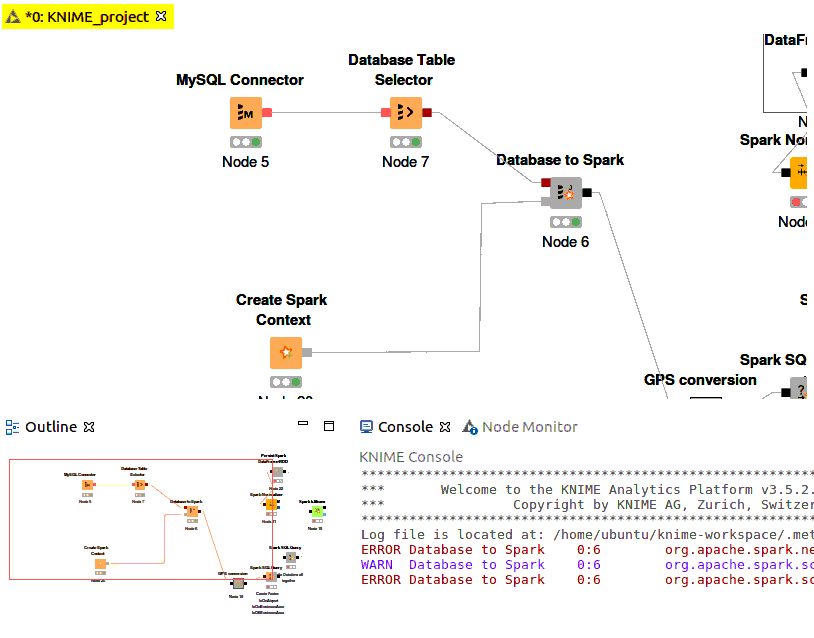
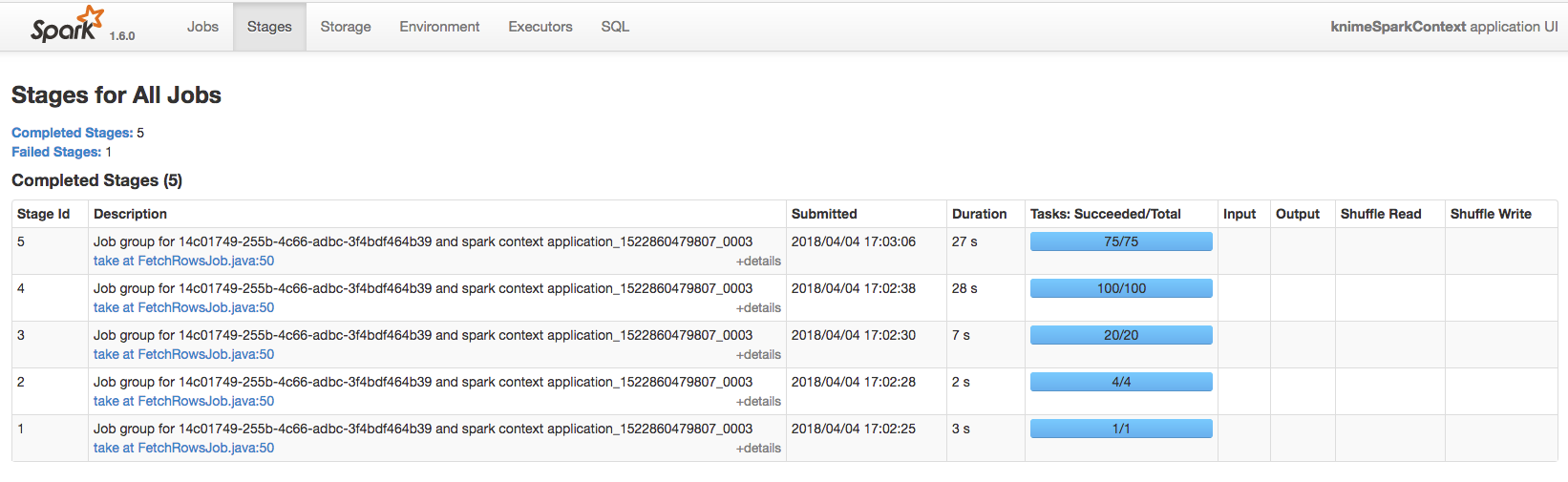
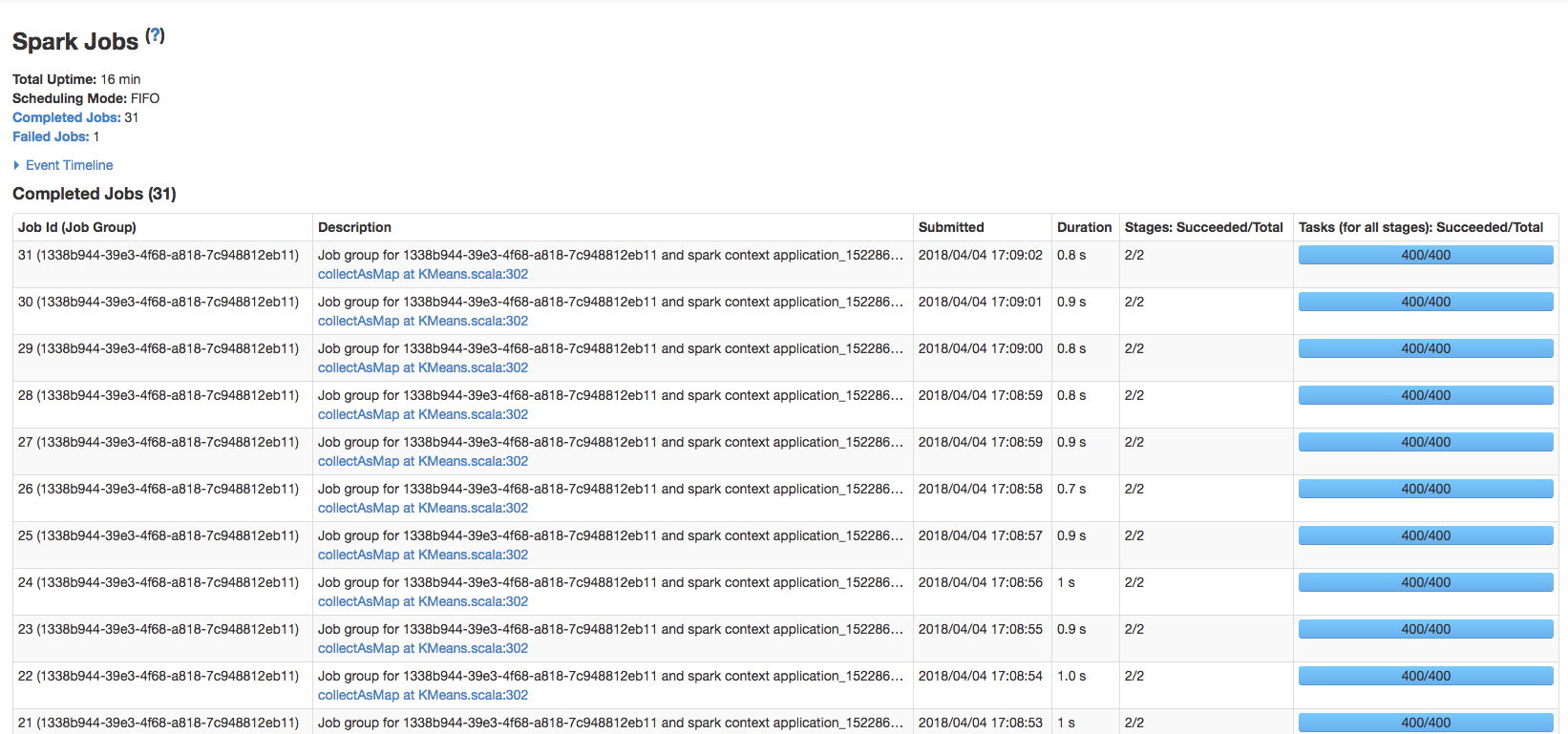
Hi,
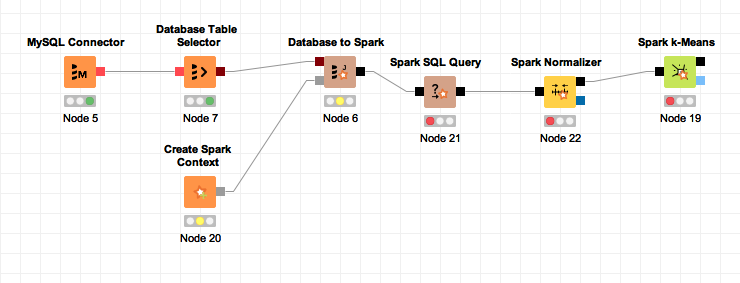
I’m not able to successfully execute the Spark k-means node, and also other kind of nodes like Spark normalizer. After several hours I decided to interrupt the execution of the knime node and analyze a little bit the situation. So, considering my scenario:
a CDH cluster made of 4 nodes, in which each node has the same specs of a t2.large amazon aws EC2 instance (2 vCPU, 8GB ram). Starting from this point which would be the approximately right execution time considering to pass as spark-job-server the execution of Spark k-means node with a volume of 50mln data (as in my case)?
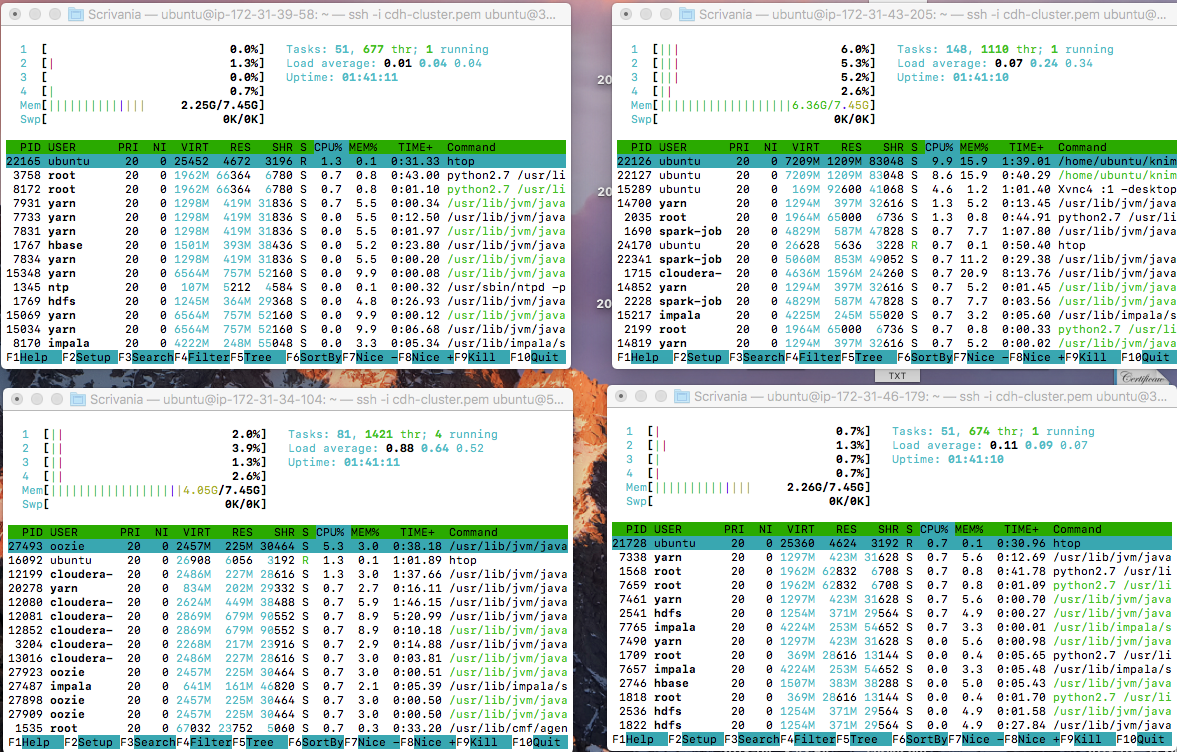
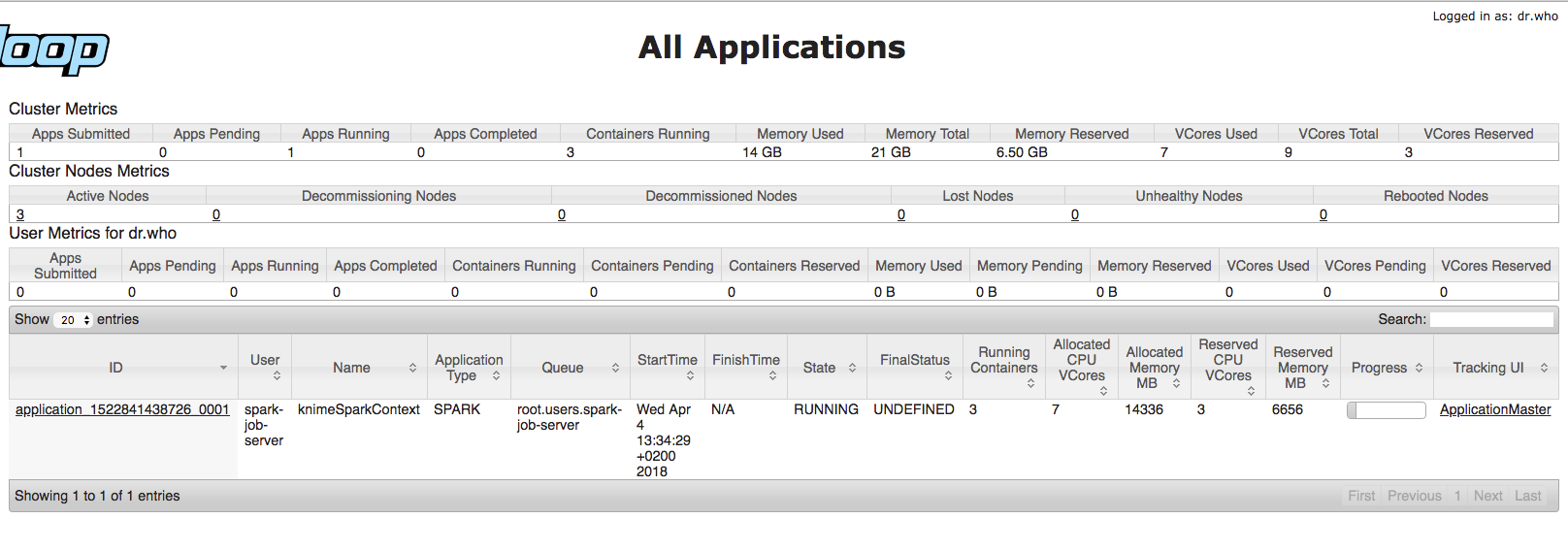
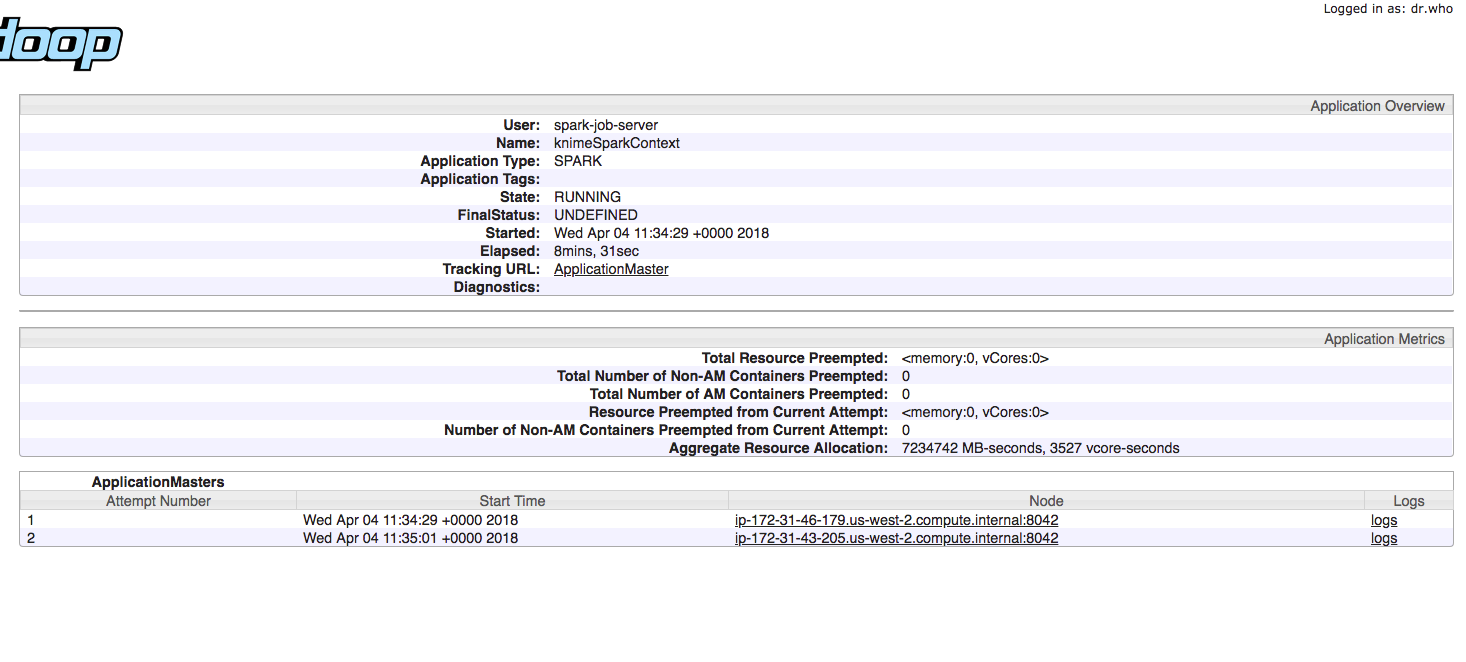
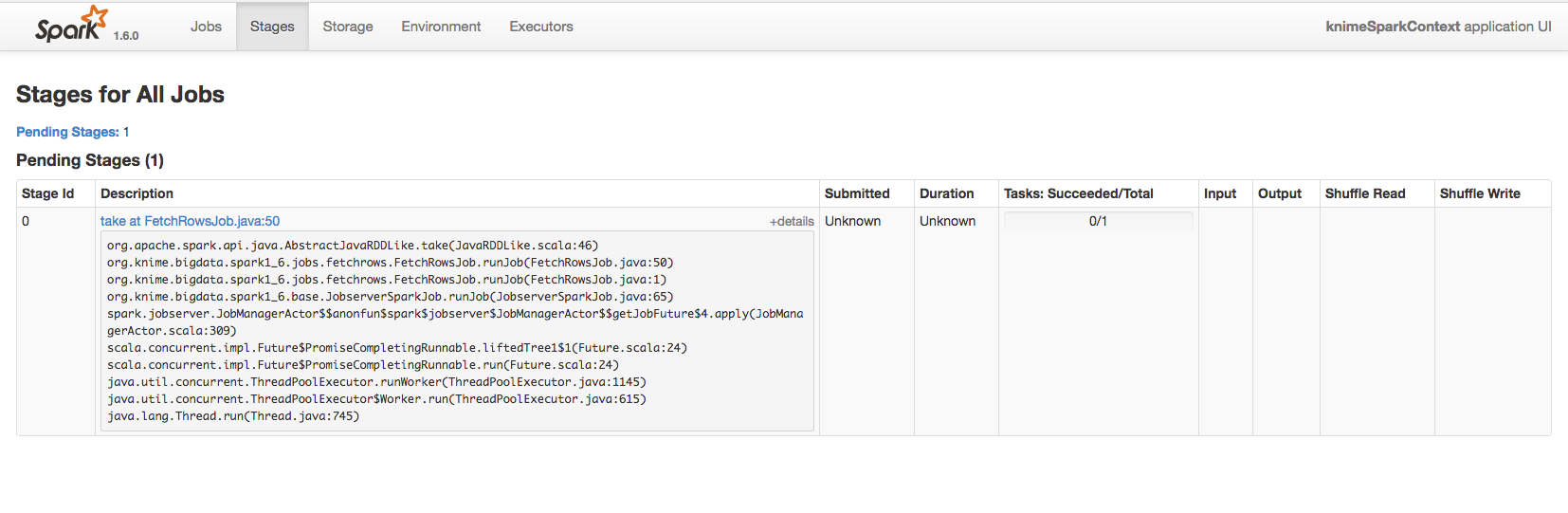
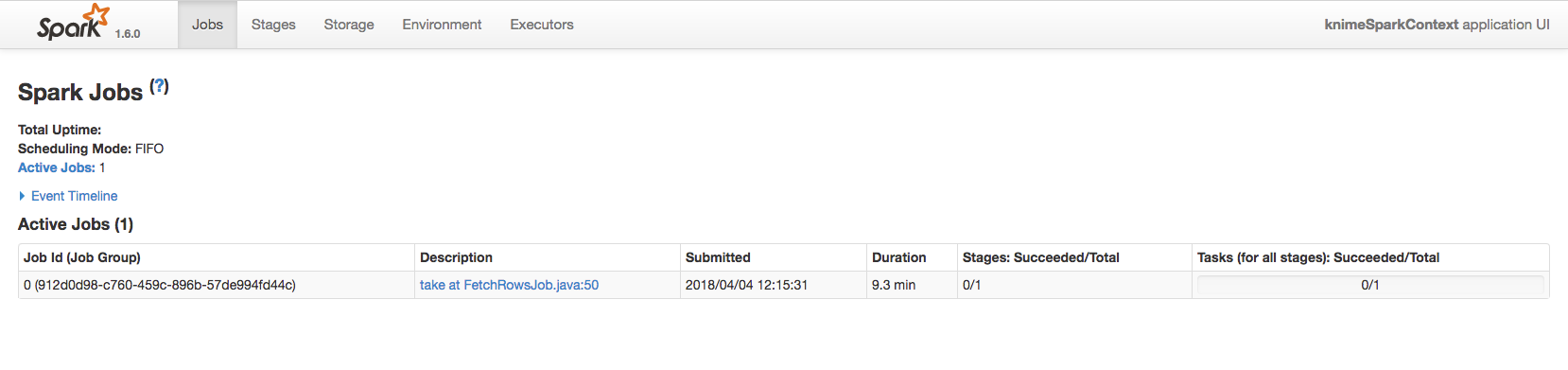
Cause actually using 4 instances for my CDH cluster I was expecting to consume much more memory/cpu resources and considerably reduce the entire execution time. But when I submit the the Spark K-Means Node operation using spark-job-server and YARN the consume of resources is pretty absent (as you can see from HTOP monitoring each machine within the Cluster when I submit this task with YARN):
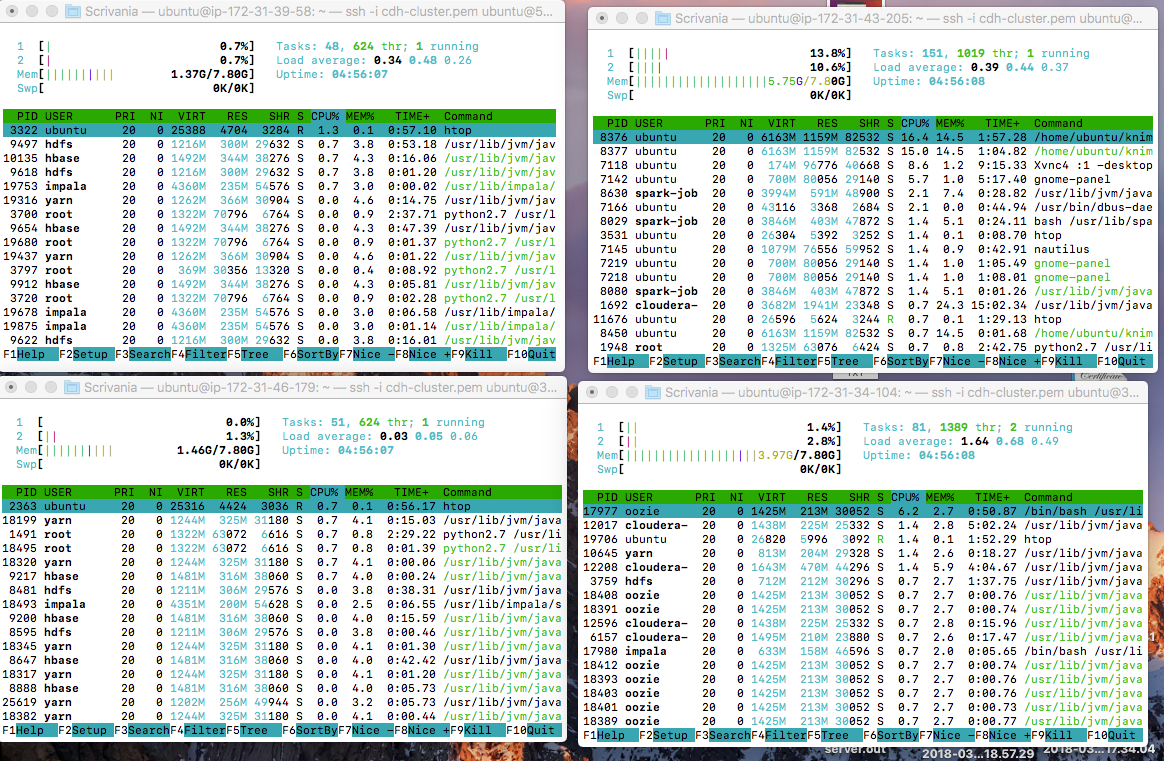

As you can see from the images above, the resources are pretty unused. And it also seems that the task is running over just 1 instance. Here’s my YARN tuning configuration:
- yarn.nodemanager.resource.cpu-vcores: 8
- yarn.nodemanager.resource.memory-mb: 5120mb
- yarn.scheduler.minimum-allocation-vcores: 1
- yarn-scheduler.maximum-allocation-vcores: 1
- yarn.scheduler.increment-allocation-vcores: 1
- yarn.scheduler.minimum-allocation-mb: 1024mb
- yarn.scheduler.maximum-allocation-mb: 8192mb
- yarn.scheduler.increment-allocation-mb: 512mb
During this period the Spark K-means node still doesn’t complete the task also after much several hours of execution. The same behaviour happens also if I put before the Spark K-means node the Spark normalizer node.
Probably I’m missing something, but I’m pretty sure that someone can clarify me about it. Also because the execution time of a normal K-means takes around 3/4 hours and with Spark nodes I’m expecting to have some tangible improvements as execution time.
Are there maybe any configurations that need to be applied in order to maximize the the use of the resources?
Thanks in advance,
~G