raffaello
If I execute my workflow, Web Text Scraper generates this error.
WARN Java Snippet 3:2:0:1 Evaluation of java snippet failed for row “Row0”.The exception is caused by line 45 of the snippet.
WARN Java Snippet 3:2:0:1 Exceptions in the code caused missing rows to be output.
Check log for details.
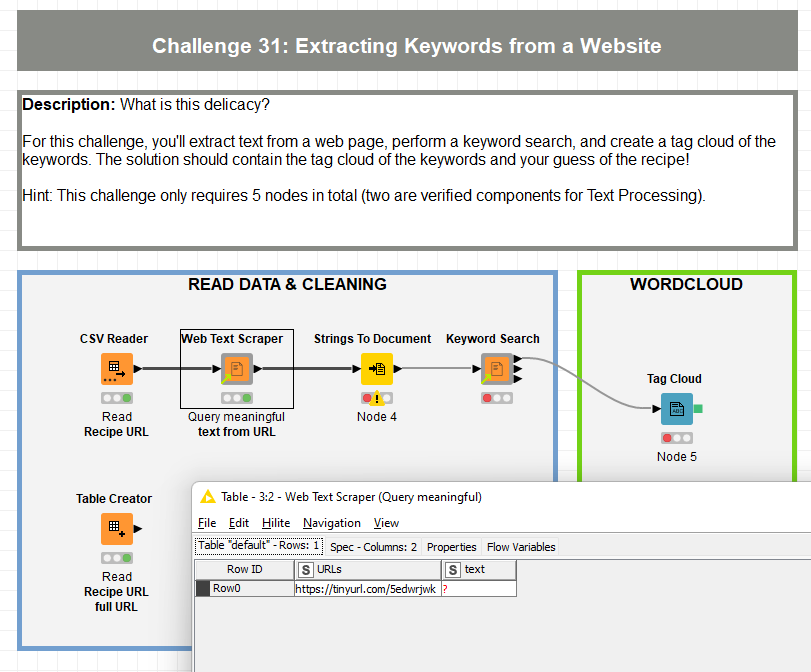
Hi @kwatari I find this interesting, cause when I ran your workflow, I didn’t get the same error, but I encountered an empty table issue instead. I then used the same workflow (yours) but this time around, I used my own CSV file containing the TinyURL, and I got through without anymore empty table issue nor any error.
I don’t know why it happened, and what to do to solve it, but I did try to find a workaround for you. You can try the original URL instead of the shortened TinyURL. Paste the original URL onto a Table Creator Node and feed it into the Web Text Scraper Node.
Hi @badger101 Thank you so much. I tried Table Creator with the original URL but I still got the same error. Anyway, thank you and appreciated your advice.
Hi everyone !
I was wondering if someone had found a solution about this… I tried the first time with the provided URL inside the csv without success in getting any results with the Text Scrapper, then tried the approach suggested by @badger101 (full url in a table creator) again with no results !. Weird.
same issue here! I was using my work laptop and thought that might have been something related to not up-to-date extensions or platform. So I used my personal PC and everything worked as expected with no changes in the workflow or settings. Weird!
Thank you @eamendola for pointing out that Text Scrapper works sometimes and other times does not. I can confirm this. And therefore it doesn’t have anything to do with the input URL to feed the component to. My previous solution did not work because of this.
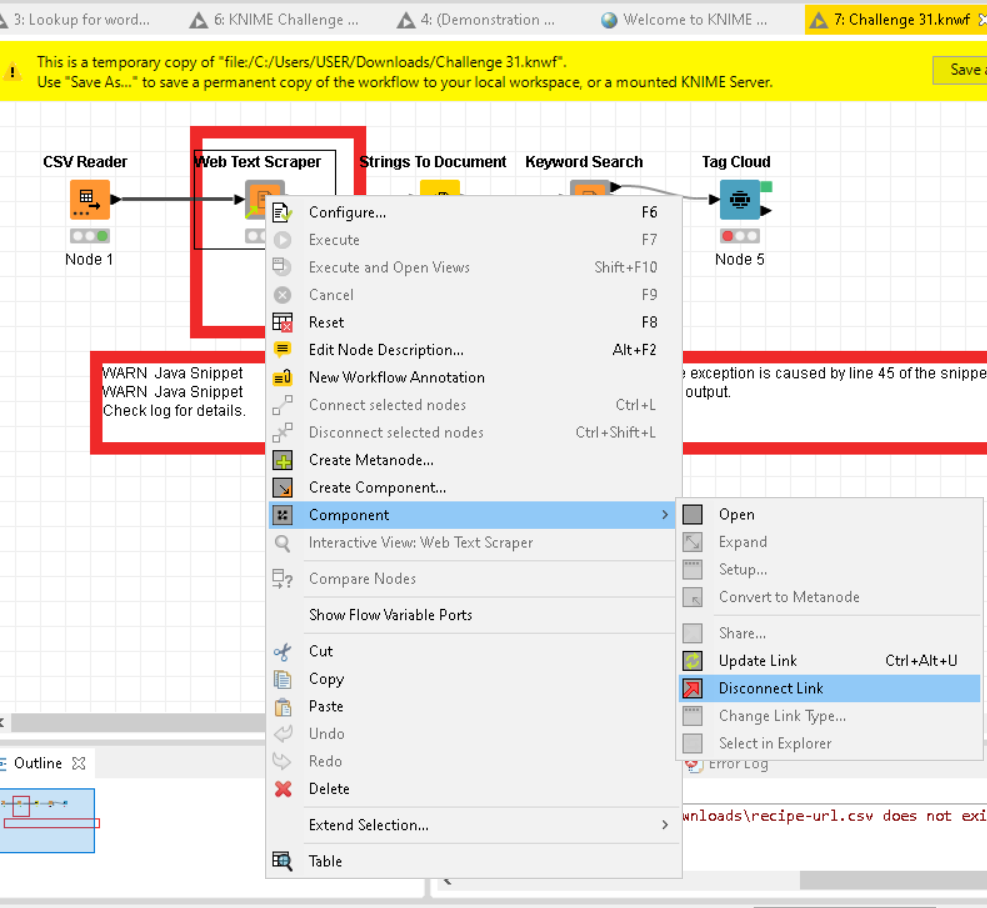
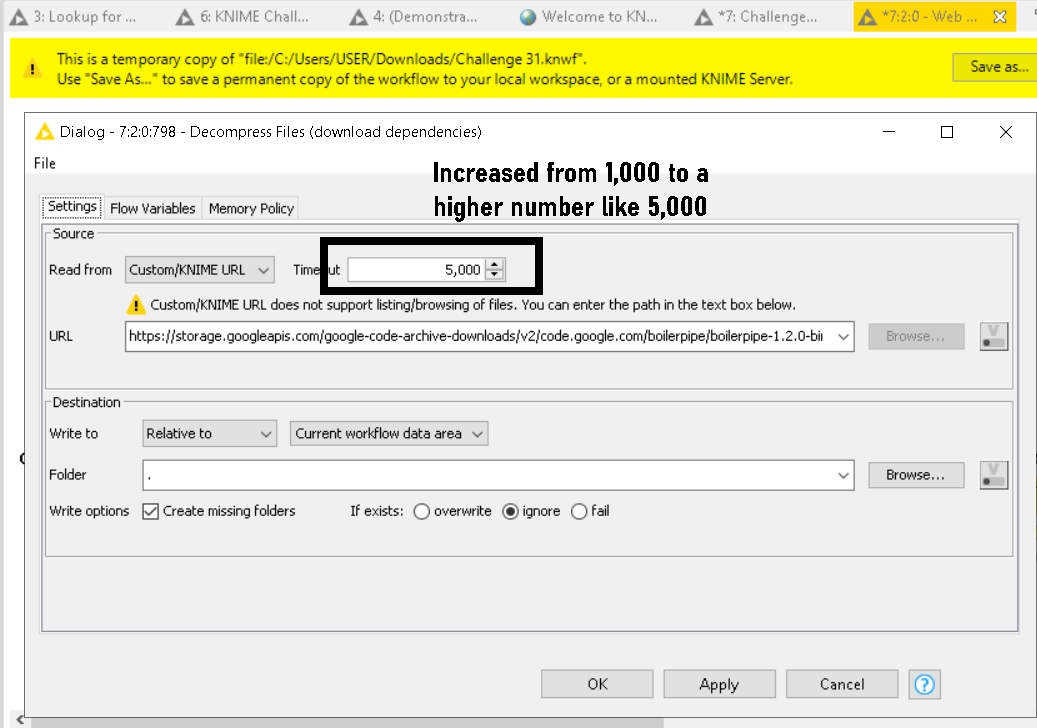
So, upon inspecting the component’s constituent nodes inside it, I found that whenever the component doesn’t work, it will be because of the failure of the Decompress Files node. The reason being is that the node limits the connection timeout to the custom Google API’s URL to 1000 seconds. So, the solution I found is to increase this timeout value. I chose 5000 and it always works.
Here’s a step-by-step approach to reconfigure the component:
If the timeout value is too short (where the default is 1000), the library sometimes will not finish downloading. This is hinted by the subsequent node “Wait…” of which the description says “Halt execution unless .jars are extracted.”
Note: There is a “lazier” method to “solve” this, which is by resetting the text scraper component and re-executing it. And repeat this until you get the result if failure occurs.
In summary, either give it more time, or give it more tries.
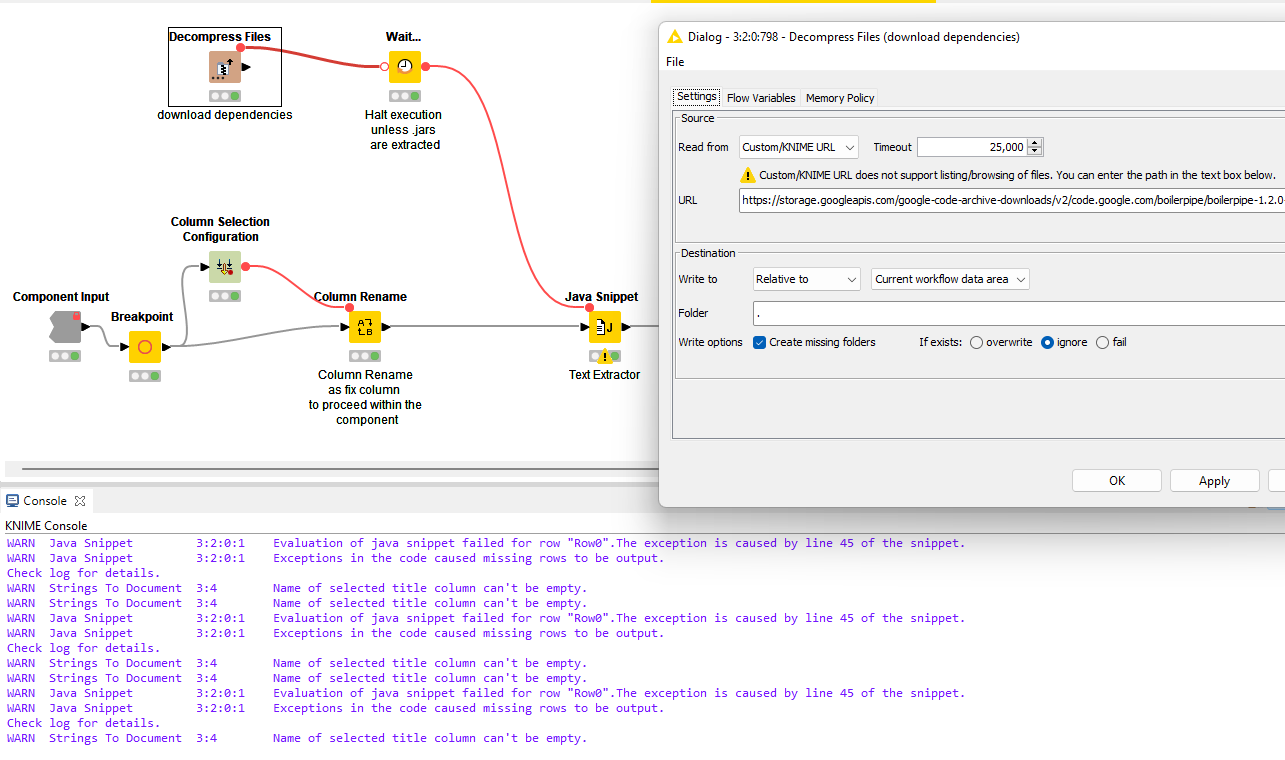
Thans for the detailed explanation @badger101, but unfortunately upon setting the timeout to even 25.000 it doesn’t work. Always the same behavior. I went from 5.000 to 10.000…15.000 and so on. I even executed the node several times with no results.
From the screenshot you showed, it seems that Java Snippet is what fails you. Unfortunately, that doesn’t occur on my end, so you’ll have to find an alternative solution that caters to that node @eamendola . I hope someone can look into this for you.