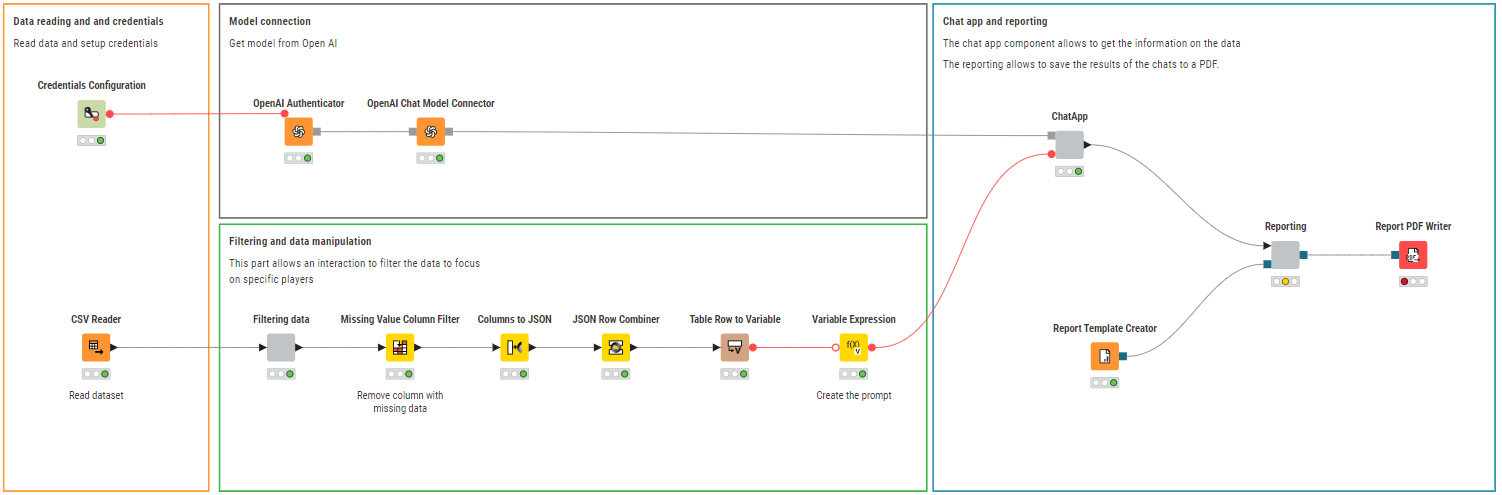
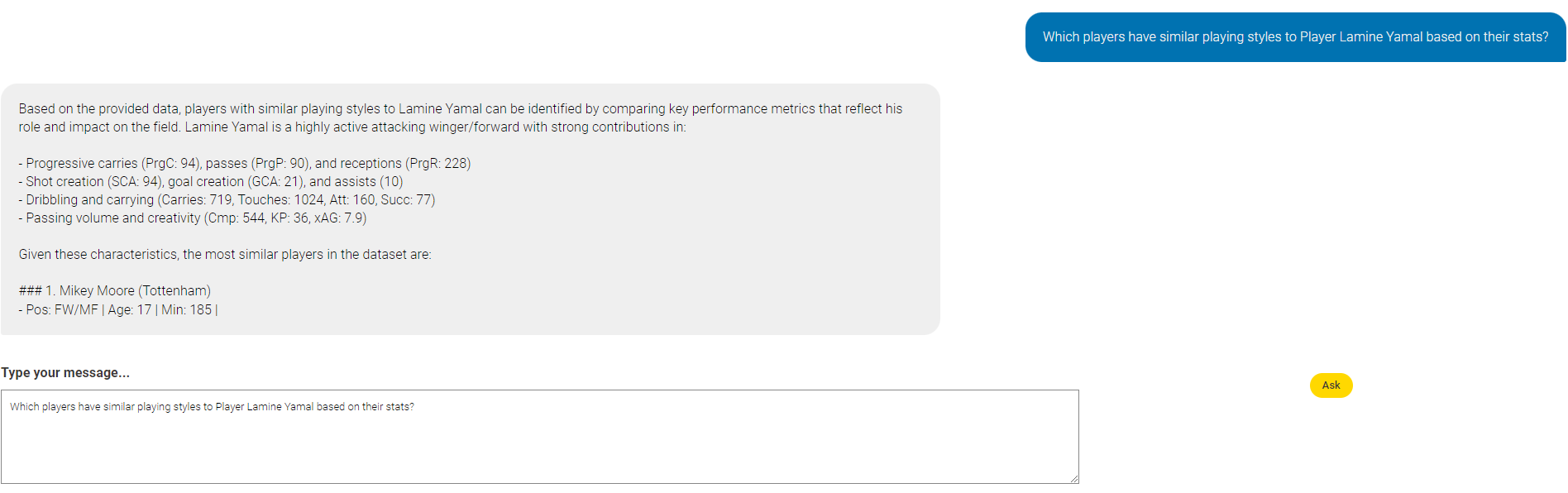
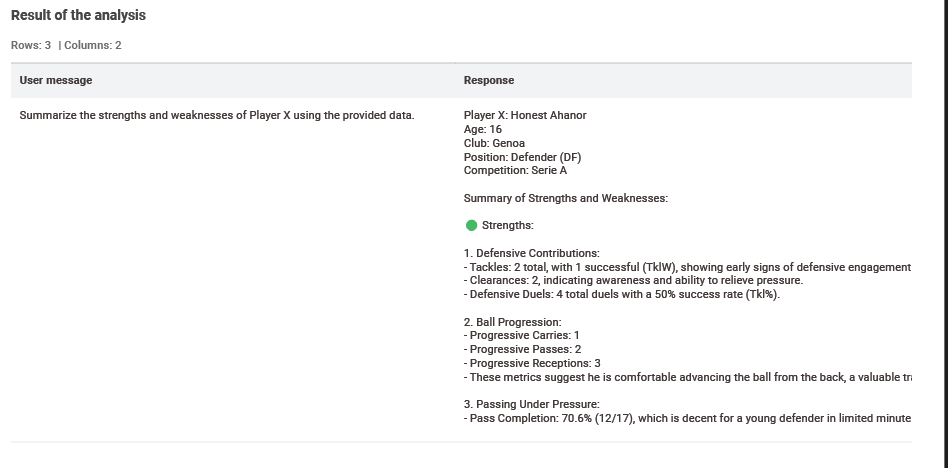
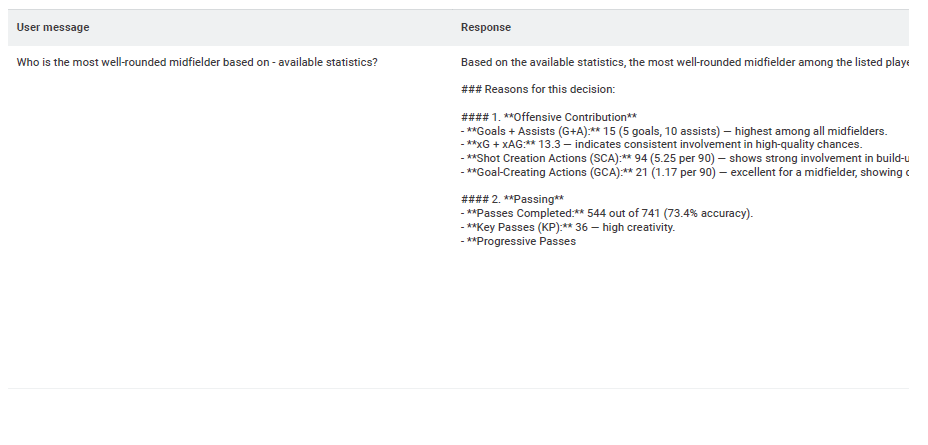
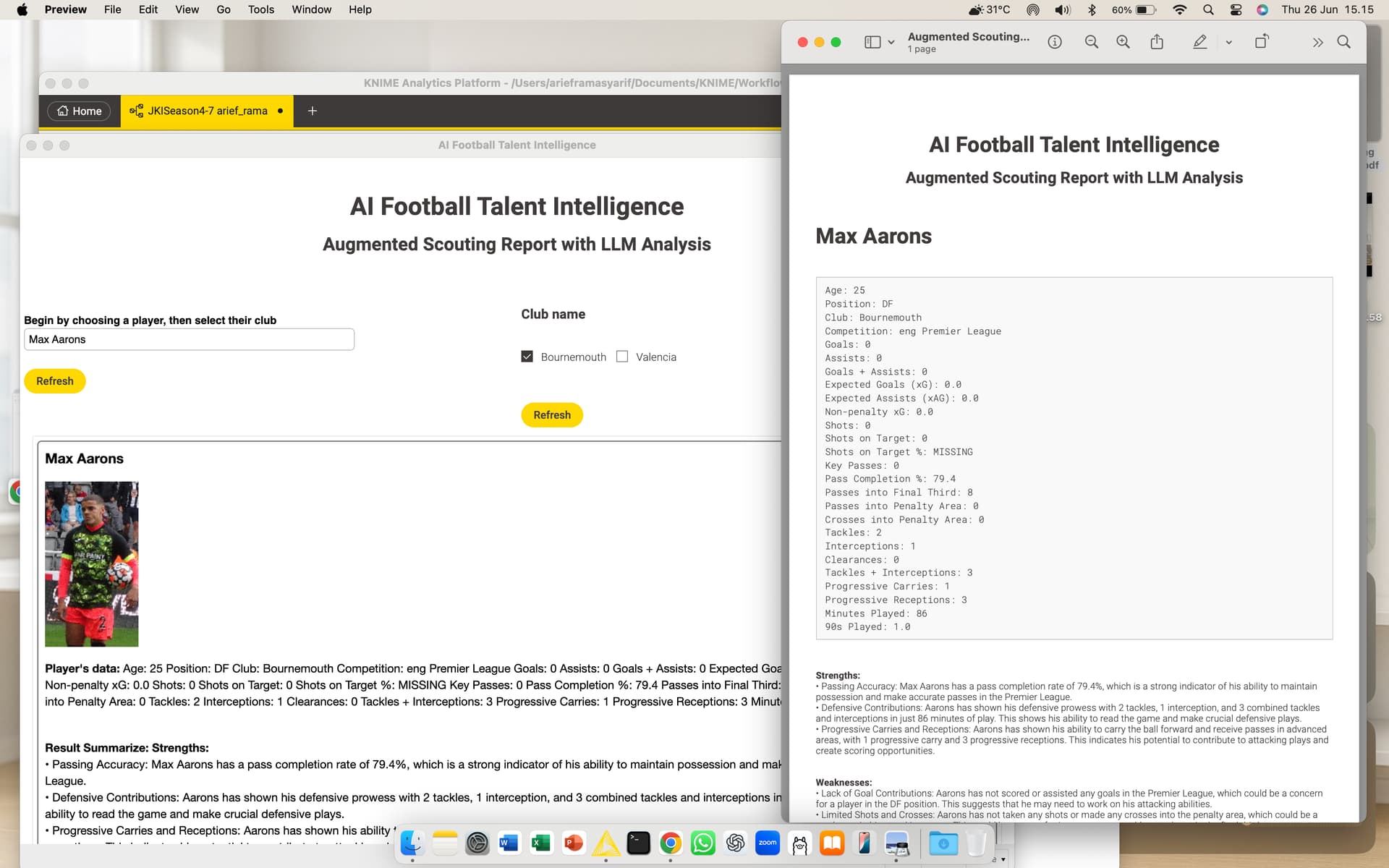
Let’s steer our focus this week to sports analytics with a puzzle on soccer. With the help of AI, find undervalued players, rising stars, and other patterns in soccer data, generating an insightful report for scouts as output.
Here is the challenge. Let’s use this thread to post our solutions to it, which should be uploaded to your public KNIME Hub spaces with tag JKISeason4-7 .
Need help with tags? To add tag JKISeason4-7 to your workflow, go to the description panel in KNIME Analytics Platform, click the pencil to edit it, and you will see the option for adding tags right there. Let us know if you have any problems!
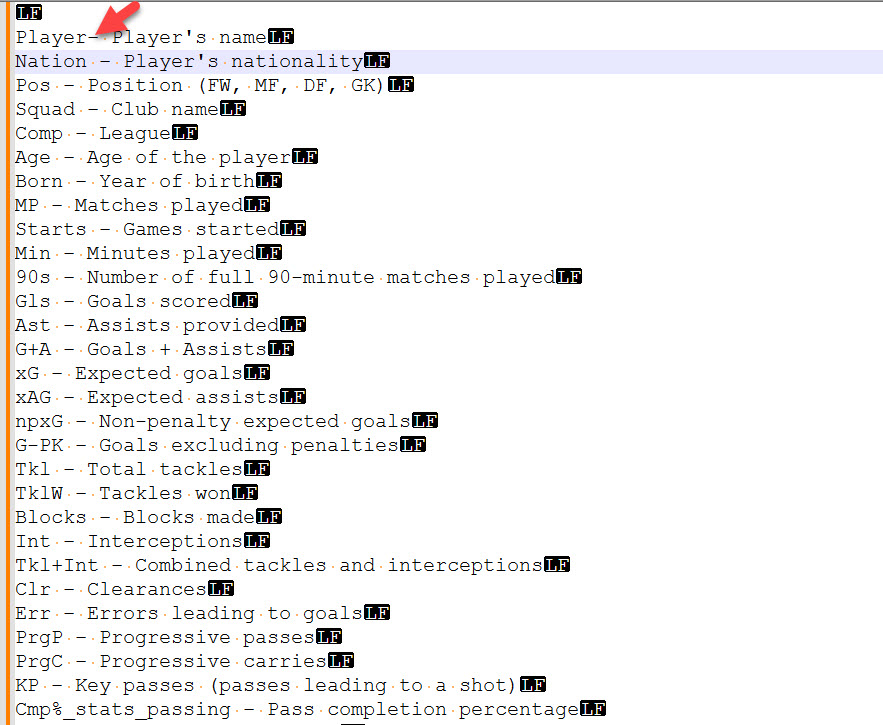
I wonder whether the file is also available and can be used as input data. Otherwise, I’ll use the existing file players_data-2024_2025.csv and filter out the non-relevant columns.
This is becoming extraordinarily frustrating. The metadata file is a text file with lots of extraneous junk. I cleaned it manually in Notepad++, but the hyphen/dash is (for me) indecipherable. I haven’t figured out a way to split the abbreviation and full description in the txt file. I’ve tried regex splitting on a hyphen and several types of dashes. Nothing works. Consequently, I haven’t been able to join the the csv file with abbreviations to the txt file with the full descriptions. I suppose I could proceed to the AI, but it would be nice to know what the data means without having to refer manually to the metadata.
Hello @rfeigel ,
Thanks for bringing up the concerns regarding the dataset. As the author of this challenge, I should have provided a more detailed description of the columns in the dataset; I apologize for this oversight.
Regarding the metadata.txt file, the challenge does not require its use; it is provided for understanding the meaning of the columns in the dataset.
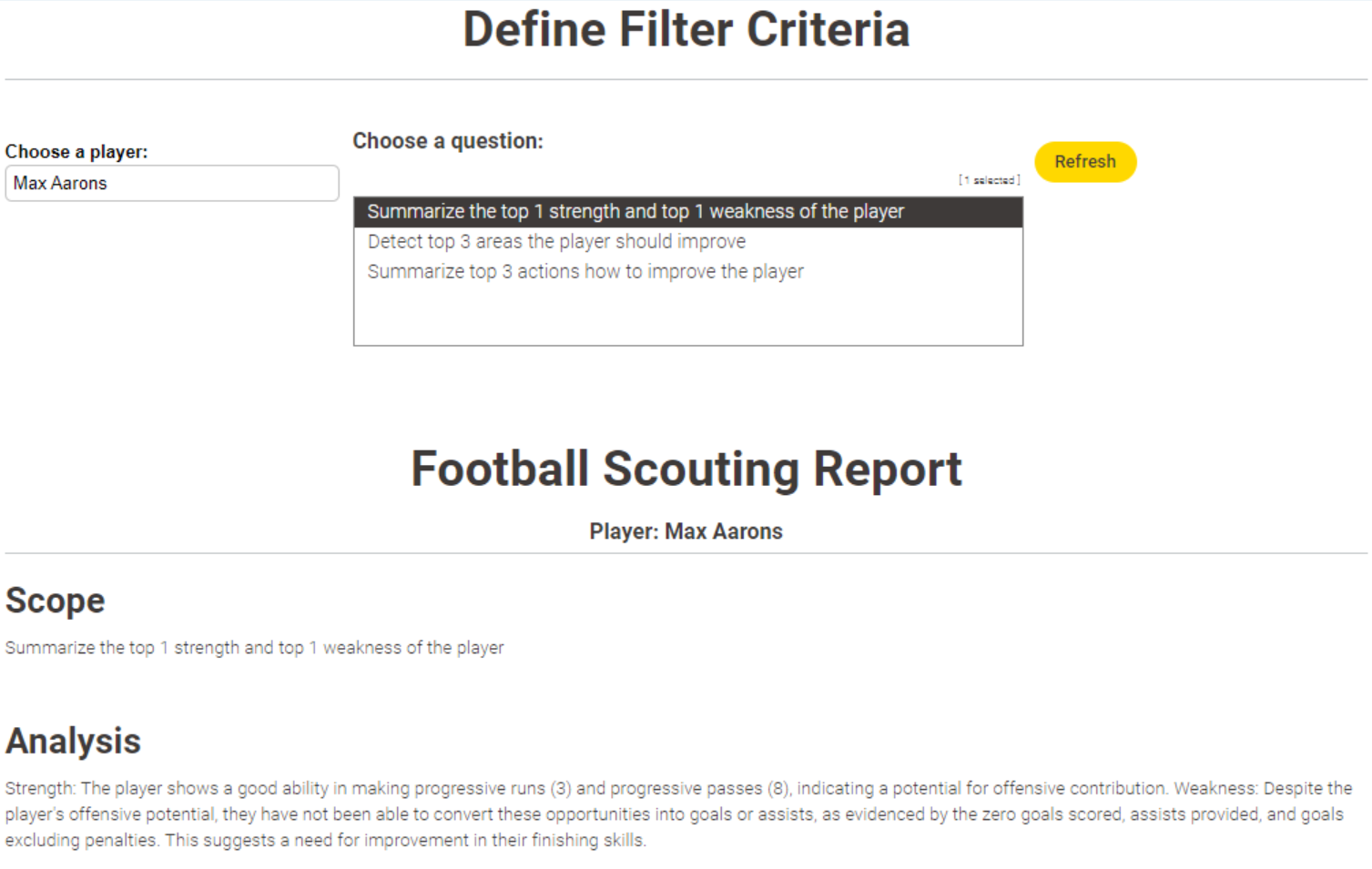
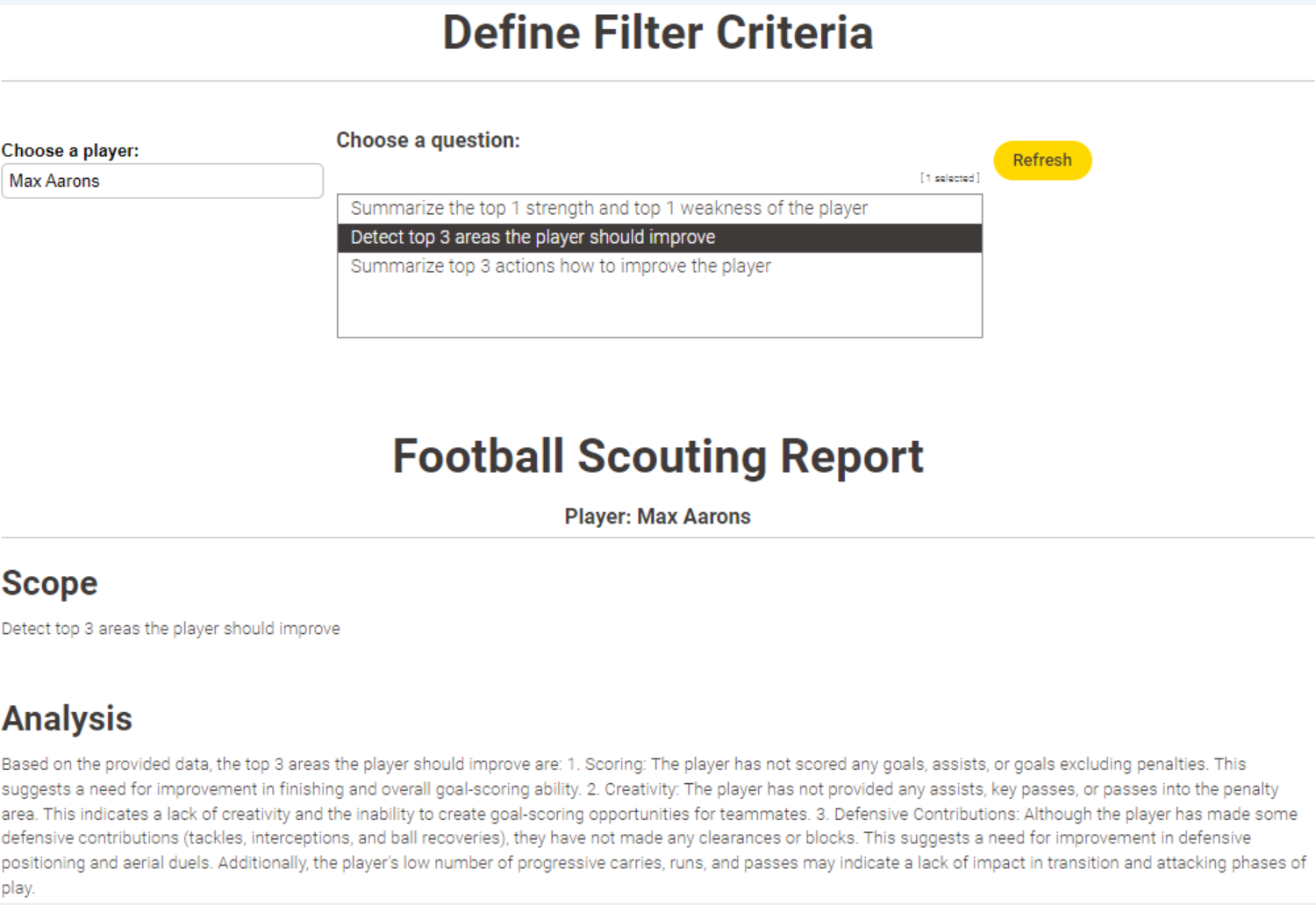
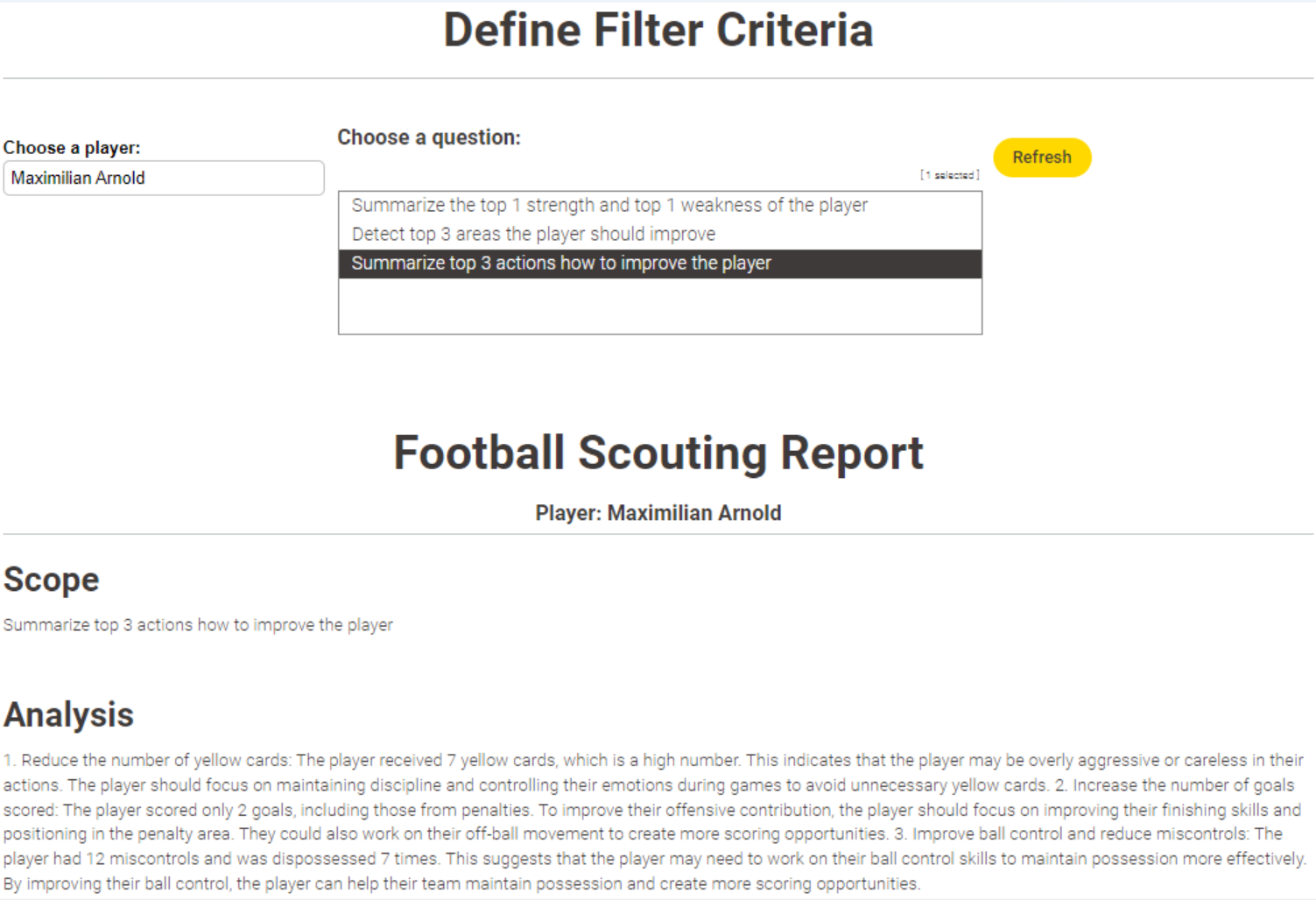
The goal of this challenge is to create various prompts and observe the results obtained from the LLMs for those prompts, and then compile a report.
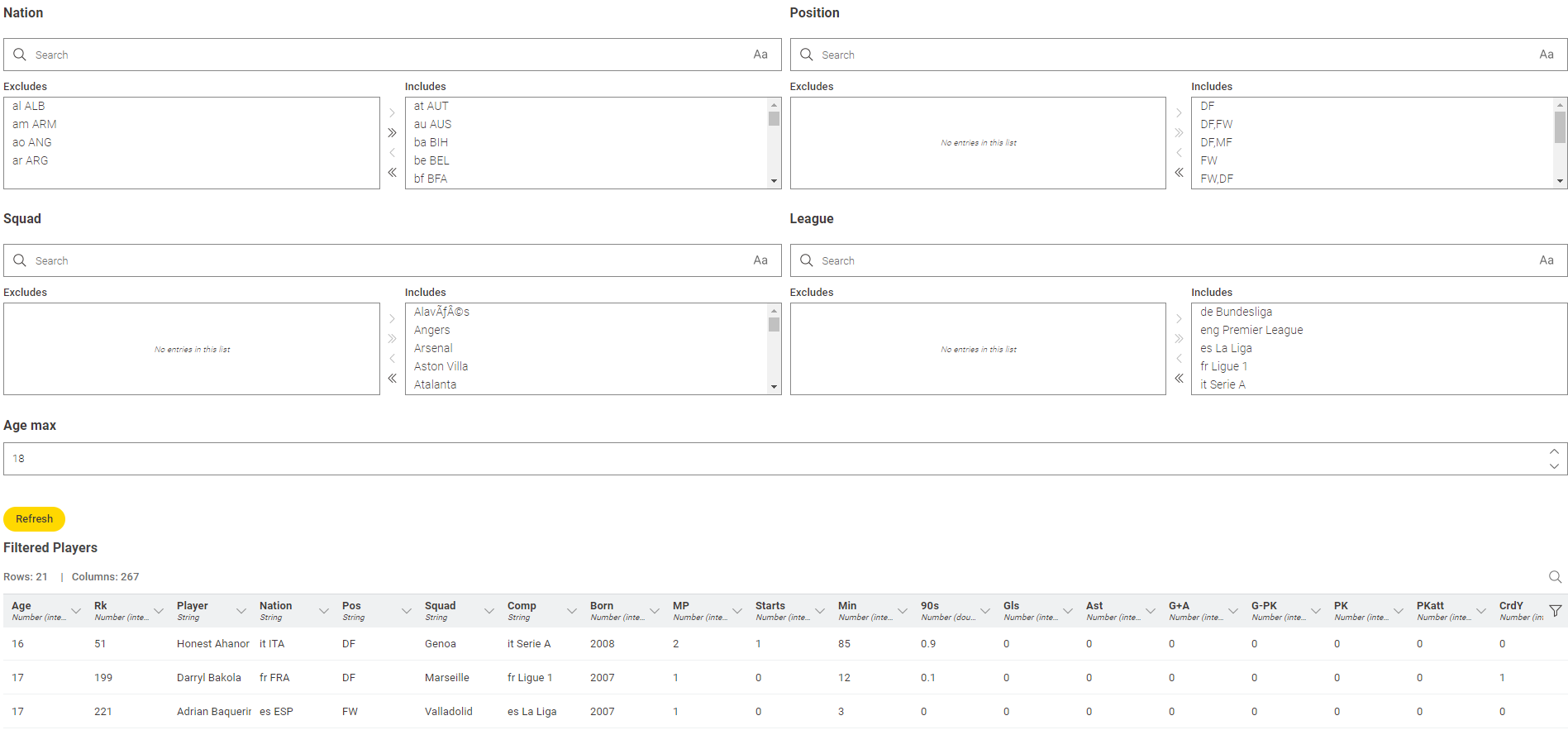
The challenge mentions that you want to recruit new, talented footballers, and you are in search of them. This means you can search for players in a specific country or league, and since you are looking for young footballers, the players’ ages are a consideration. These are the two things that you might want to focus on initially.
To simplify more, you can work with the columns that have a description in the metadata file and look for young players only with those attributes. Many columns in the dataset contain missing data, which can also be filtered.
I’m not really a football fan… but this KNIME challenge had me learning more about football than I ever expected!
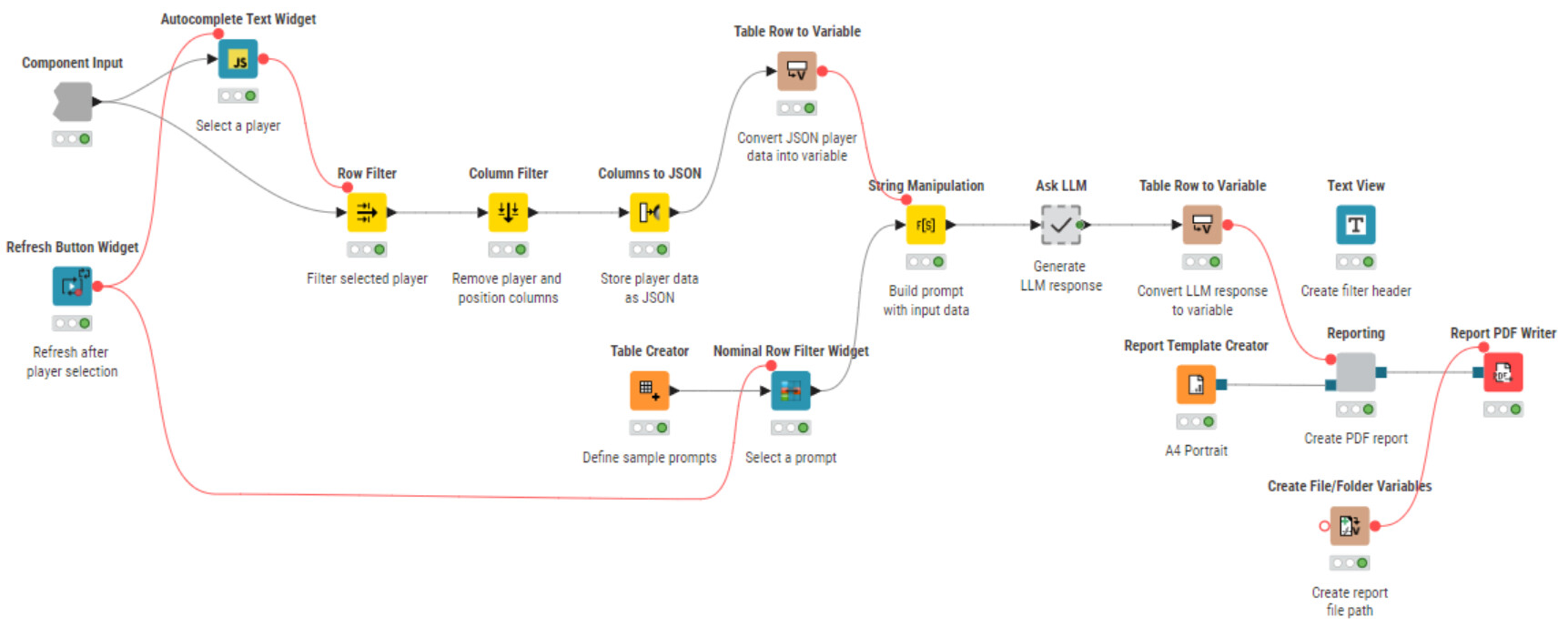
Just uploaded my solution for this week’s challenge on my hub— since I had zero clue who the players were, I decided to add their photos into the report. Gotta put a face to the stats, right?
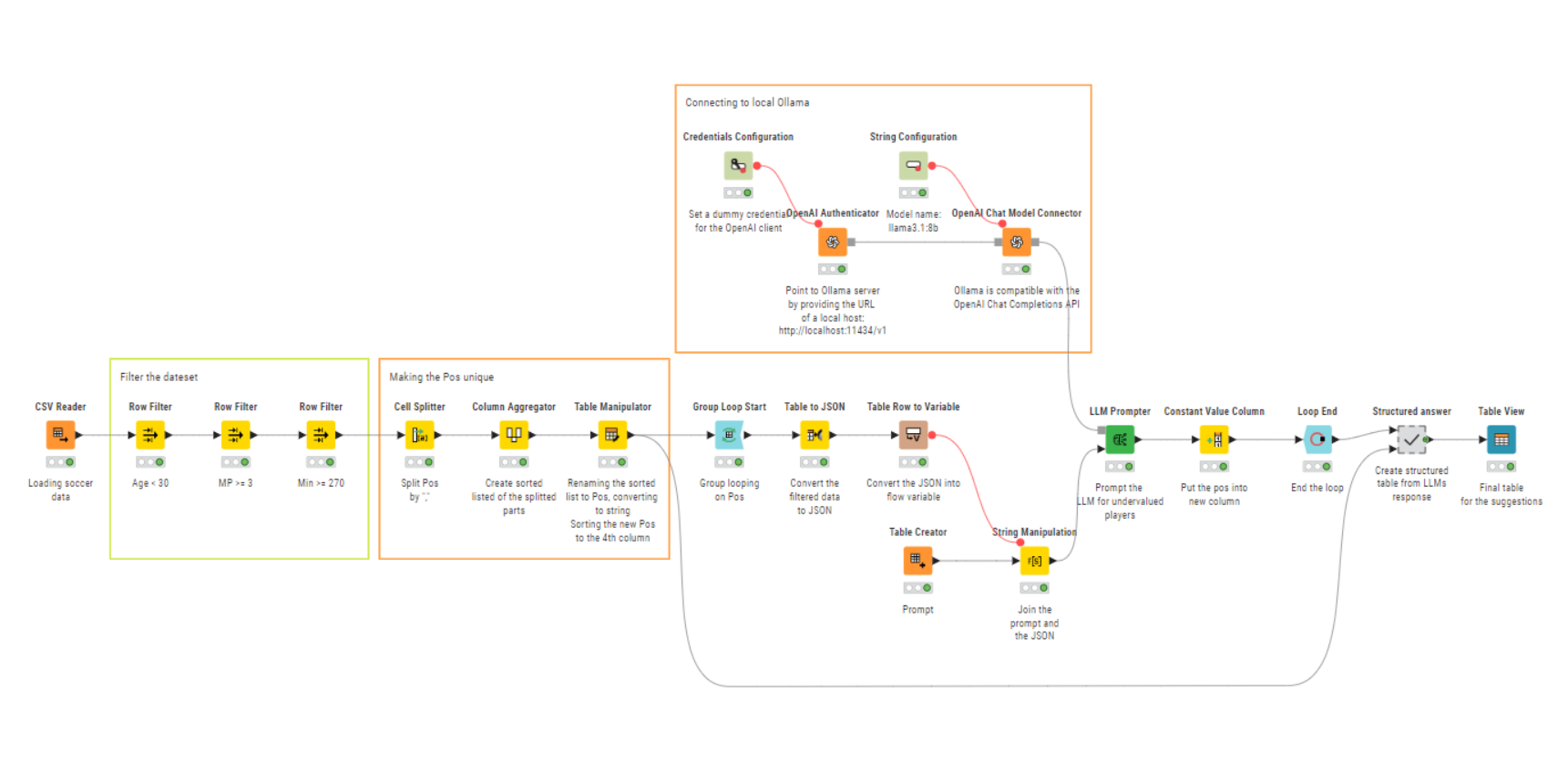
There were same positions in different order, I switched them (so MF,FW = FW,MF)
I connected KNIME to my Local lama LLM
I used group looping so I will have a suggestion for all the different positions
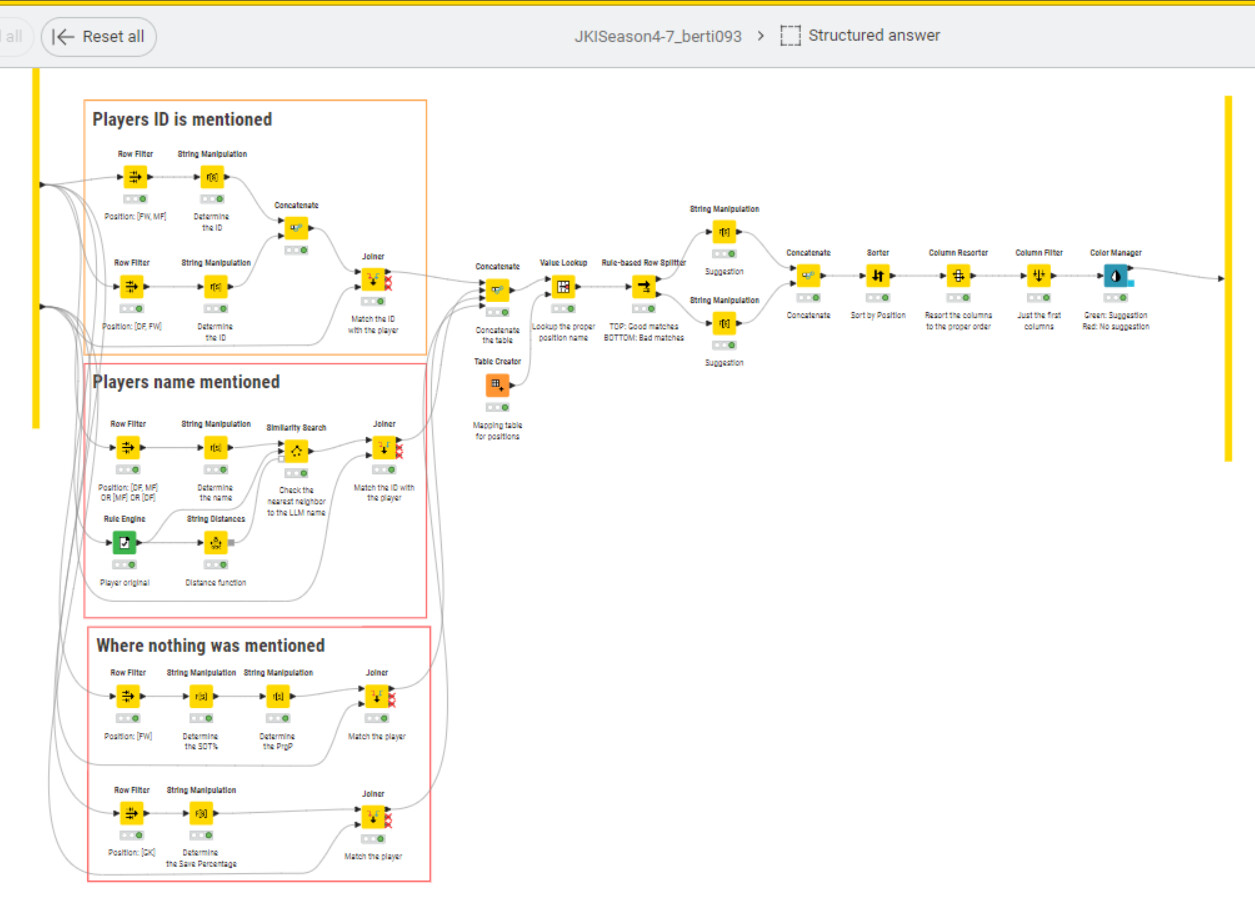
I tried to structure the LLM’s unstructured answer
So this is the methodology in a nutshell. The real challenges were:
The local LLM is real slow (with the JSON converted 200+ players and 200+ columns) so the whole workflow runs 4 hours (on my laptop)
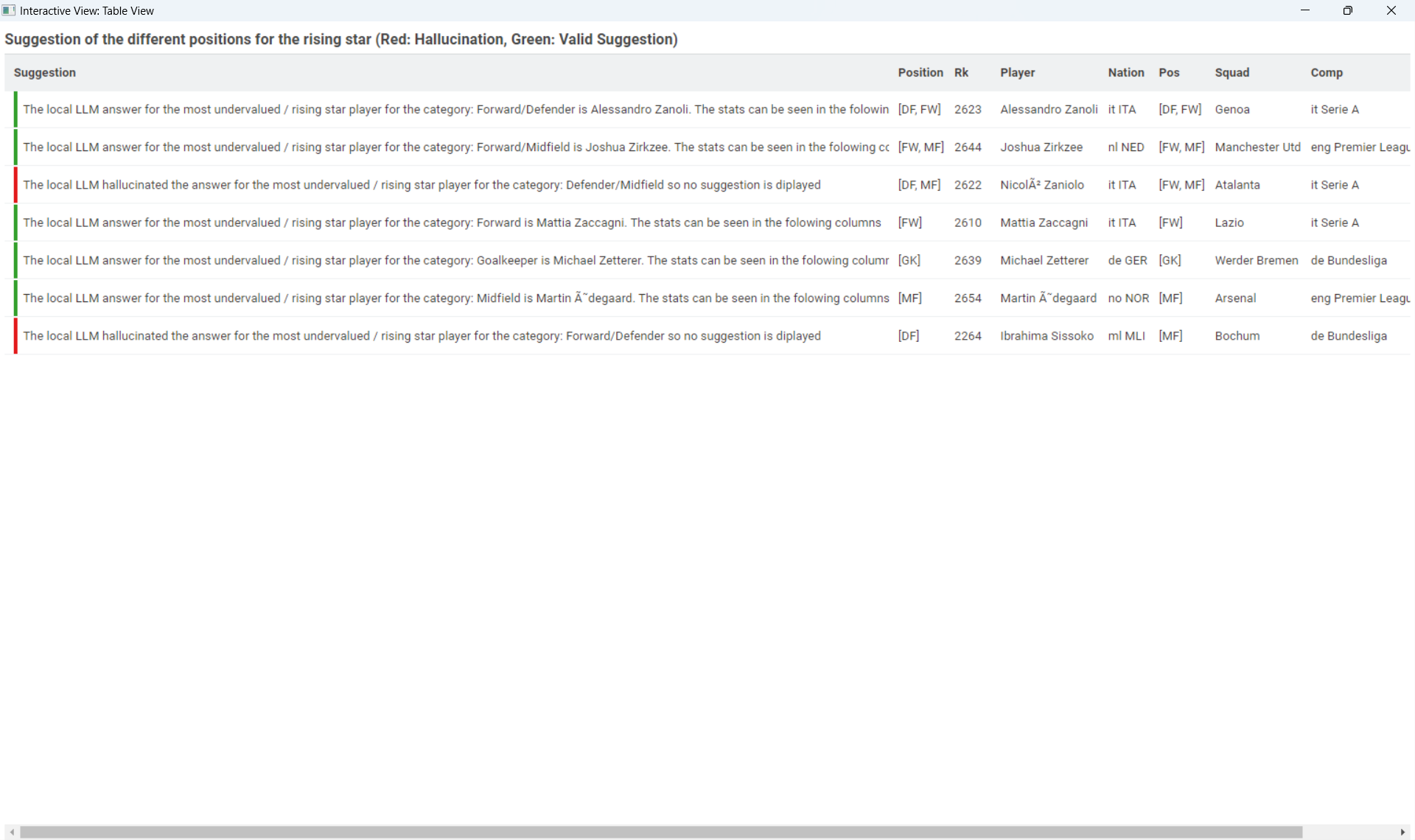
The LLM hallucinated for two positions (I highlighted it in the final table). Maybe it could be resolved with refining the prompt but with 4 hours runtime, it’s a little to much time testing (also I had to rerun the whole workflow one time, I pulled out my hair )
I’m not in football so I’m really not sure how “good” are the answers, so I would really love feedback from football analytics experts on the positional recommendations!
I’m using the free version of HuggingFace (with limited inference usage ).
To stay within the limit, the following steps were taken:
Only some relevant columns, as specified in metadata.txt, were retained
Duplicate rows were removed based on player names
I’ve tested various Hugging Face inference models, including bigscience/bloom, HuggingFaceH4/zephyr-7b-beta, and mistralai/Mistral-7B-Instruct-v0.3. Among these, the last one appears to run reliably without any error messages, unlike the first two, which occasionally return issues such as ‘model overloaded’ or HTTP 404 errors.
Thanks to all who posted before me for some great ideas on how to handle the challenge.
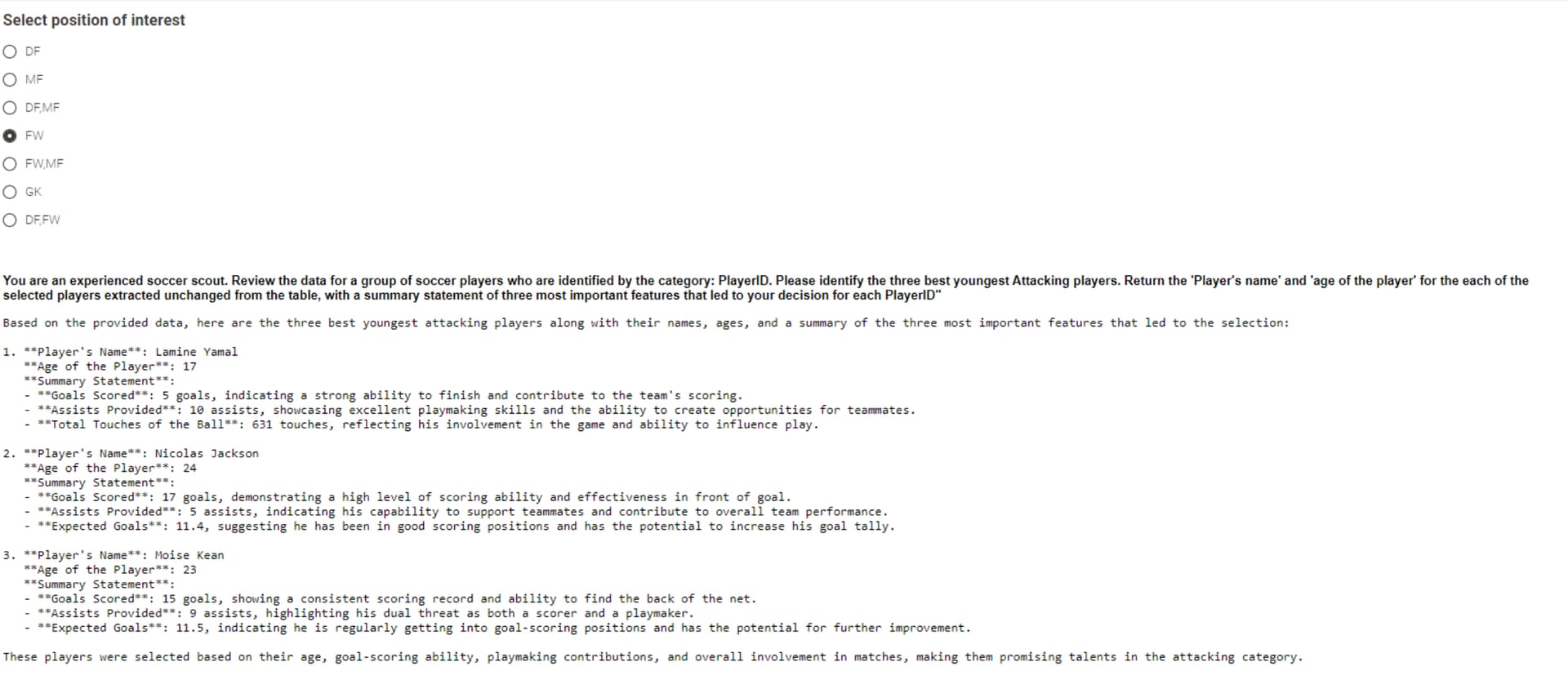
Wanted to see how the model would perform in picking the best young players for the different positions.
The tables I was sending originally to gpt were rejected - too many tokens, so used an intermediate pareto ranking for the different positions to narrow to the best candidates for the model to work on.
Discipline Index (“Paolo Montero” style for those who remember about him) to spotlight the most tenacious tacklers (and their occasional over-zealous fouls).
Global Performance KPI + percentiles on both KPI and Minutes Played to normalize across positions and workloads.