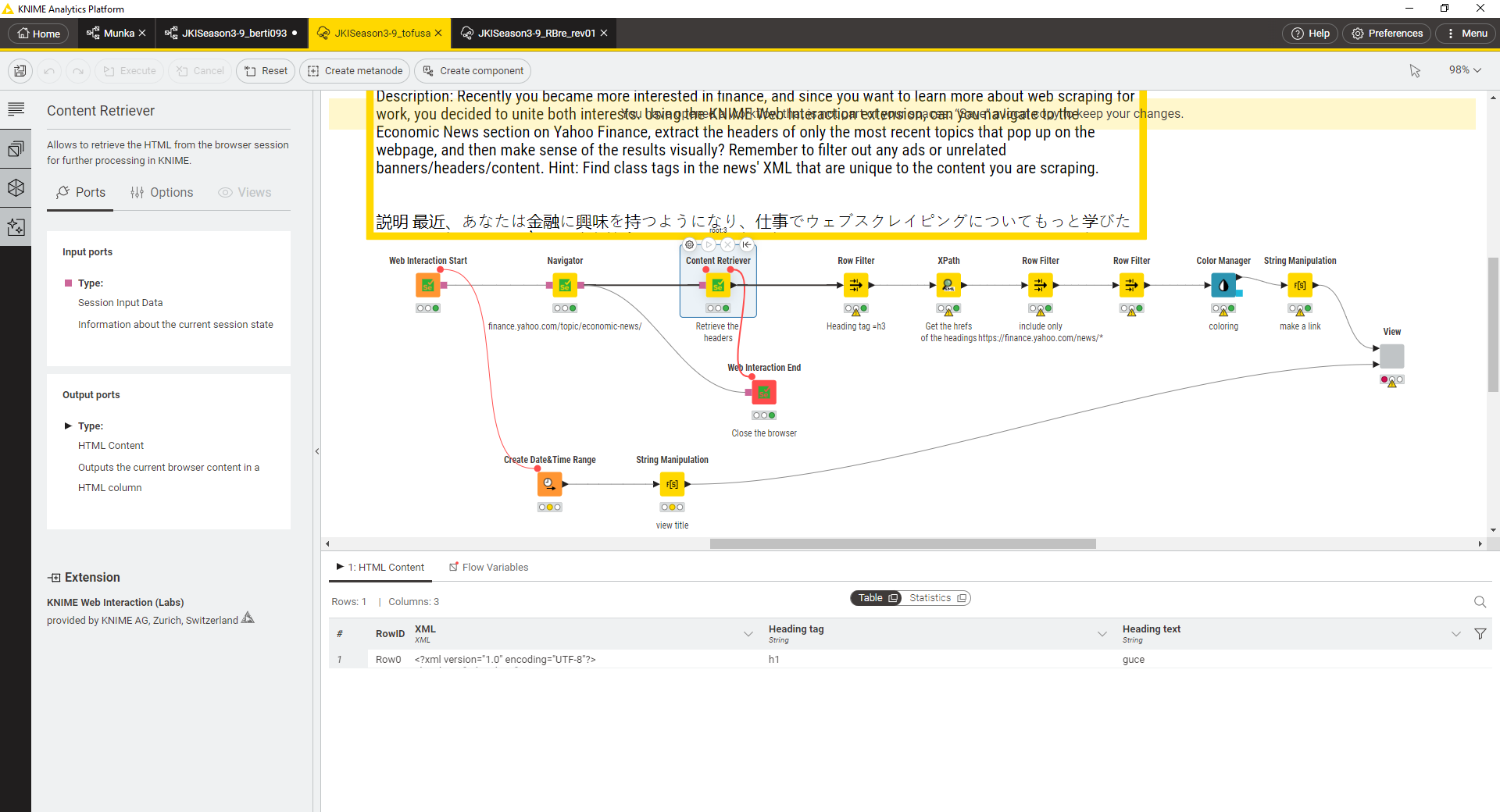
We just posted a new Just KNIME It! challenge! You’re more interested in finance these days, and also want to learn more about web scraping for work . Why not unite both interests and web scrape finance news with KNIME?
Here is the challenge. Let’s use this thread to post our solutions to it, which should be uploaded to your public KNIME Hub spaces with tag JKISeason3-9.
Need help with tags? To add tag JKISeason3-9 to your workflow, go to the description panel in KNIME Analytics Platform, click the pencil to edit it, and you will see the option for adding tags right there. Let us know if you have any problems!
Hello, here is my solution for this challenge.
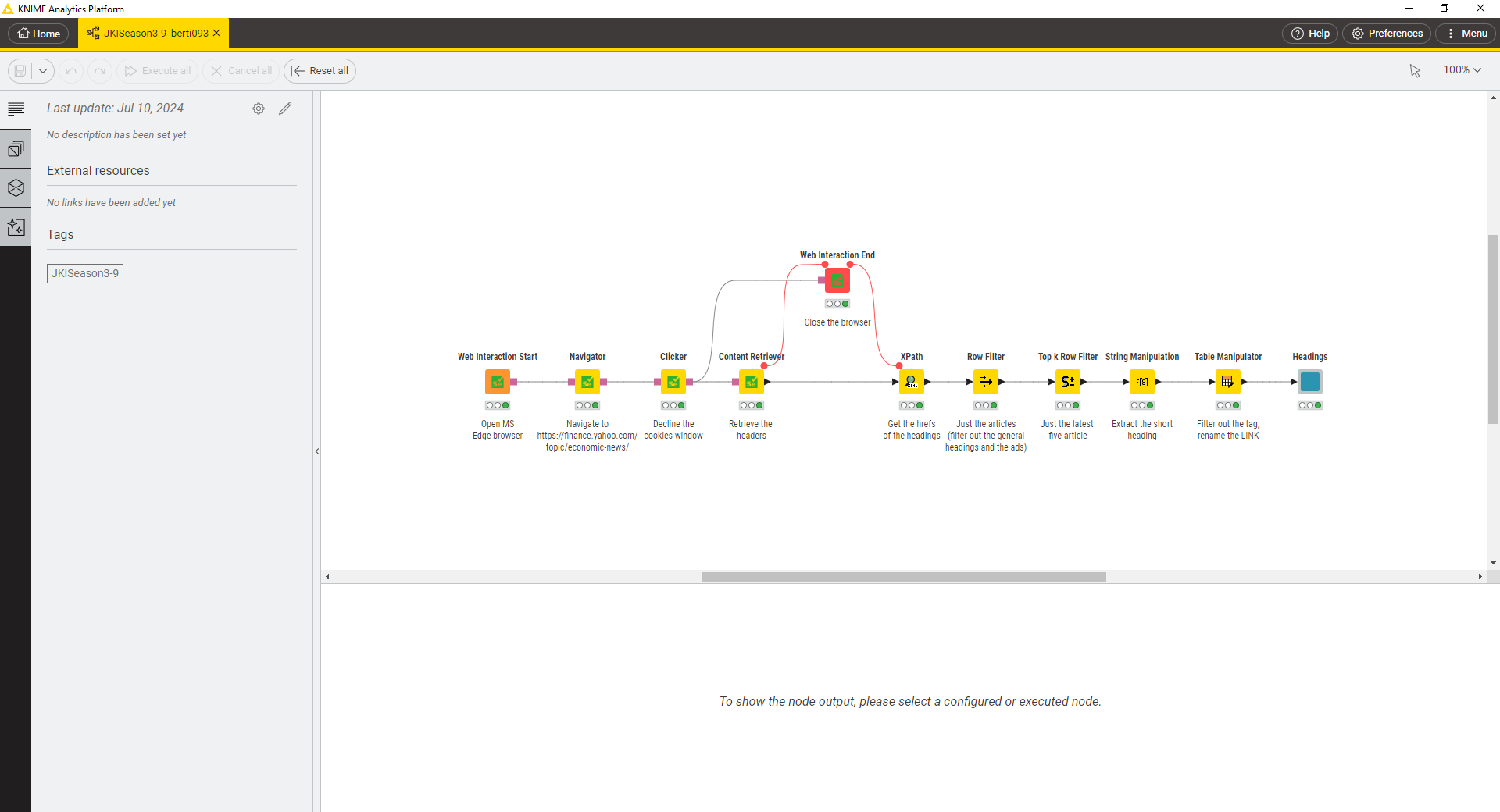
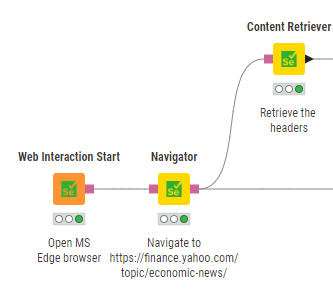
I used web interaction for the first time and I like it!
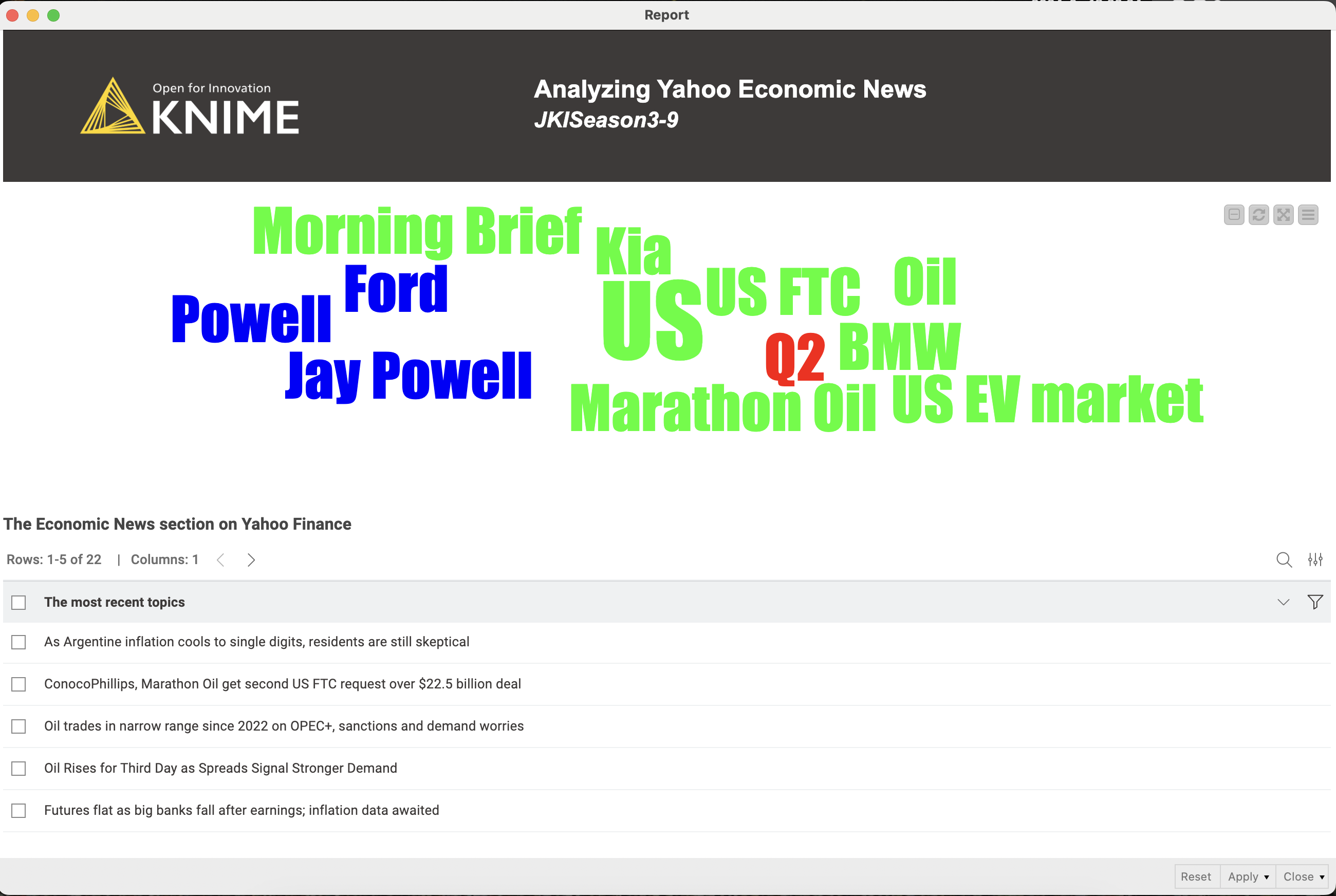
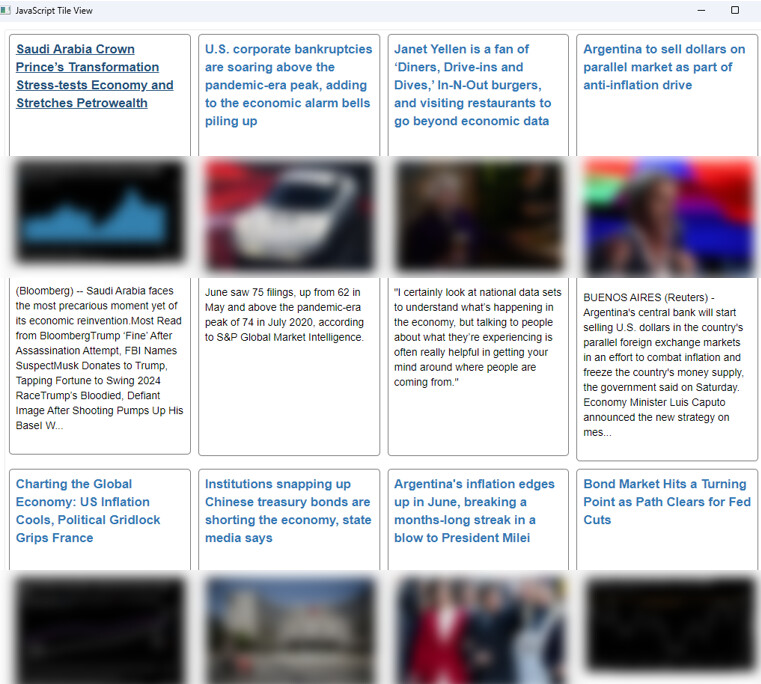
I filtered two words (AI and NVIDIA) for example.
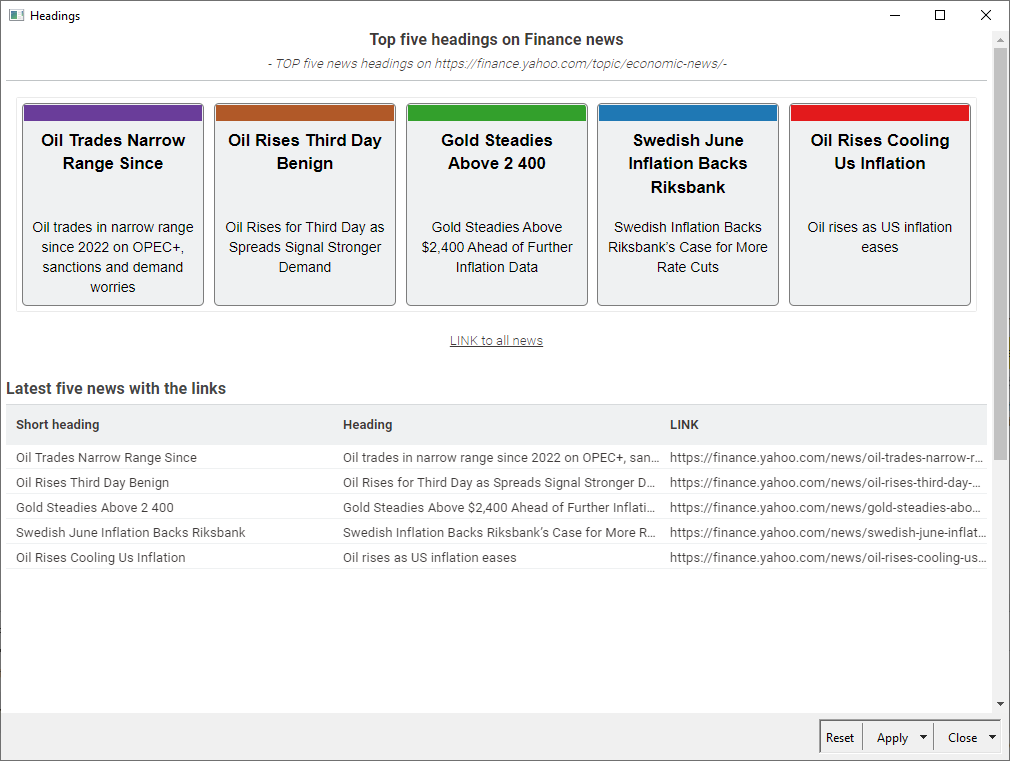
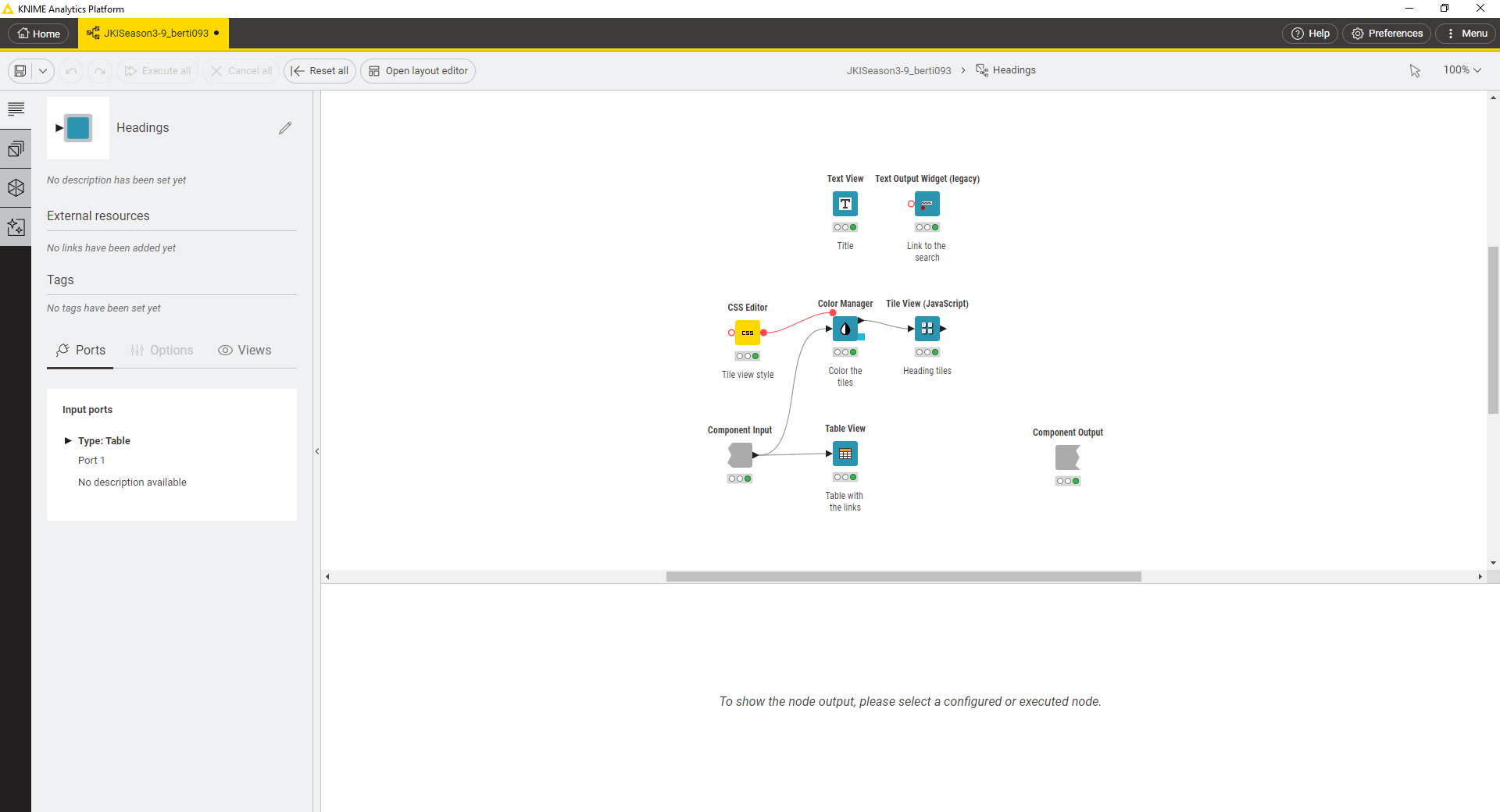
Relevant articles are displayed in a Table View with clickable links.
All articles are stored in an excel file for later access.
Depending on screen resolution or zoom in firefox an additional button (scroll-down-btn) needs to be clicked.
Yesterday I had to click (here) as site did not reload automatic but not today so i skipped that clicker.
Tried your rev 1. Still get same error after executing second clicker. Does the choice of browser mean the one I’m using on my local machine? I’m using Chrome. I selected it and still get same error.
My solution to the challenge. I have to say these nodes makes web scraping so much easier… I wrote selenium code in python. This visual framework is so much better and much more understandable.
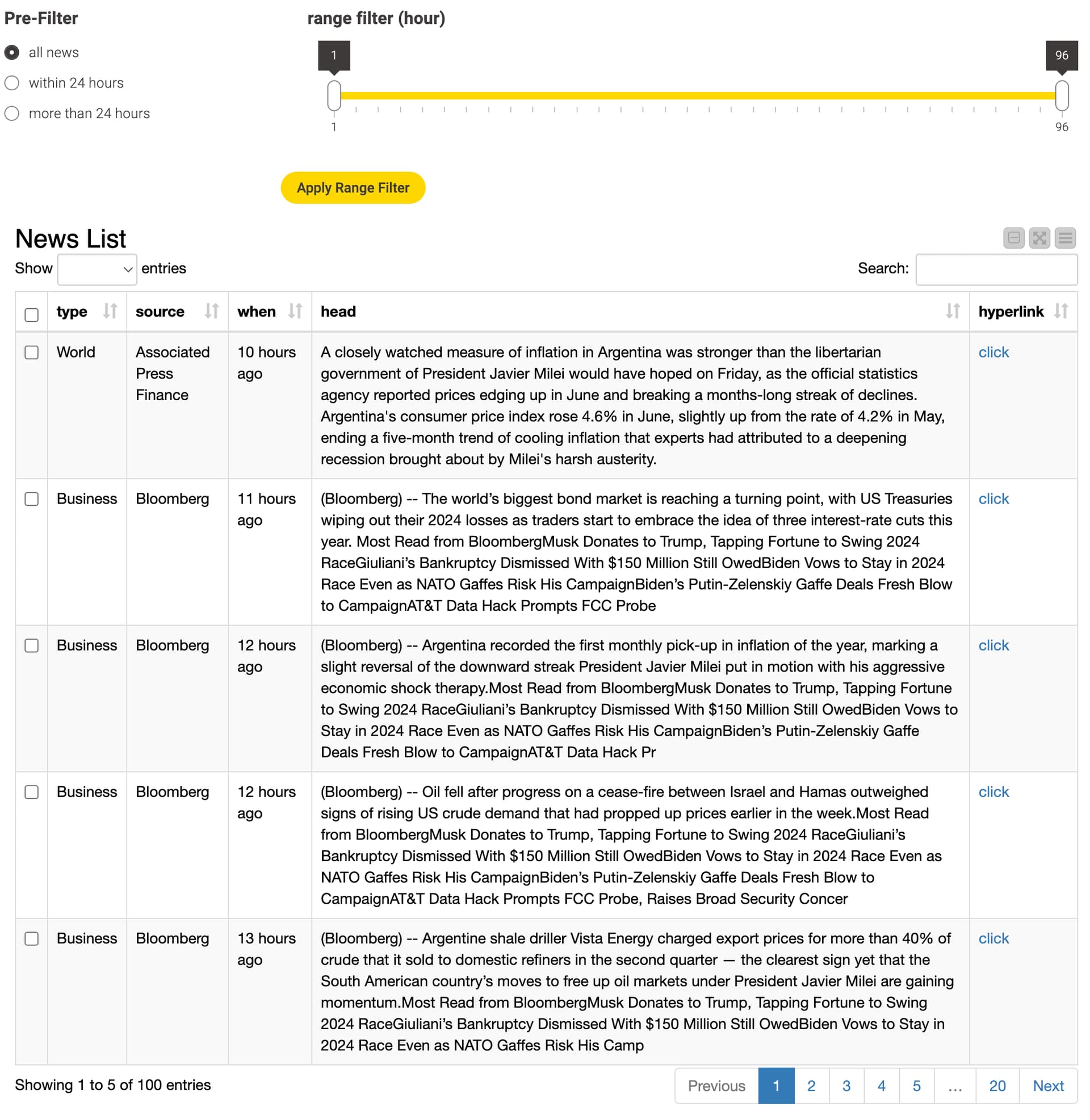
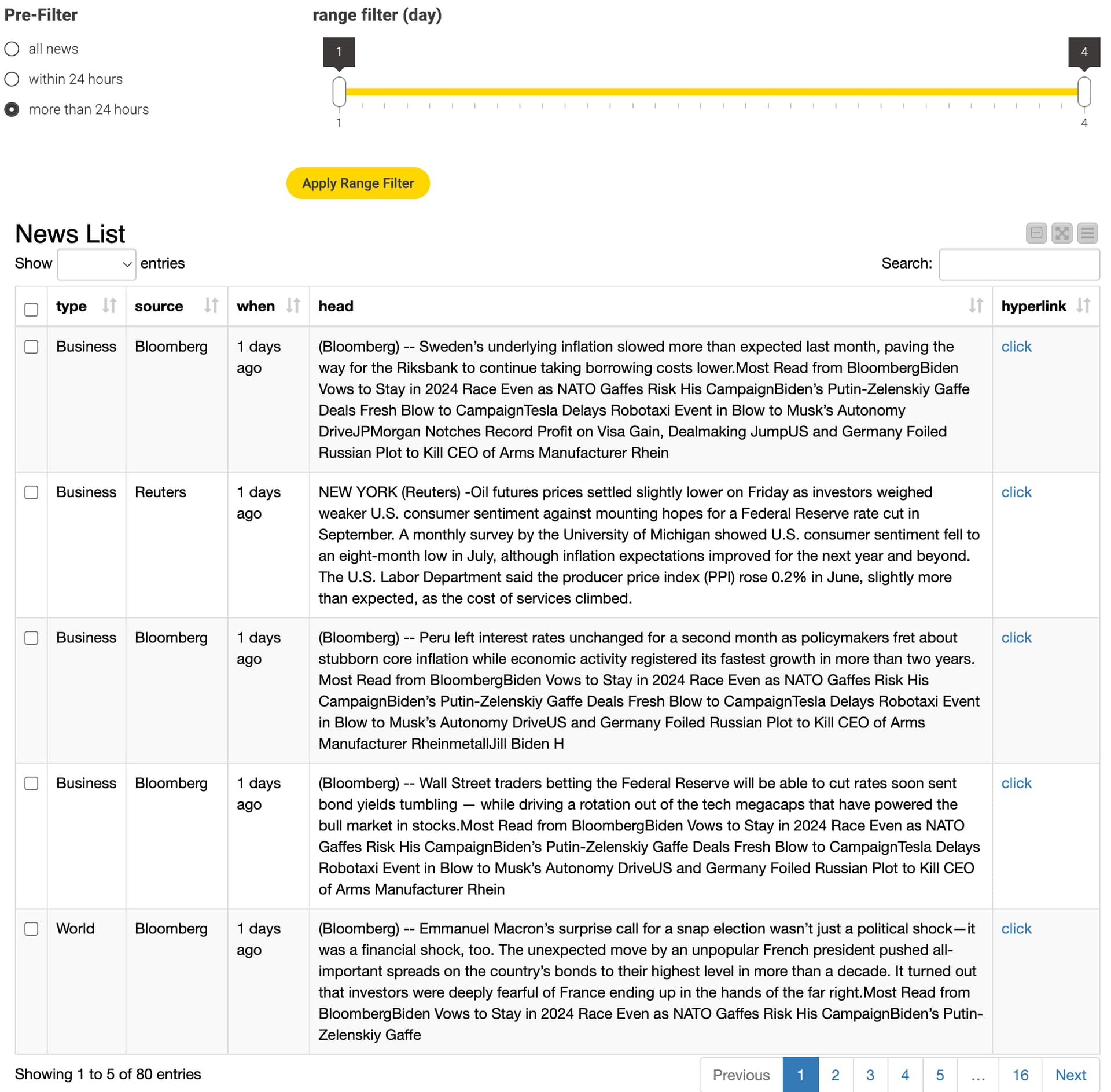
I have created an interactive dashboard with a range filter.
If you select “more than 24 hours” in the pre-filter section, the unit of the range filter will change from hours to days.
Additionally, you can access the original news page by clicking on the hyperlink.
Hello JKIers,
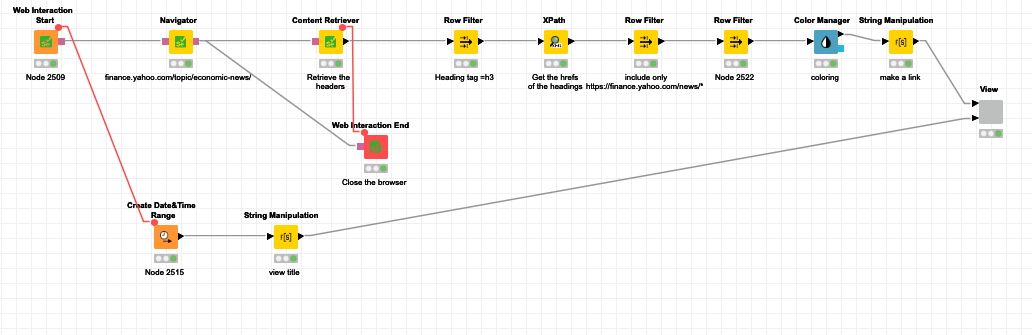
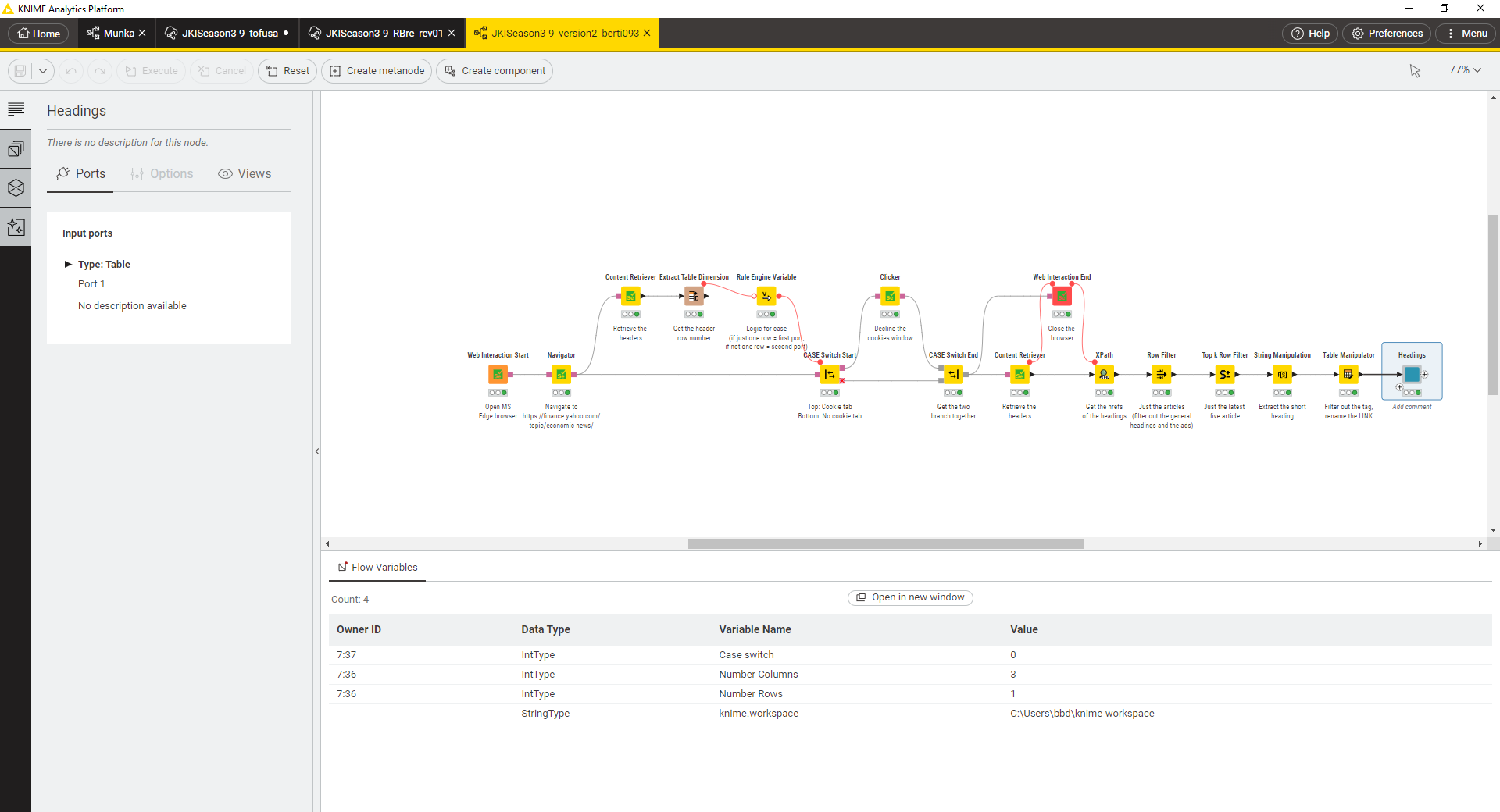
This is my take to the challenge, strongly inspired on my previous colleagues’ submits. So thx a lot for the lessons, I’ve tried to tag the main insight owners within the node labels.
My main contribution in the workflow, it has been the image capturing; since I’ve used the ‘Image Processing’ extension’s nodes, as I learned from JKI S03 CH07, capturing the images from images’ URL
Thank you to the KNIME team for these interesting challenges. They allow me to familiarize with new node extensions and data processing.
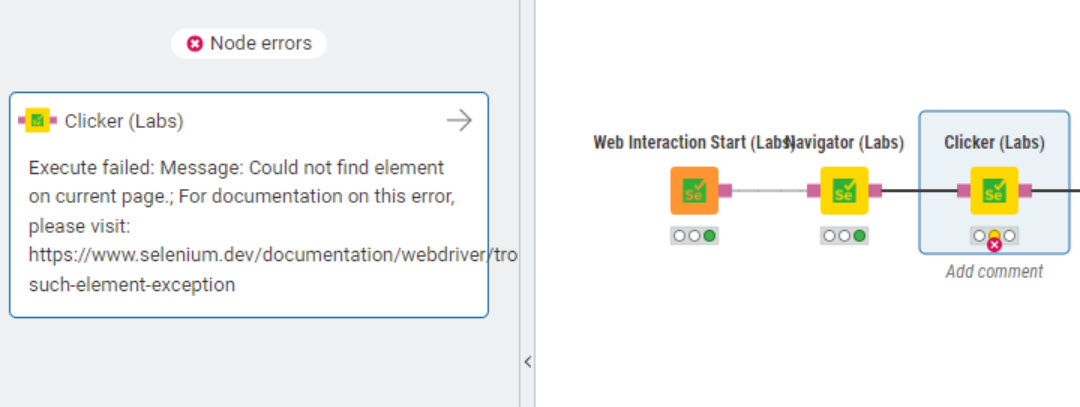
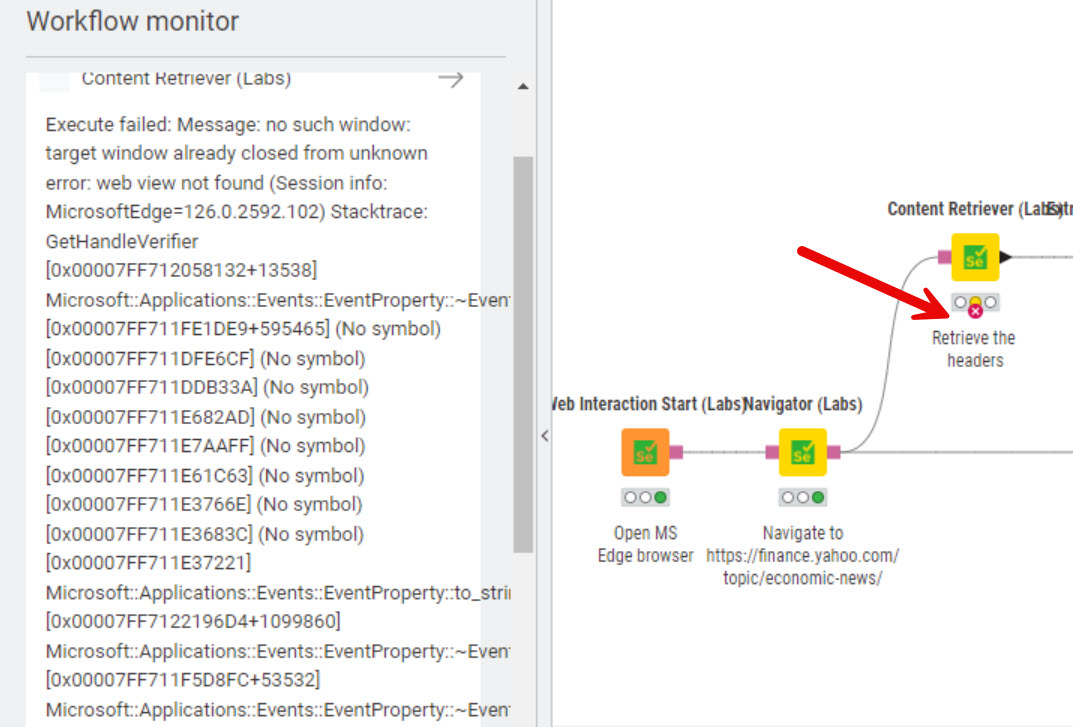
I’ve downloaded most of the challenge solutions. Any workflow that includes a Clicker node fails on a reset. @Tofusa and @sryu’s work fine on a reset and don’t include Clicker nodes. See my earlier post for the error message.
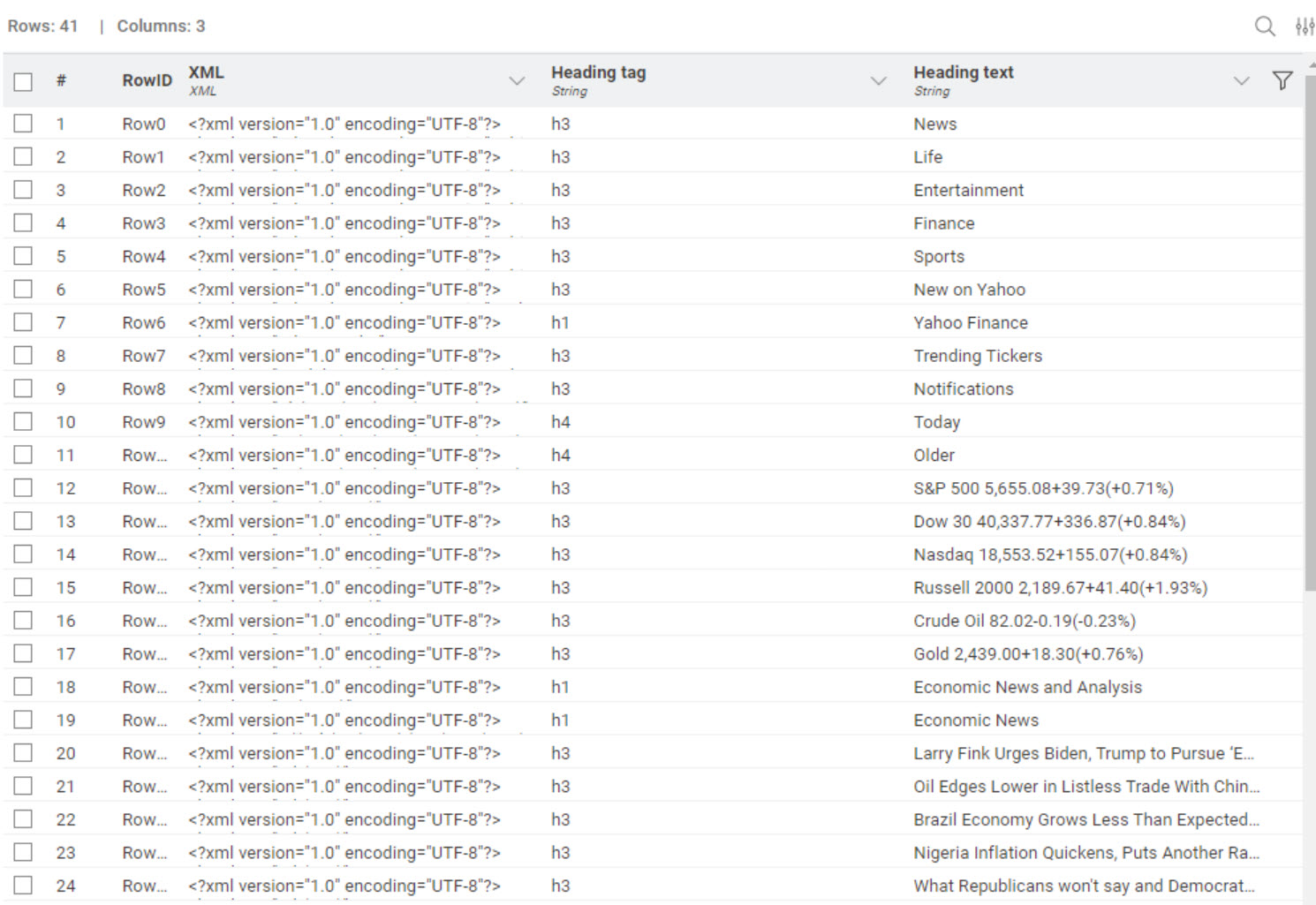
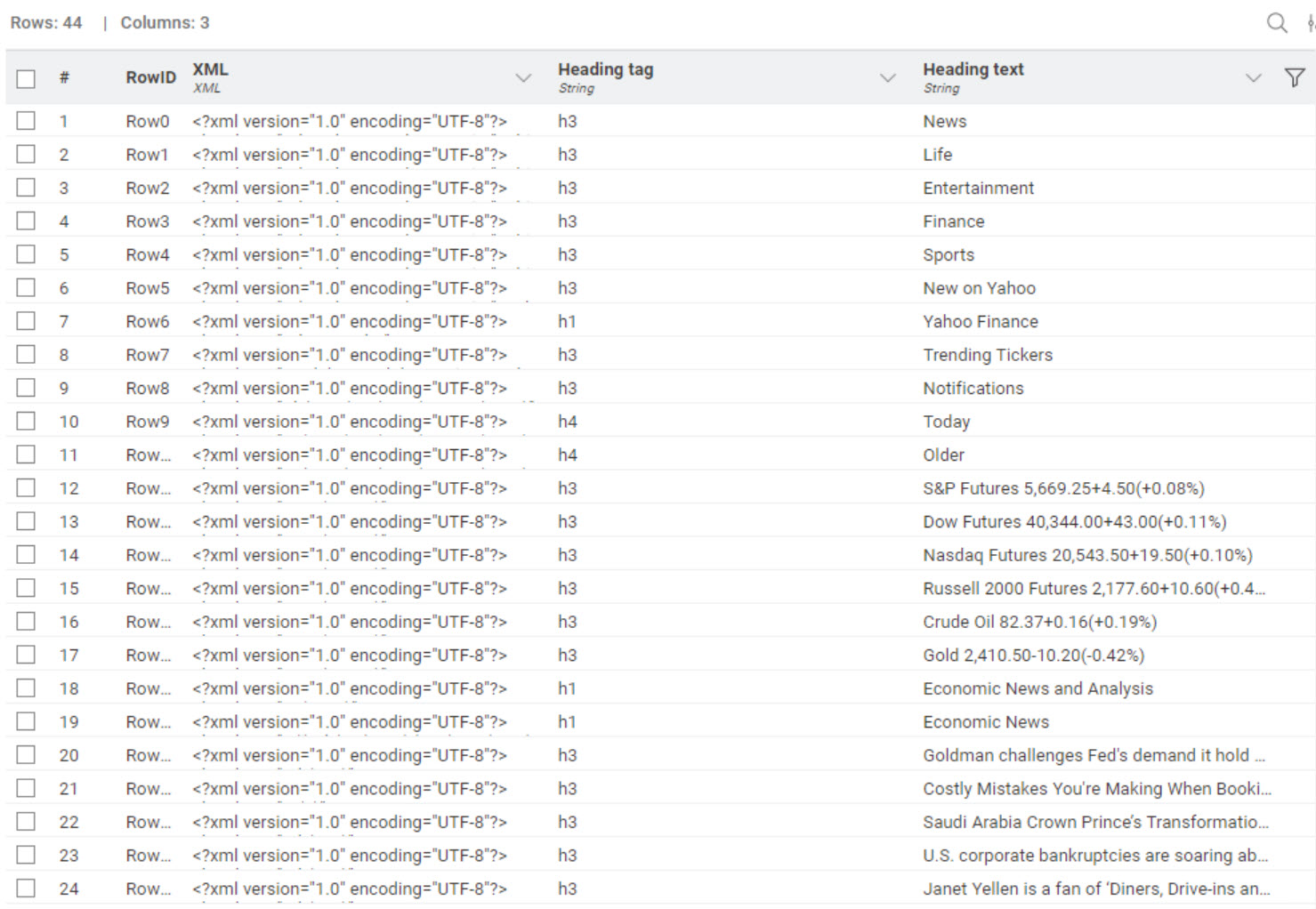
Sadly without the clicker it just gets for me one header row, the h1. I tried to run @Tofusa’s solution but just one row was retrieved with the content retriever, so the workflow is “empty”.
Can it be the problem that the “do you accept or reject cookies” tab doesn’t come for everybody? And it generates the error, as tofusa, sryu and rfeigel has the cookies “turned off” and the others do not have that turned off (maybe regional setting, or some configuration in the browser)? For me the link I give to the navigator gets this:
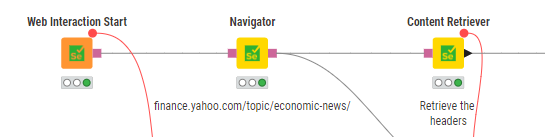
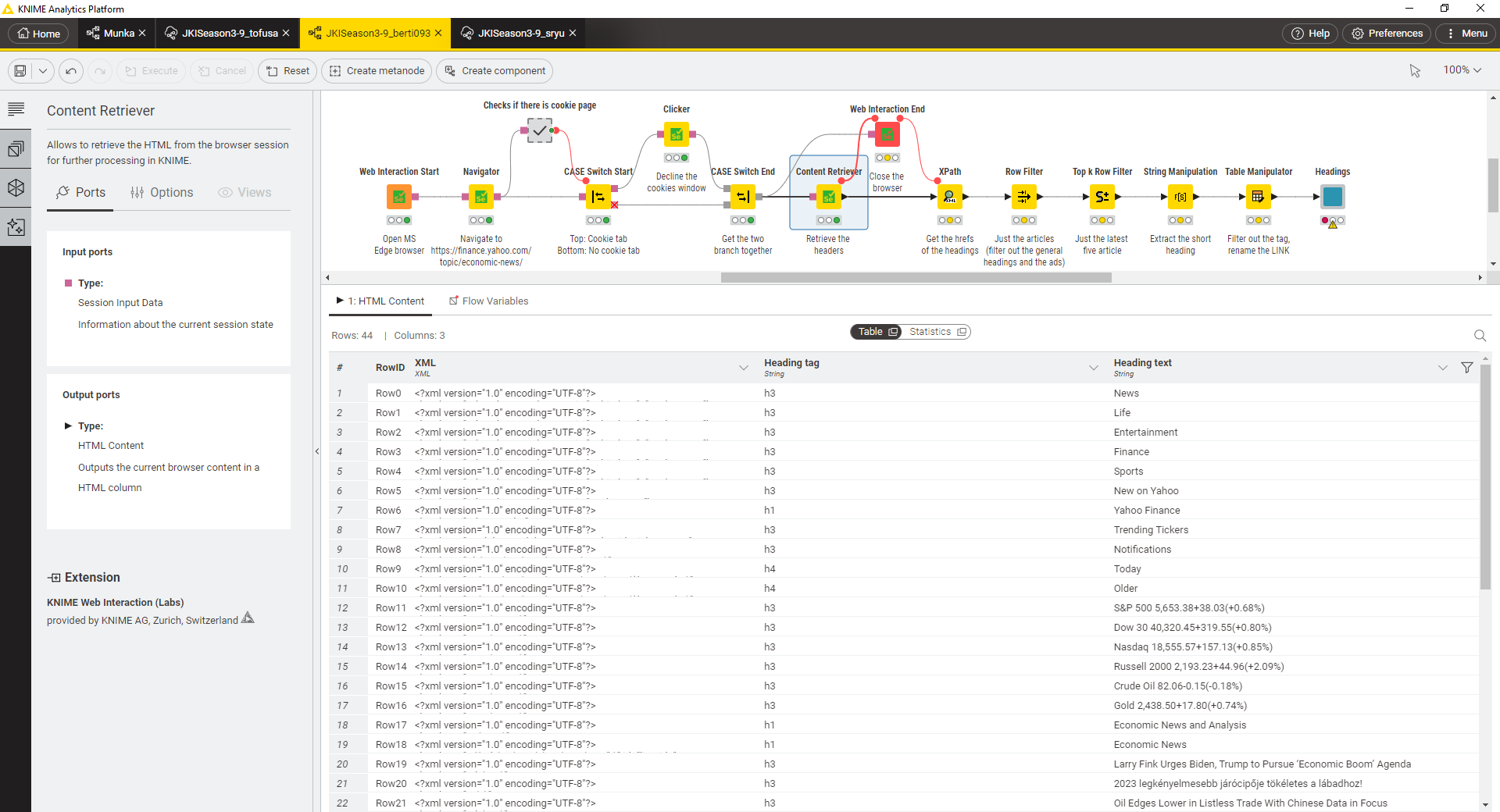
I updated my workflow. For me it runs fine. It checks if the first retriever retrieves the “cookie page” and run the clicker node if there is cookie page. Could you please test @rfeigel if it runs fine in your environment? (It’s not optimized yet as I just test now)
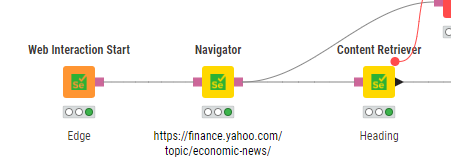
I do not understand how can it be, as you said that sryu’s and tofusa’s solution was worked for you and they have the same sequence as me. (sryu’s solution contains Edge browser just like my solution, the configuration of these three nodes are totally the same)
Sryu:
Tofusa:
Mine:
Could you help what is the output of the other two solution’s content retriever node @rfeigel ?
I just do not understand how can it be, that the nodes are perfectly the same (first three nodes) and it works in the other two solution but not in mine.
As a last resort I tried to handle it from selenium side. I added a command line argument: --disable-extensions. In theory it disables every extension in your browser (I say in theory as I didn’t tried it in KNIME just in Selenium).
I updated my workflow. Hope this command line solves the issue, I do not have more idea, it should be tested in different environments
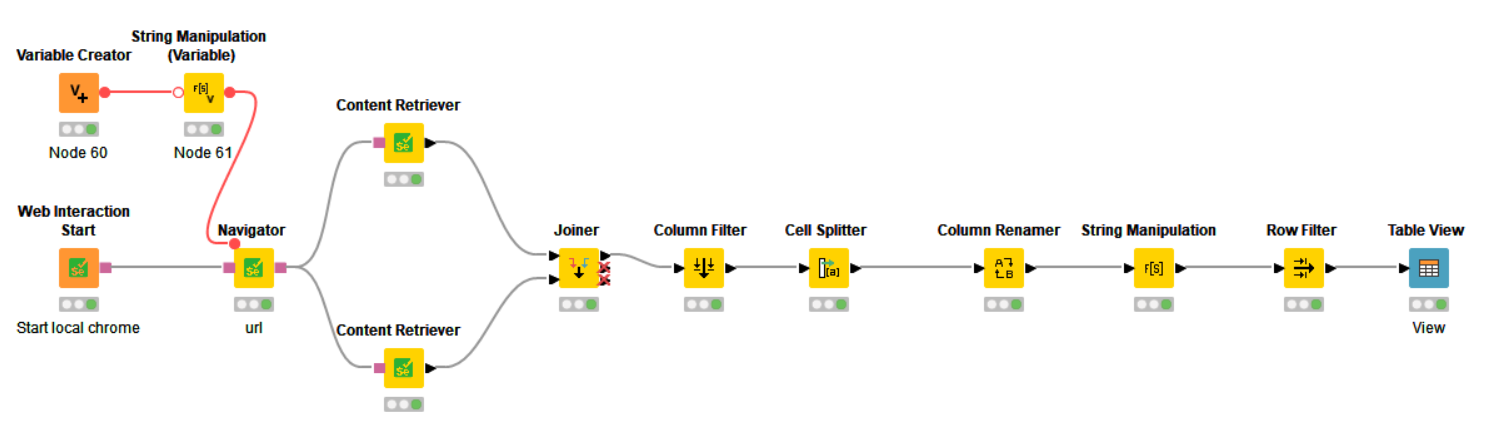
Little bit late to the party, but here is my solution. I kept it simple and extracted the titles visible on the first page after getting rid of the cookie notice. Worked out a way to filter those rows that were ads and then showed the titles in a table view.
As this extension is still fairly new and I have used it a few times I experimented with recording whilst building the solution to also share on how one can find which classes, ids etc. to search for:
Let me know your thoughts :-).
On the issue @rfeigel has: My experience with Selenium is that sometimes it’s just acting up - can already happen if someone is “just” using a different browser, but I also had the odd experience where the initial browser window is still open, I add a clicker / retriever / navigator / whatever node for a next step and it triggers opening an entirely new window… guess there might be a reason it’s still a “Labs” extension.