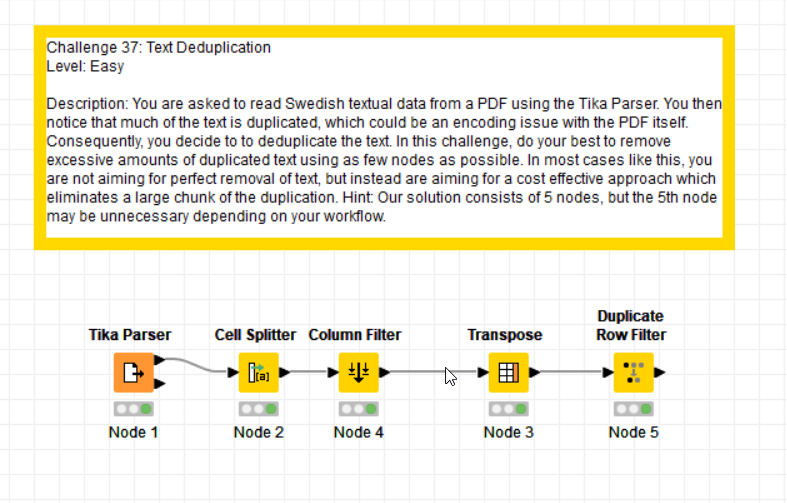
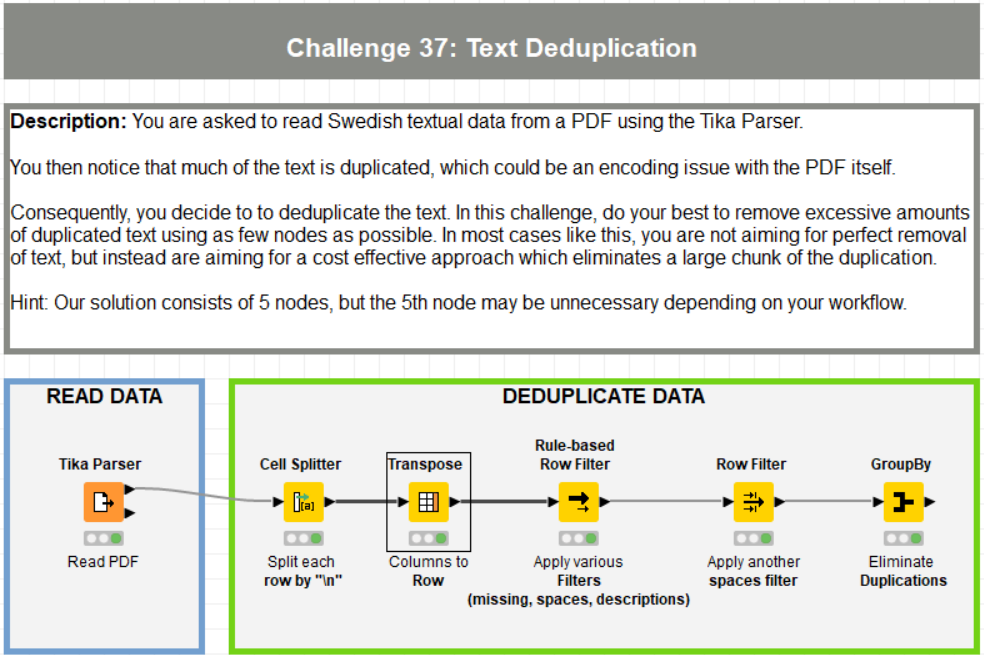
This thread is for posting solutions to “Just KNIME It!” Challenge 37. This week we’ll be working with text deduplication using PDF parsing techniques!
Here is the challenge: Just KNIME It!
Feel free to link your solution from KNIME Hub as well!
And as always, if you have an idea for a challenge we’d love to hear it! here .
Season 1 of “Just KNIME It!” is slowly coming to an end: we’ll wrap up on October 26!
Hello,
here is my solution:
Two alternatives:
In the first one, I detect the rows containing the incipit of the document and their position. Anything going from the position of the second incipit has to be discarded.
In the second one, I simply use a duplicate row filter to get rid of all duplicate rows.
Have a nice day,
2 Likes
Hello KNIMErs,
Here is my solution to #justknimeit-37
KNIME Hub > gonhaddock > Spaces > Just_KNIME_It > Just KNIME It _ Challenge 037
BR
1 Like
Here’s my solution using only 1 node (in addition to the Tika-Reader)
Cheers,
2 Likes
Adrix
October 5, 2022, 10:46pm
5
HI All,
I was clueless so based my answer in mix. of the first 2 I saw ( @lelloba and from @gonhaddock
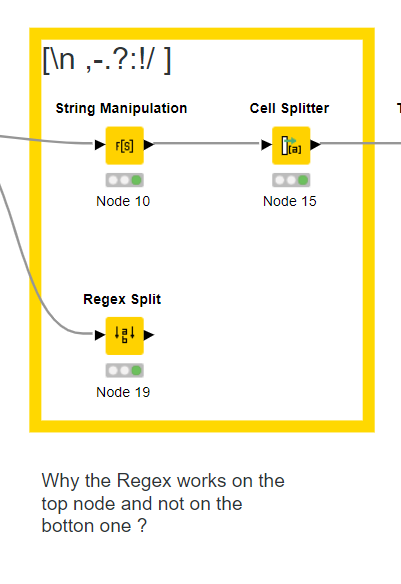
Also came with a doubt that I would appreciate some help :
2 Likes
Hi @Adrix , Regex Split requires groups using (). You can see my examples of this here:
3 Likes
AnilKS
October 8, 2022, 12:06pm
10
My take on challenge 37- text deduplication .
1 Like
kwatari
October 8, 2022, 12:47pm
11
Hi all, here is my solution.
1 Like
cf_123
October 8, 2022, 4:31pm
12
Hi,jKi-37 – KNIME Hub
1 Like
Afternoon everyone !
1 Like
ersy
October 9, 2022, 1:06pm
14
Hi everyone,
1 Like
As always on Tuesdays, here’s our solution to last week’s #justknimeit challenge!
See you tomorrow for a new challenge!
1 Like
system
January 9, 2023, 1:26pm
16
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.