This thread is for posting solutions to “Just KNIME It!” Challenge 9. Feel free to link your solution from KNIME Hub as well!
2 Likes
Hello KNIMErs,
here is my solution: justknimeit-9 - Raffaello Barri – KNIME Hub
I removed attributes Name and photo and kept the others. Also, I noticed column BodyType containes some names as well, some cleaning was necessary.
I made it with 8 nodes.
RB
3 Likes
Here’s my solution:
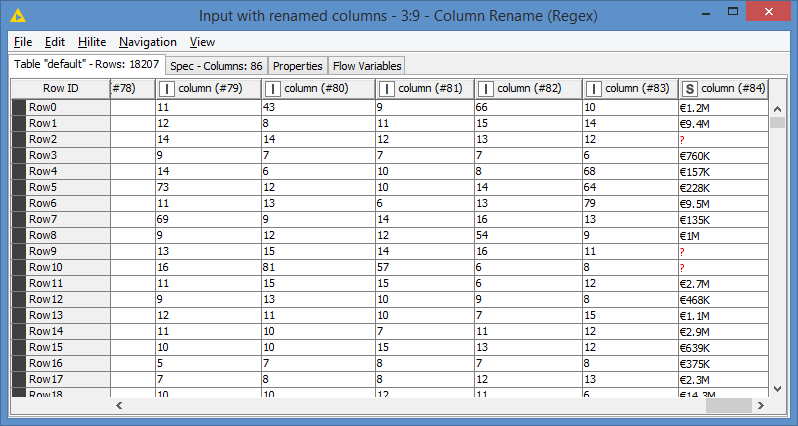
For the PII data (Personal Identifier Information), I have chosen to remove the Name, Photo and Body Type. The Body Type is “debatable”, but it does have names in it. Since privacy is a concern, it’s safer to not include the Body Type in my opinion.
I also made sure that the “column0” is not shuffled, exactly as how the “Row” column was left intact in the example of the request. The rest of the columns are shuffled, and renamed as “column”, “column (#1)”, …, “column (#84)”, exactly as per the requirements.
Results:

3 Likes
Hey folks,
So here is my personal solution to the challenge! ![]()
One thing that is worth noticing is that what is considered sensitive depends a bit on domain knowledge. People who know a lot about soccer ![]() may be able to de-anonymize the information and get to the names of the players by crossing value, body type, and jersey number for example.
may be able to de-anonymize the information and get to the names of the players by crossing value, body type, and jersey number for example.
I know that even if these columns remain in the data, they get randomized in the end – which makes de-anonymization harder but certainly not impossible depending on how much computational power and domain knowledge one has.
Since I’m Brazilian and know quite a bit about soccer (hehehe), I was more aggressive in the column filtering. ![]() Here’s my solution!
Here’s my solution!
3 Likes
here’s my solution
I went a bit overboard.
I wanted to keep full granulation in dataset still honoring the wishes of masking data. I started by parsing strings that looks like numbers or date e.g. height, weights, wages, etc. then masked all strings. Next I shuffled all rows per column and finally masked the headers.
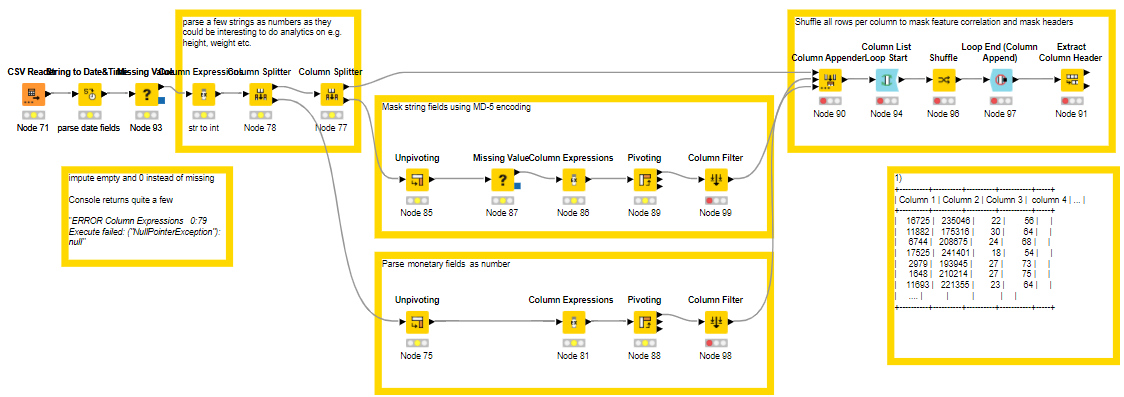
cheers
3 Likes
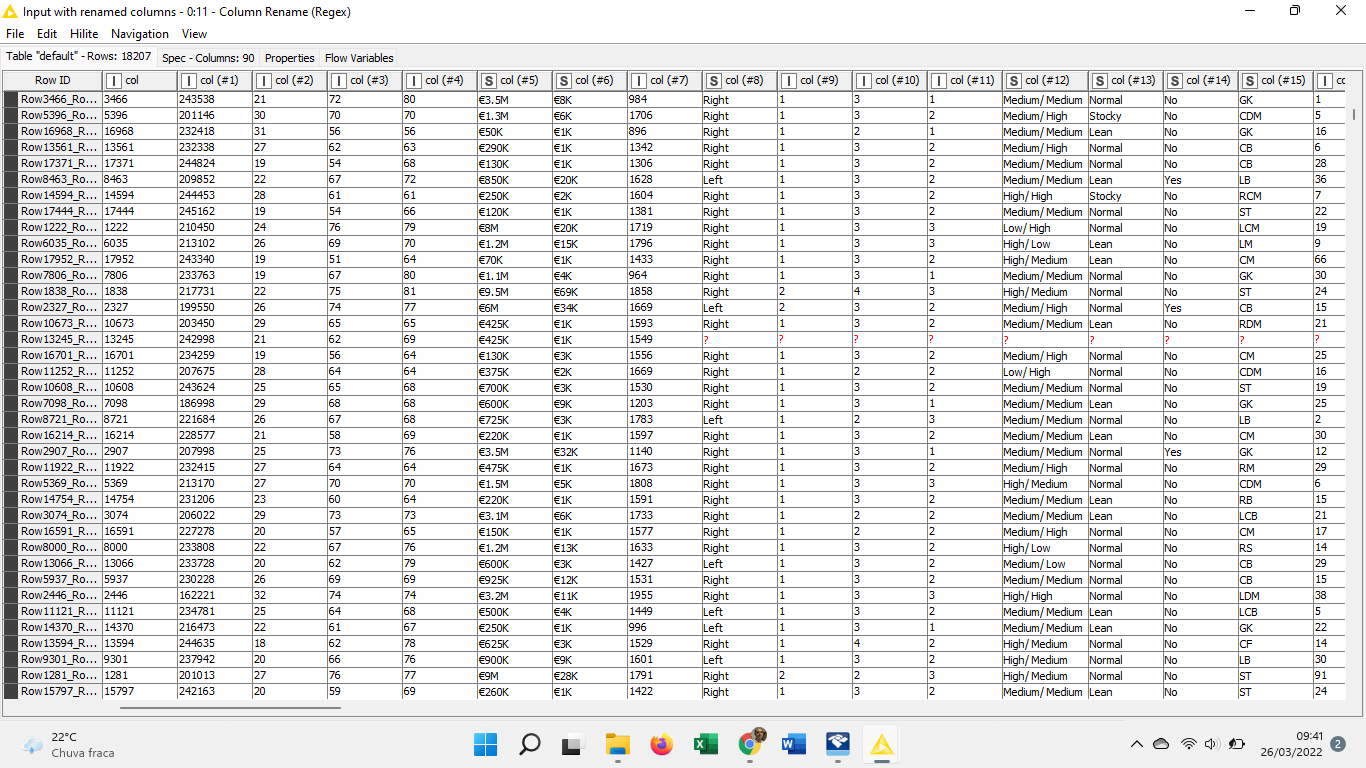
Hi, this is my first challenge and i tried to understand the challenge’s spirit. My solucition was simple and i’d like to be in the right way. Thanks for charing your ideas. This is help me a lot in my knime learning journey
2 Likes
Here’s my solution. Its a little involved primarily because I cleaned the data I used. For example I turned height from a string, e.g. “5’11” into a number of inches.“71”. There’s a Data Exlplorer component which displays the statisctics for each column. The Rule Engine node at the end has a row by row comparison of the two data sets.
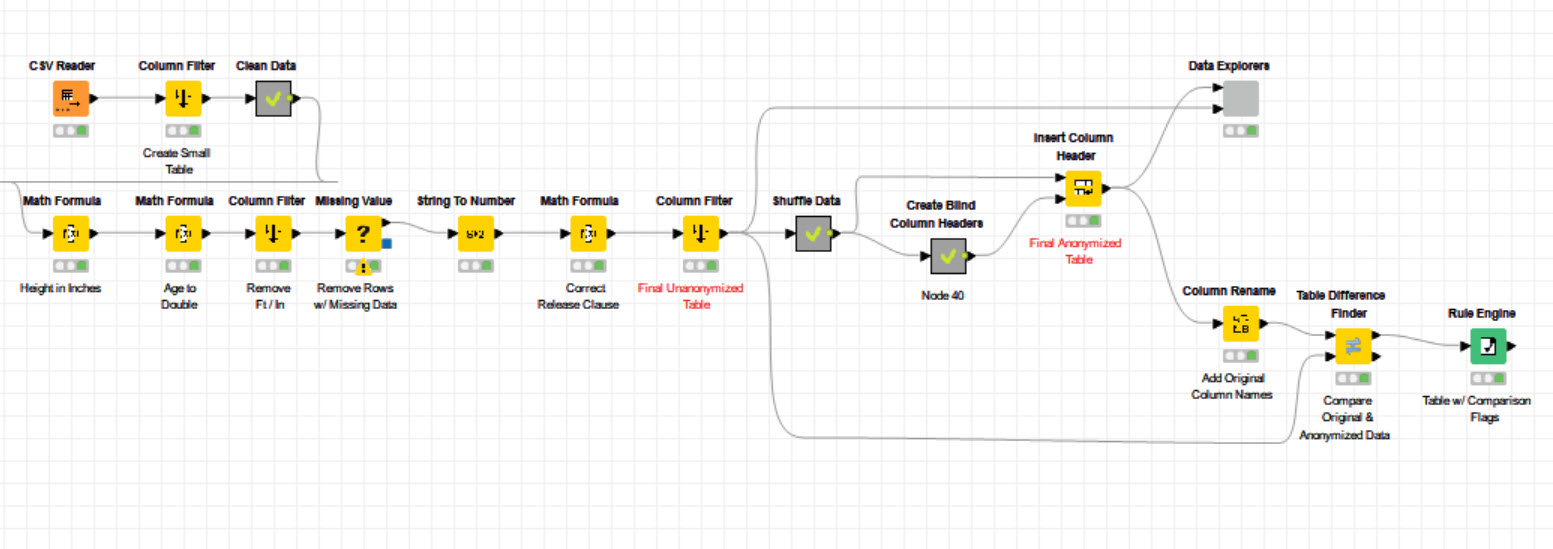
Here’s a Dropbox link to the workflow:
2 Likes
Just tried to explore …Trying to learn as i move…
2 Likes
Hi !
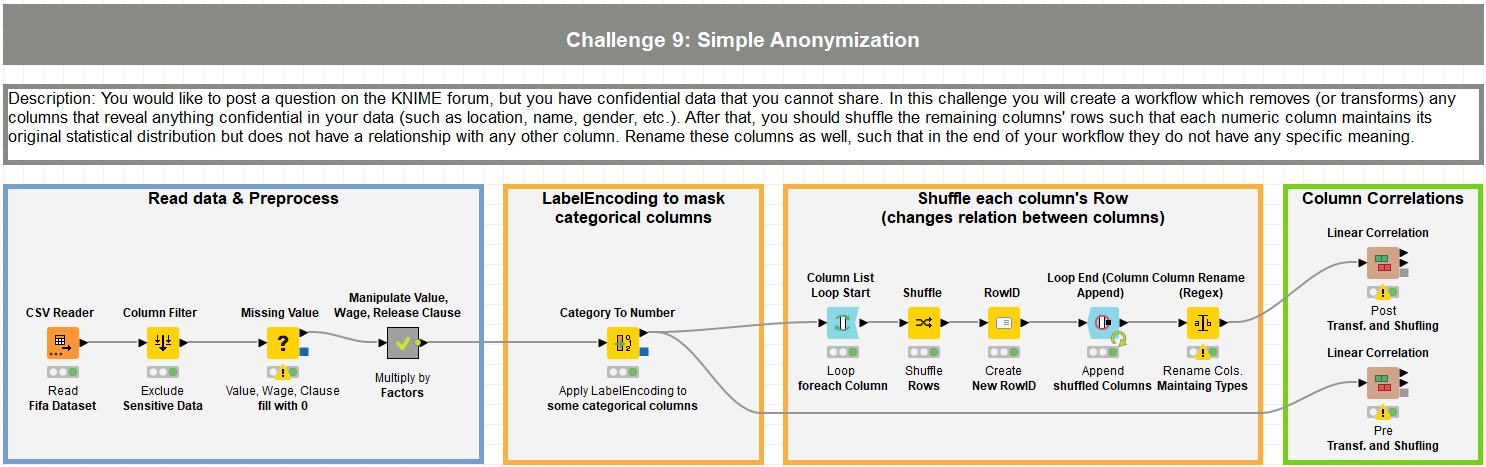
This is my approach for the challenge.
- Remove sensitive data
- Change the factor of some numerical columns
- Apply LabelEncoders to some categorial columns to mask its values
- Shuffle column’s rows
- Compare the correlations before and after the transformations
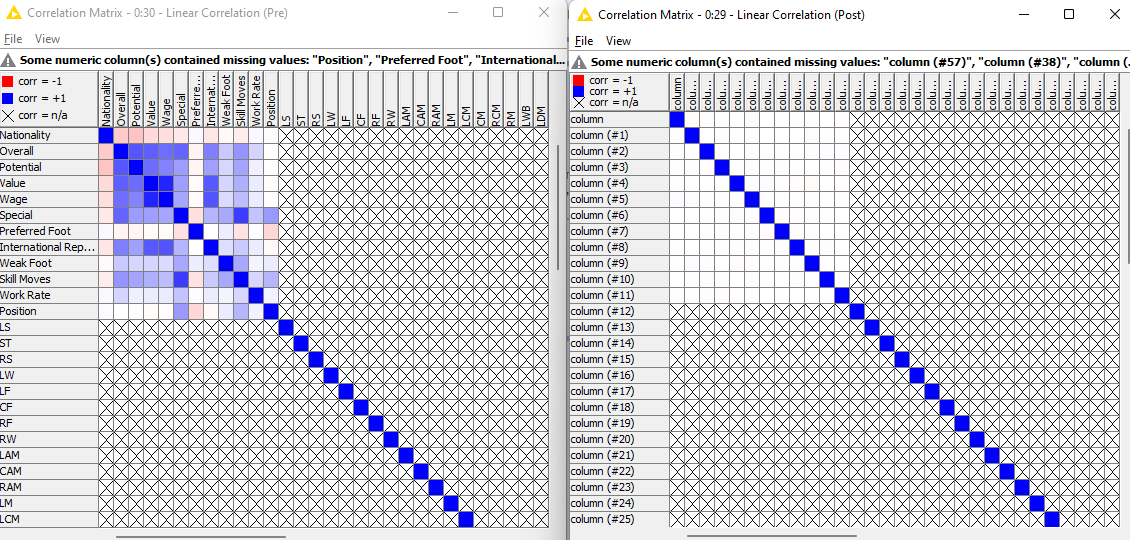
2 Likes
Hi @alinebessa ,
Without the name and photo, and the way that the shuffle is done, that is shuffling the rows of each column separately and independently, meaning that the relation of each column for a row is broken, it is quite impossible to de-anonymize.
I breathe soccer, and especially Club soccer, and to identify who a player is without a name, you could guess who the player is with just the Club and Jersey Number. Even without the Jersey Number, with the Nationality, Position, Preferred foot, Age, it’s possible to guess the player.
But with the shuffling being done per column separately, you don’t get any of the above relation anymore. After the shuffle, you can end up with Messi aged 24 being from Senegal playing for Club America as a GK with preferred foot Right, or Ronaldo aged 21 from Gabon playing for Fluminense as CB (the Portuguese Ronaldo that is, not the Brazilian one ![]() , but you get the point ). It’s almost impossible, if not completely impossible, to correlate the data.
, but you get the point ). It’s almost impossible, if not completely impossible, to correlate the data.
2 Likes
@bruno29a True that! Maybe I was being overly paranoid and hence a bit illogical. The shuffling is done independently per column after all… I’ll check if the random seeds are different per shuffling as well – this would perhaps make the anonymization safer, too.
1 Like
Hello everyone,
Here is my solution : JustKNIMEit_Challenge9_Anonymization_JeromeTreboux – KNIME Hub
I decided to keep the names and photos but I used the node anonymization on these two columns.
Enjoy your day!
Best
Jerome
2 Likes
Hi
here my solution : jKi-9 – KNIME Hub

2 Likes
Hi, everybody!
As usual on Tuesdays, the solution to our weekly challenge is out! ![]()
![]()
Hope to see you all tomorrow for challenge 10!
And in case you did not see the thread, we’re now giving badges to community members who participate in the challenges! ![]() So if you have participated in at least one challenge by now, you have already received one badge. Keep participating to receive further badges!
So if you have participated in at least one challenge by now, you have already received one badge. Keep participating to receive further badges!
3 Likes
I recently made a data masking exercise over large sets of data and decided to share my approach in the solution to this challenge.
What was done:
- Missing data is fixed.
- Irrelevant text columns filtered out.
- Names, Nationalities and Clubs were shuffled using python random module.
Why shuffling? I keeps the length of the string, which can be reusable in analytics. The data can still be grouped by Club and Nationality although it is almost unreadable. Nevertheless, short player names can be restored easily, especially by Brazilian football experts.
KnimeIT_9 – KNIME Hub
2 Likes
Thanks for sharing this!